Downloaded 21 times












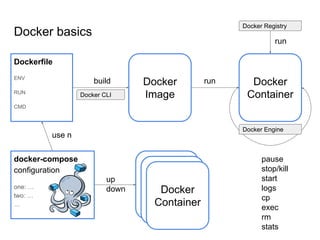
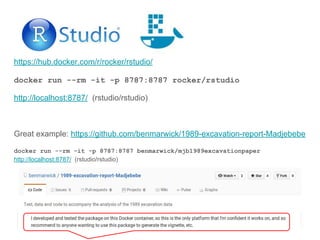

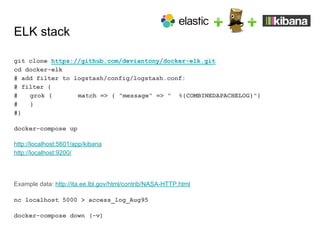
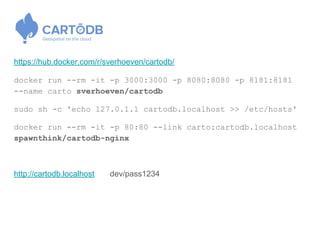
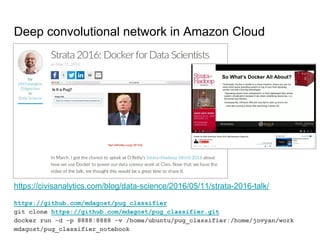
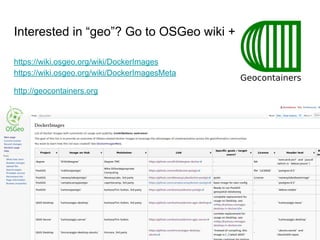



The document discusses the benefits and fundamentals of using Docker for data science, highlighting isolation, portability, and repeatability as key motivations. It outlines various Docker concepts, commands, and practical applications, including examples with RStudio and Jupyter Notebooks. Additionally, it emphasizes the importance of reproducibility and collaboration in data science workflows enabled by containerization.



























































































