Download to read offline




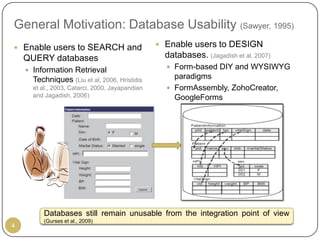



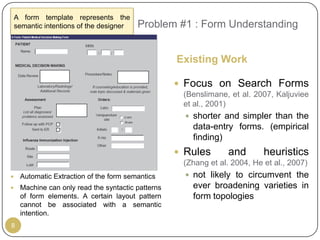

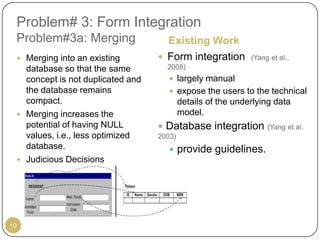



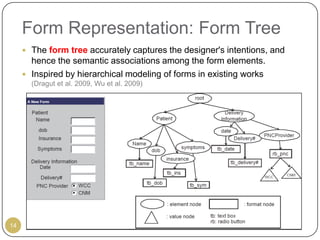
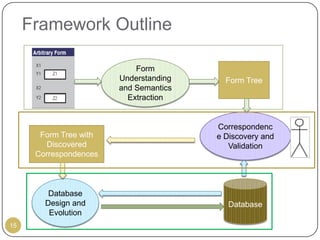
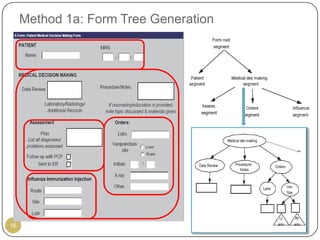
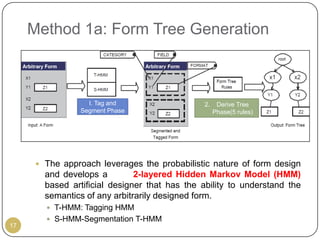
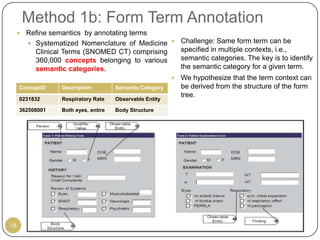
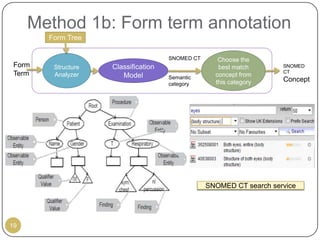
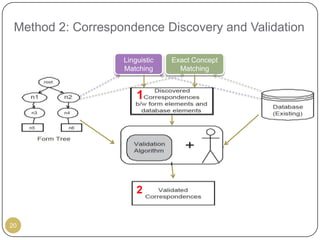
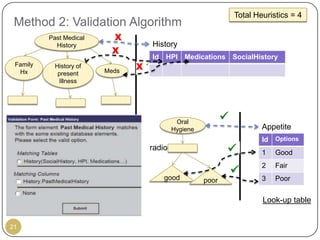
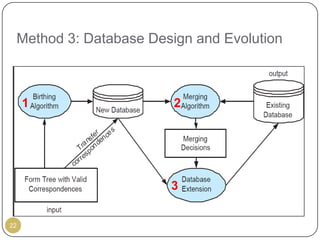
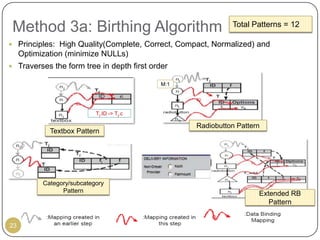
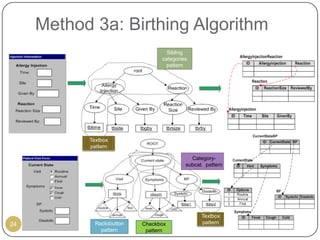
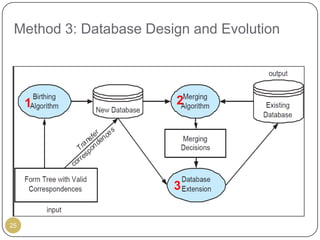
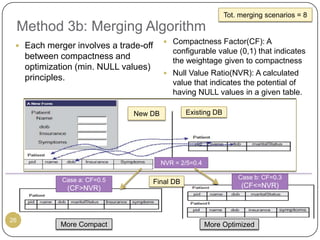

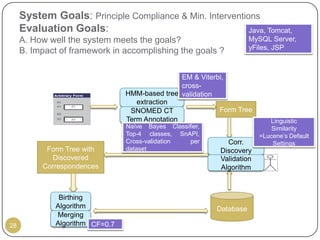

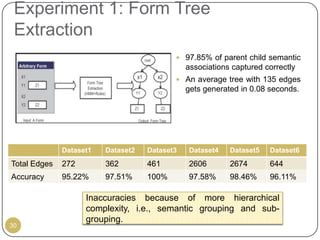
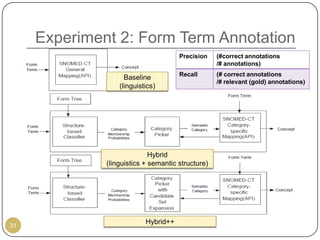
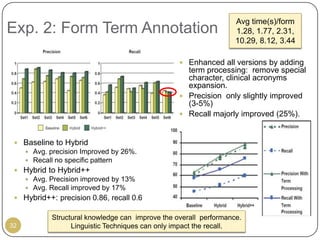
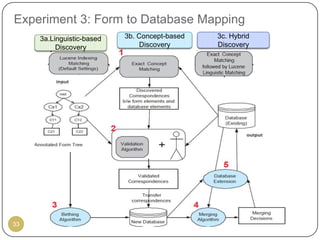
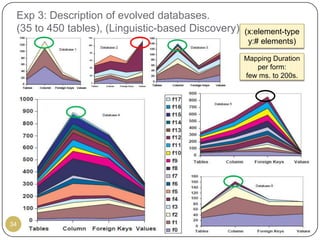
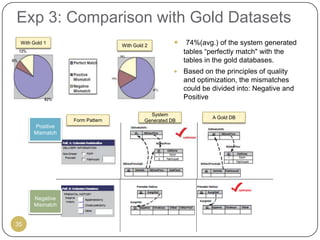

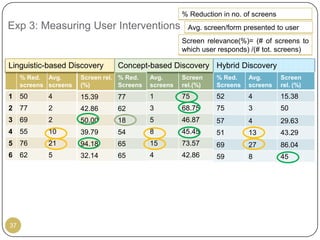
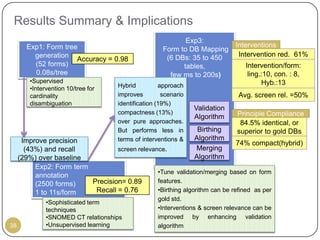


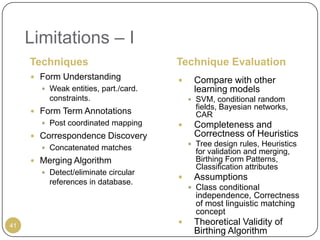





This document outlines Ritu Khare's dissertation presentation on mapping user-designed forms to relational databases. The presentation covers the motivation for the research, problems in existing approaches, and proposed solutions. Specifically, the presentation discusses understanding form semantics, discovering correspondences between forms and databases, and integrating forms into databases while maintaining properties like completeness, correctness, and normalization. The goal is to evolve databases from user forms with minimal user intervention.

















































































