Download to read offline




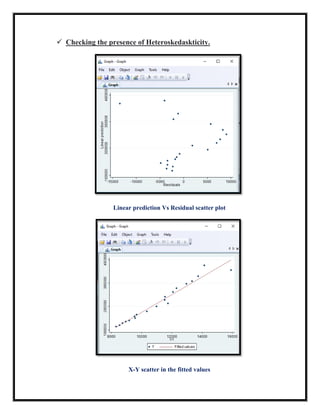




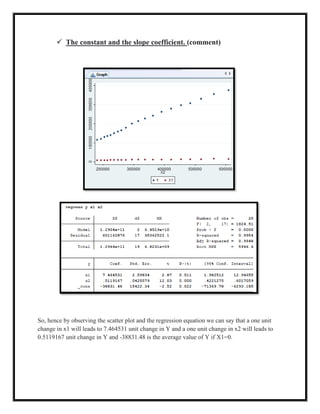
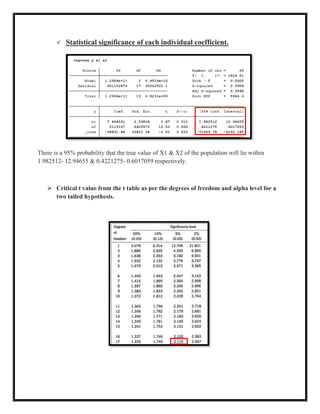


The document presents an applied econometric analysis utilizing a multiple regression model with various assessments, including heteroskedasticity, autocorrelation, and multicollinearity within the data set. The regression analysis indicates that y explains 99% of the variation from x1 and x2, with both predictors showing statistical significance. The presence of autocorrelation and multicollinearity is noted, leading to recommendations for robust standard errors and specific tests to address these issues.









































































