Download to read offline











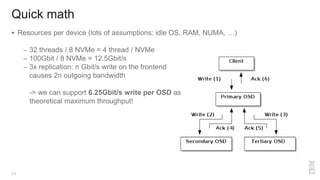



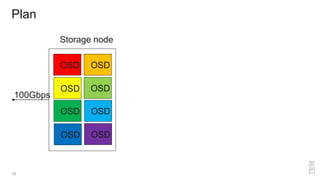
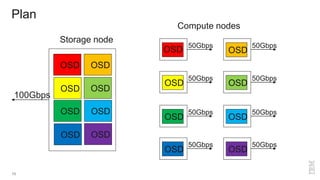
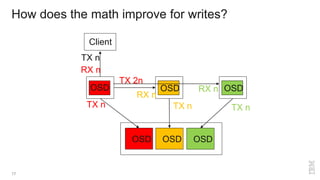

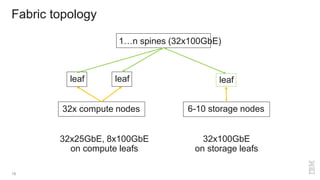


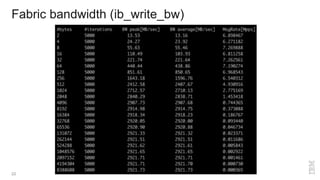
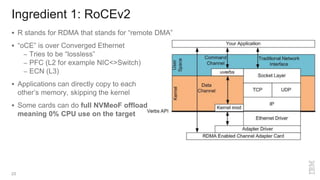

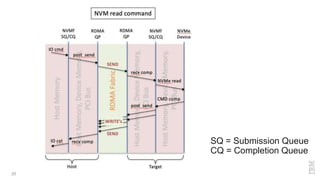
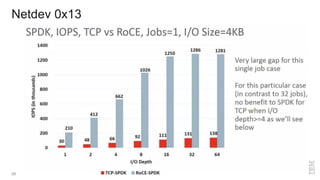
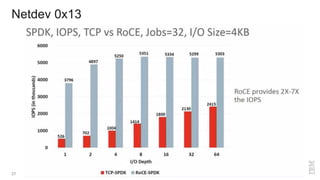
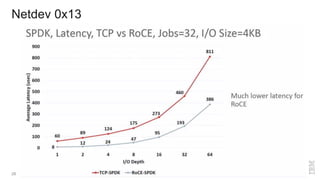

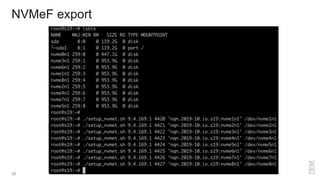
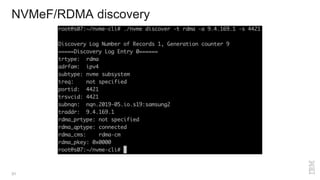
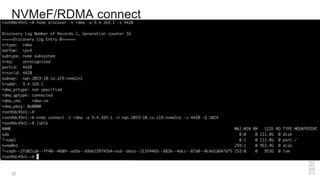



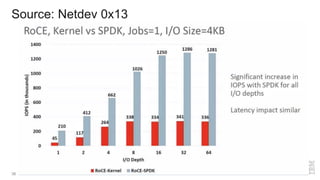
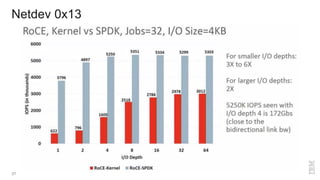



Zoltan Arnold Nagy from IBM Research Zurich discusses the disaggregation of Ceph using NVMe over Fabrics (NVMeOF) technology and the infrastructure of their research lab, which includes significant computational and storage capabilities. The document highlights various configurations, motivations for upgrades, and performance measurements of their NVMe clusters. Additionally, it touches on future improvements and references to external sources related to Ceph and NVMeOF technologies.



































































