Downloaded 28 times


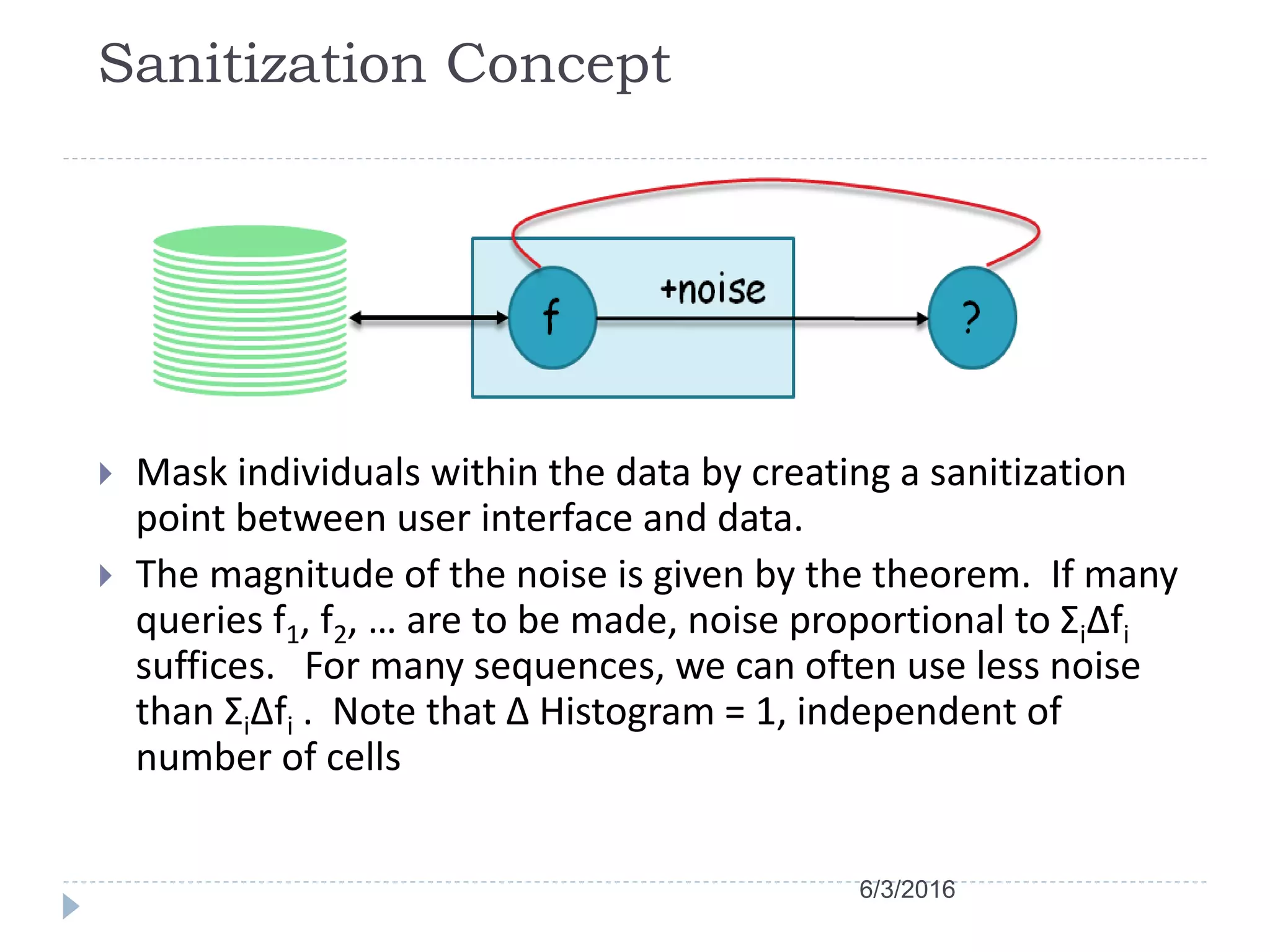

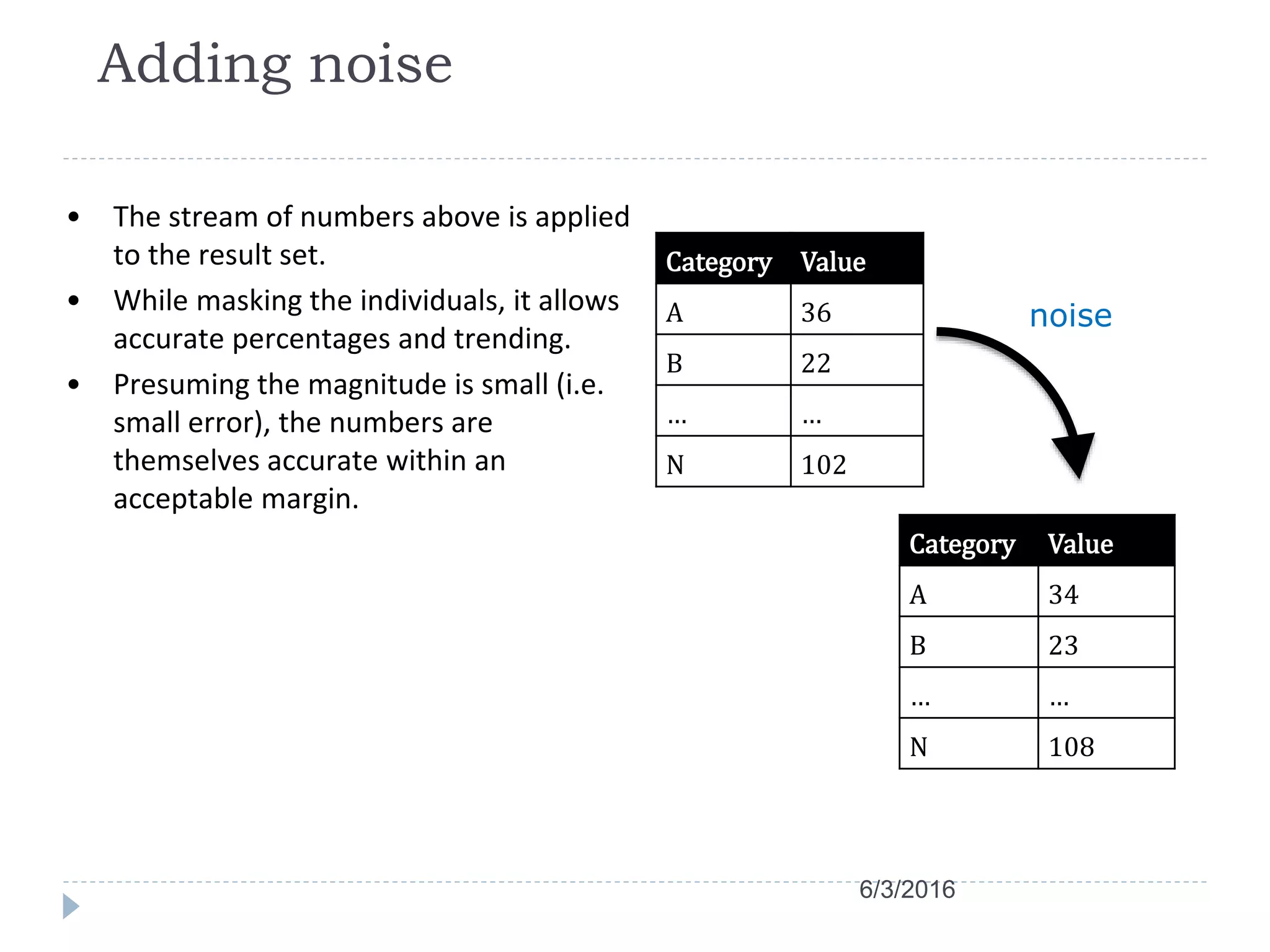

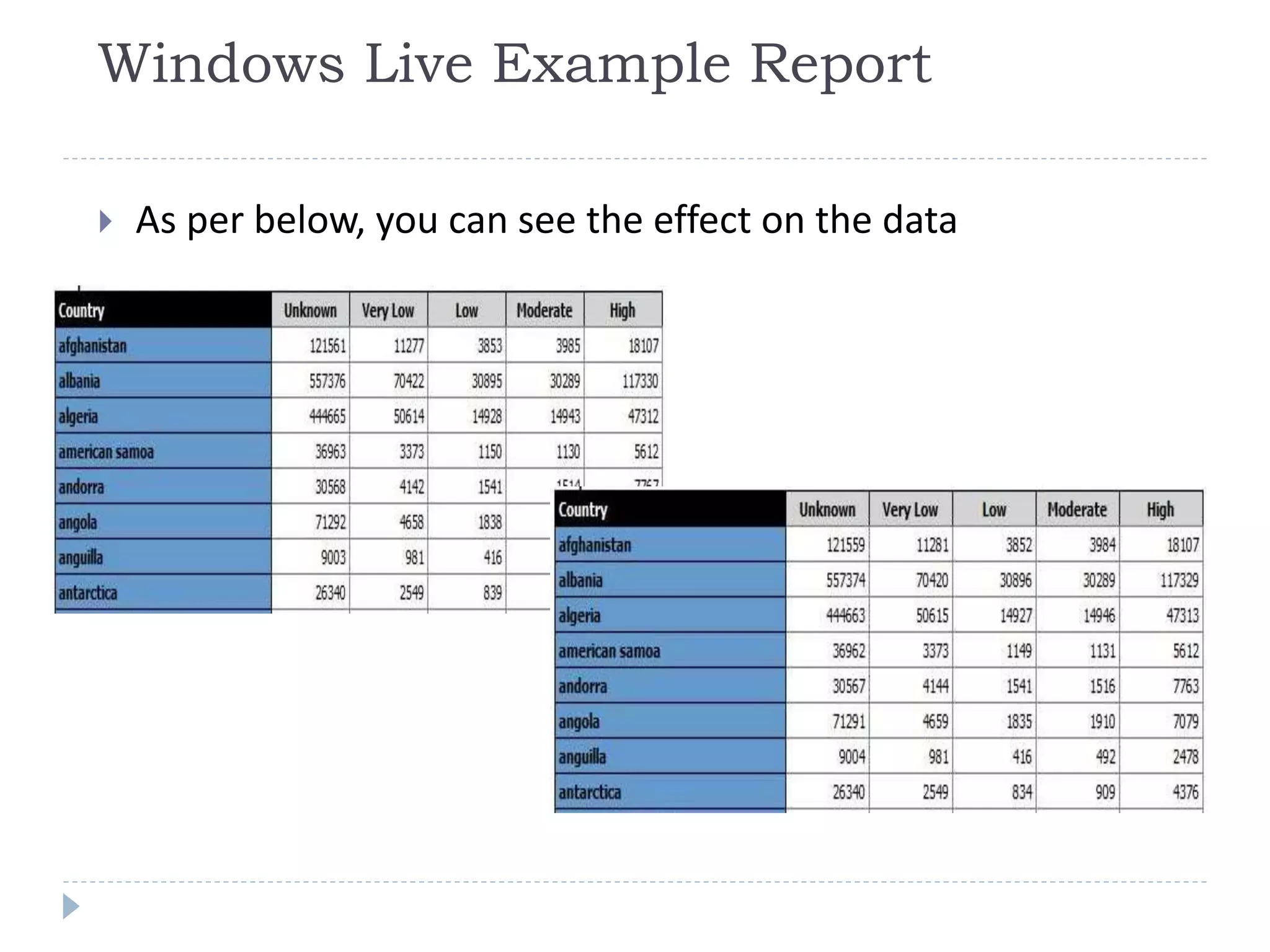















This document discusses case studies using differential privacy to analyze sensitive data. It describes analyzing Windows Live user data to study web analytics and customer churn. Clinical researchers' perspectives on differential privacy were also examined. Researchers wanted unaffected statistics and the ability to access original data if needed. Future collaboration with OHSU aims to develop a healthcare template for applying differential privacy.






























![Differential privacy without sensitivity [NIPS2016読み会資料]](https://cdn.slidesharecdn.com/ss_thumbnails/nipsyomi2016slideshare-170122091905-thumbnail.jpg?width=640&height=640&fit=bounds)





































![Ensuring compliance of patient data with big data and bi [bdii 301-m] - (4078)](https://cdn.slidesharecdn.com/ss_thumbnails/ensuringcomplianceofpatientdatawithbigdataandbibdii-301-m-4078-130430231240-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)








