Downloaded 62 times






![Files on disk
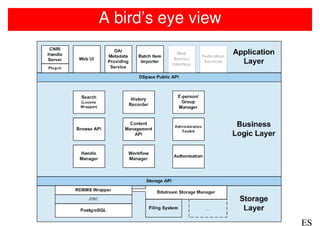
• Files stored in the ‘asset store’
• Each bitstream has an internal id; a large integer derived from the
date of submission and checksum
o e.g. 908735856294756292618068267495783
• Files are stored in the directory ab/dc/ef, where abcdef are the first
6 characters of the internal id
o e.g 90/87/35
• Files are stored with the internal id as the filename
• All actual information about the file is in the "bitstream" table in the
database, including internal id.
908735856294756292618068267495783 ->
/dspace/[assetstore]/90/87/35/908735856294756292618068267495783
ES](https://image.slidesharecdn.com/dspaceunderthehood-111130133739-phpapp01/85/DSpace-Under-the-Hood-8-320.jpg)

![Lucene search indexes
• Maintained outside of the database
• Contains the search index
• Very fast for full text searching
• Stop words and stemming
• A cached copy
• Can be re-built or updated from the database
• [dspace]/bin/dspace index-update
MR](https://image.slidesharecdn.com/dspaceunderthehood-111130133739-phpapp01/85/DSpace-Under-the-Hood-10-320.jpg)





![JSPUI styling options
• All JSPs: dspace-jspui/dspace-
jspui/webapp/src/main/webapp
• Main layout: [jsps]/layout and [jsps]/styles.css.jsp
• Page localisations should go in dspace/modules/jspui
• Caveat: The more changes you make, the harder it is to upgrade
MR](https://image.slidesharecdn.com/dspaceunderthehood-111130133739-phpapp01/85/DSpace-Under-the-Hood-16-320.jpg)


![Error messages
• Help – an error message!
• To help you, we need to know exactly what went
wrong
• The easiest way to do this, is with a ‘stack trace’
2008-09-18 15 08:13
: ,263 INFO org .dspace.app.xmlu .u i s Authent t
i tl . ica ionUt l @ [EMAIL
i
PR OTECTED] :
sess ion_id=F1FB96AF6FA3464C393A3366621534A4: ip_addr=139.147.66.108:
l in type=exp i i java lang l in rExcept
og : l ct . .Nu lPo te ion
at
org .dspace.au hent te
t ica .LDAPHierarch lAuthent t .getSpec lGroups(LDAPHie
ica ica ion ia
ra ica
rch lAuthent t . :144)
ica ion java
at
org .dspace.au hent te
t ica .Authent tica ionManager tSpec l
.ge ia Groups(Authentca ionMa
i t
nager java
. :308)
at o .dspace.app.xmlu .u i s Authent t
rg i tl . ica ionUt llog (Authent t
i. In ica ionUtlja
i. va:222)
RJ](https://image.slidesharecdn.com/dspaceunderthehood-111130133739-phpapp01/85/DSpace-Under-the-Hood-19-320.jpg)
![Getting help from dspace-tech
To: dspace- tech @l ts.
is sourceforge.net
Subjec : Erro w th XYZ when ABC happens
t r i
Dear dspace-tech,
[Descr t on o your prob
ip i f lem]
[Stack t ace and/or l fle ex r ]
r og i t acts
[DSpace ve ion
rs ]
[Env ronment OS favour
i : l ]
[Any other relevant deta l ]
is
Please he !
lp
Richard
MR](https://image.slidesharecdn.com/dspaceunderthehood-111130133739-phpapp01/85/DSpace-Under-the-Hood-20-320.jpg)
























The document provides an overview of how DSpace works, focusing on its architecture, community development process, and user roles. It includes information about data structures, configuration, authentication, and community engagement, along with contact details for key personnel. It emphasizes the collaborative nature of DSpace's development and operational processes while offering guidelines for contributors.

















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











