Download to read offline












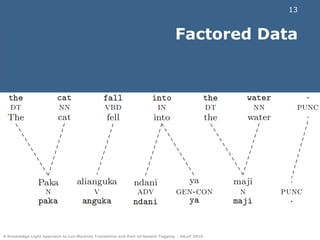



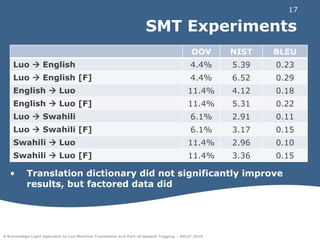
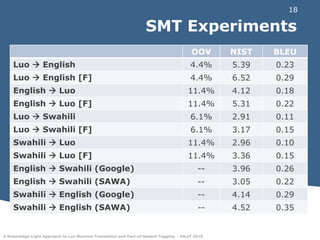



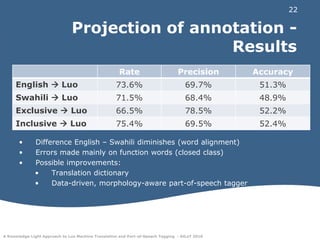





This document discusses experiments in machine translation and part-of-speech tagging for the Luo language using a small parallel corpus containing English, Swahili, and Luo text from the Bible. Machine translation systems were built using the Moses toolkit that achieved modest BLEU and NIST scores. Part-of-speech tags were projected from English and Swahili onto Luo text using word alignments, with errors mainly on function words. The results provide a starting point for natural language processing in Luo despite it being a resource-scarce language.











































































































