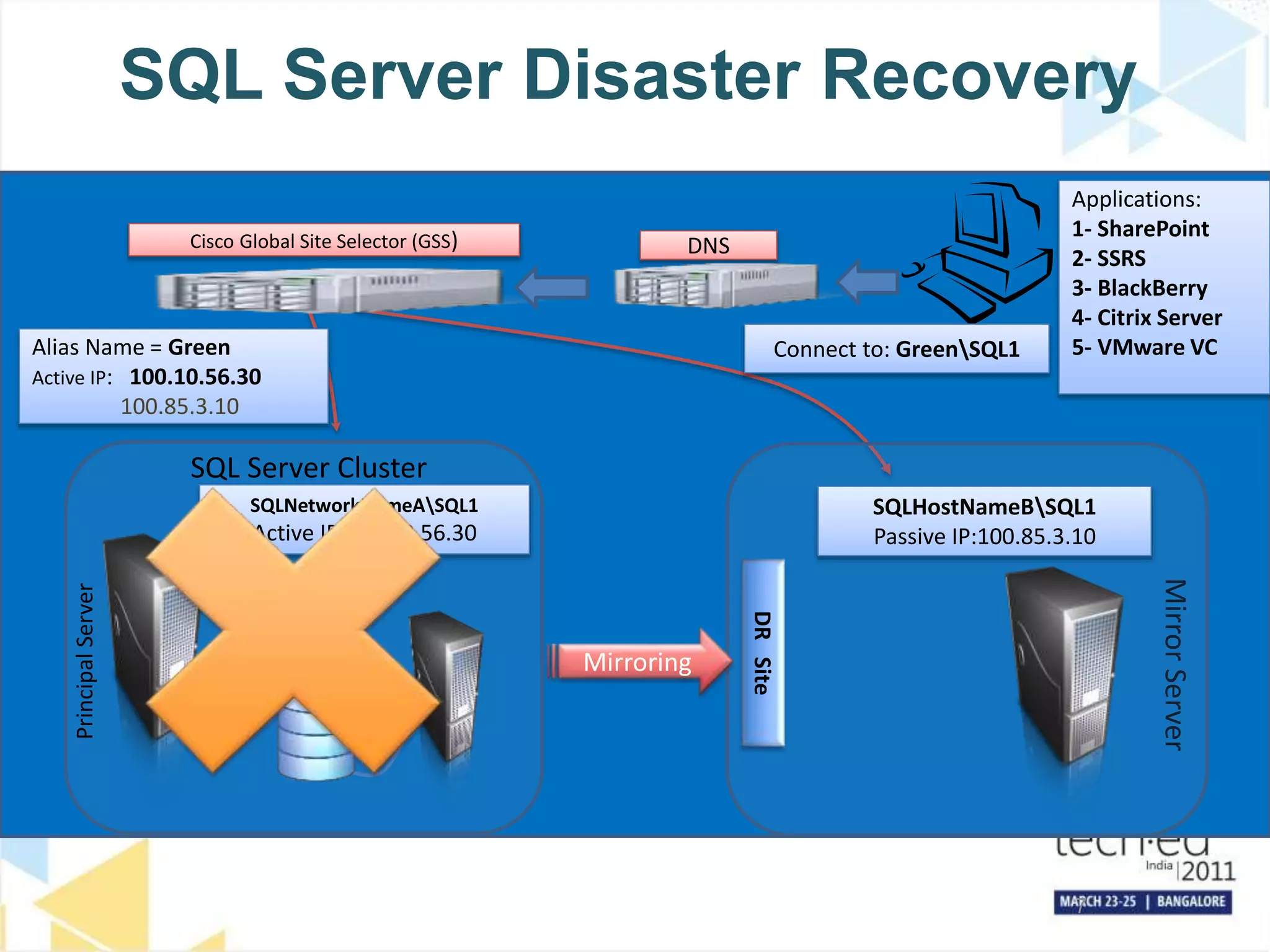
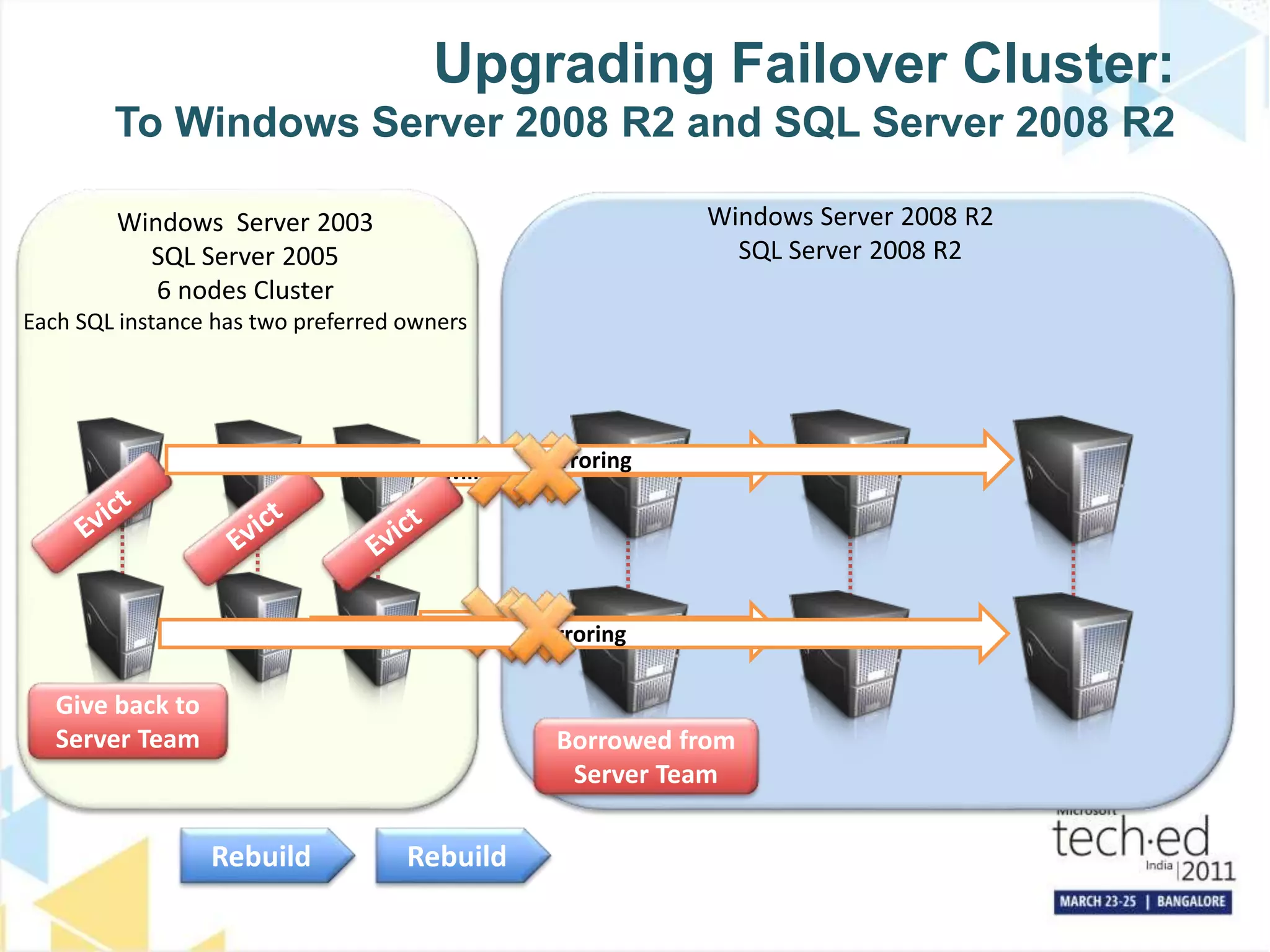
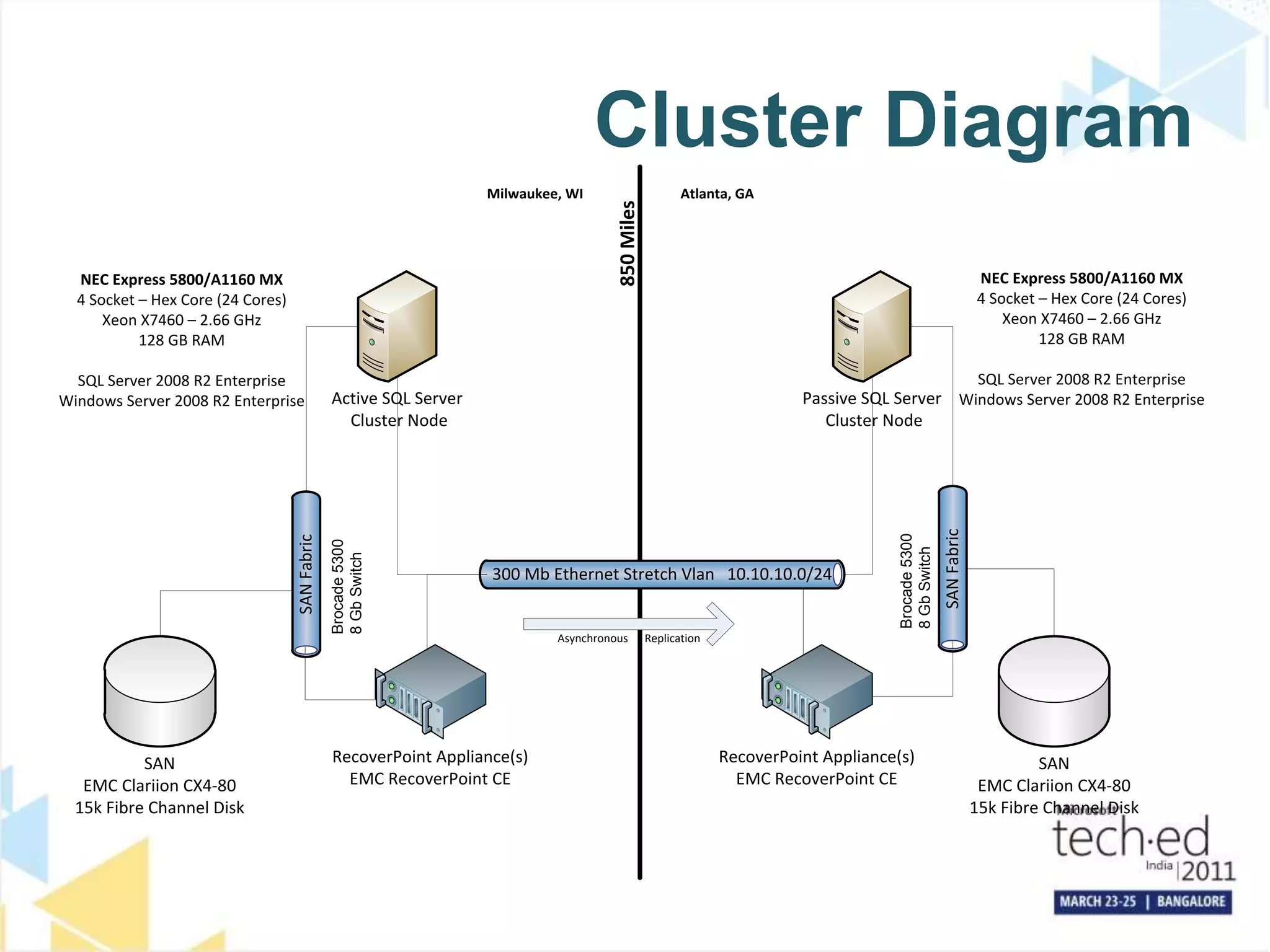
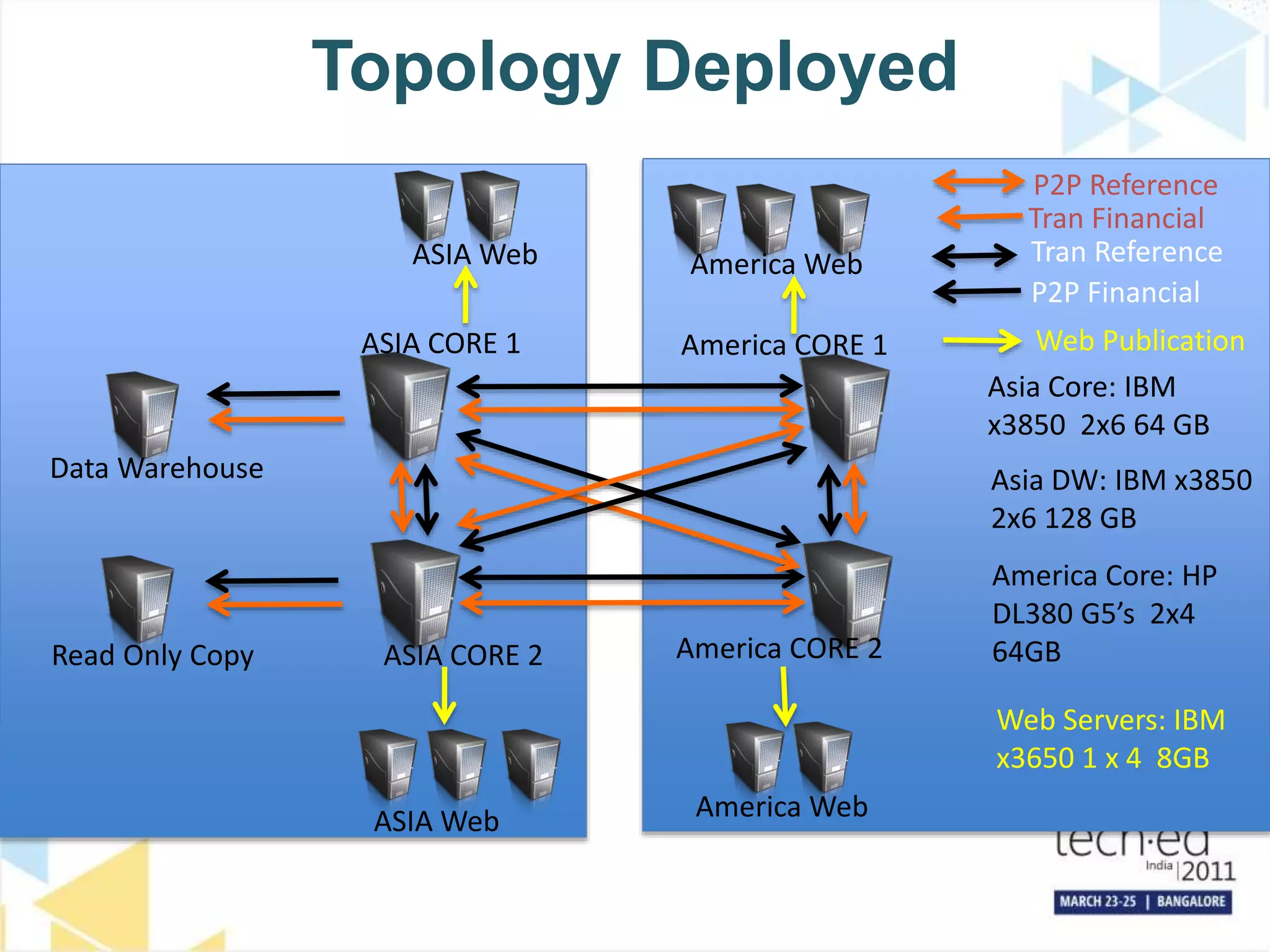
The document discusses several high availability and disaster recovery options for SQL Server including failover clustering, database mirroring, log shipping, and replication. It provides examples of how different companies have implemented these technologies depending on their requirements. Key factors that influence architecture choices are downtime tolerance, deployment of technologies, and operational procedures. The document also covers SQL Server upgrade processes and how to move databases to a new datacenter while maintaining high availability.