Downloaded 30 times


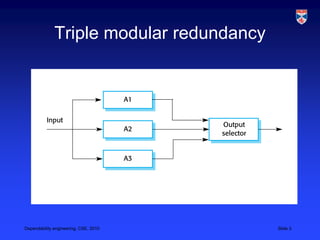

























The document discusses techniques for achieving dependable software systems through fault tolerance. It describes hardware-based triple modular redundancy and software-based N-version programming. It also discusses challenges with achieving true design diversity and problems that can arise from specification errors. The document concludes with guidelines for dependable programming practices such as limiting information visibility, checking inputs, using exception handling, avoiding error-prone constructs, including restart capabilities and timeouts.
































































































