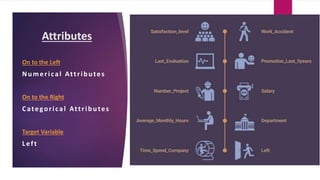
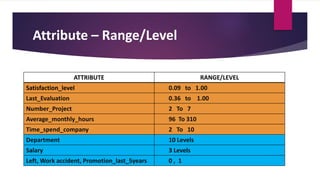
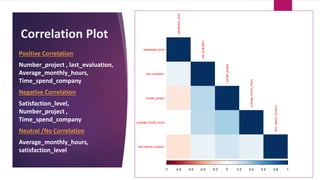
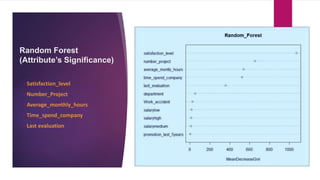
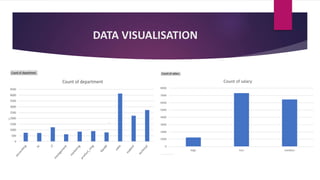
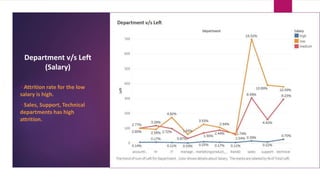
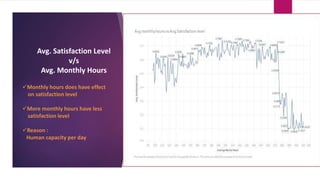
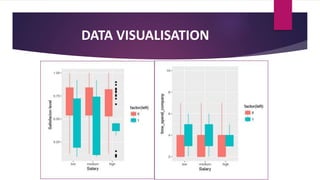
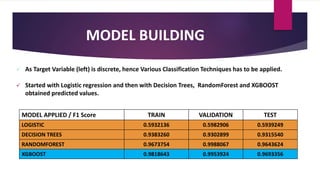
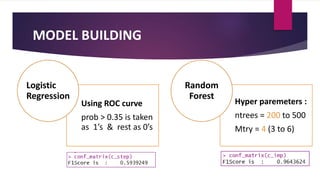
The document analyzes employee attrition in a leading organization, identifying key factors such as low satisfaction levels and high workload for experienced employees. It details a mixture of numerical and categorical data, applying various classification techniques including logistic regression, decision trees, random forest, and XGBoost to predict employee turnover. The analysis highlights high attrition rates in certain departments and suggests future enhancements in feature engineering and model tuning for improved predictions.



















































![IBM-HR-Analytics-Employee-Attrition-and-Performance[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ibm-hr-analytics-employee-attrition-and-performance1-251018181740-7e1d1f2b-thumbnail.jpg?width=640&height=640&fit=bounds)




























