





































![Dictionary Definition of “set”set /sɛt/ Show Spelled [set] Show IPA verb, set, set·ting, noun, adjective, interjection –verb (used with object) 1. to put (something or someone) in a particular place: to set a vase on a table. 2. to place in a particular position or posture: Set thebaby on his feet. 3. to place in some relation to something or someone: We set a supervisor over the new workers. 4. to put into some condition: to set a house on fire. 5. to put or apply: to set fire to a house. 6. to put in the proper position: to set a chair back on its feet. 7. to put in the proper or desired order or condition for use: to set a trap. 8. to distribute or arrange china, silver, etc., for use on (a table): to set the table for dinner. 9. to place (the hair, especially when wet) on rollers, in clips, or the like, so that the hair will assume a particular style. 10. to put (a price or value) upon something: He set $7500 as the right amount for the car. The teacher sets a high value on neatness. 11. to fix the value of at a certain amount or rate; value: He set the car at $500. She sets neatness at a high value. 12. to post, station, or appoint for the purpose of performing some duty: to set spies on a person. 13. to determine or fix definitely: to set a time limit. 14. to resolve or decide upon: to set a wedding date. 15. to cause to pass into a given state or condition: to set one's mind at rest; to set a prisoner free. 16. to direct or settle resolutely or wishfully: to set one's mind to a task. 17. to present as a model; place before others as a standard: to set a good example. 18. to establish for others to follow: to set a fast pace. 19. to prescribe or assign, as a task. 20. to adjust (a mechanism) so as to control its performance. 21. to adjust the hands of (a clock or watch) according to a certain standard: I always set my watch by the clock in the library.](https://image.slidesharecdn.com/nlpandirv2-110330112801-phpapp01/75/The-Role-of-Natural-Language-Processing-in-Information-Retrieval-46-2048.jpg)


















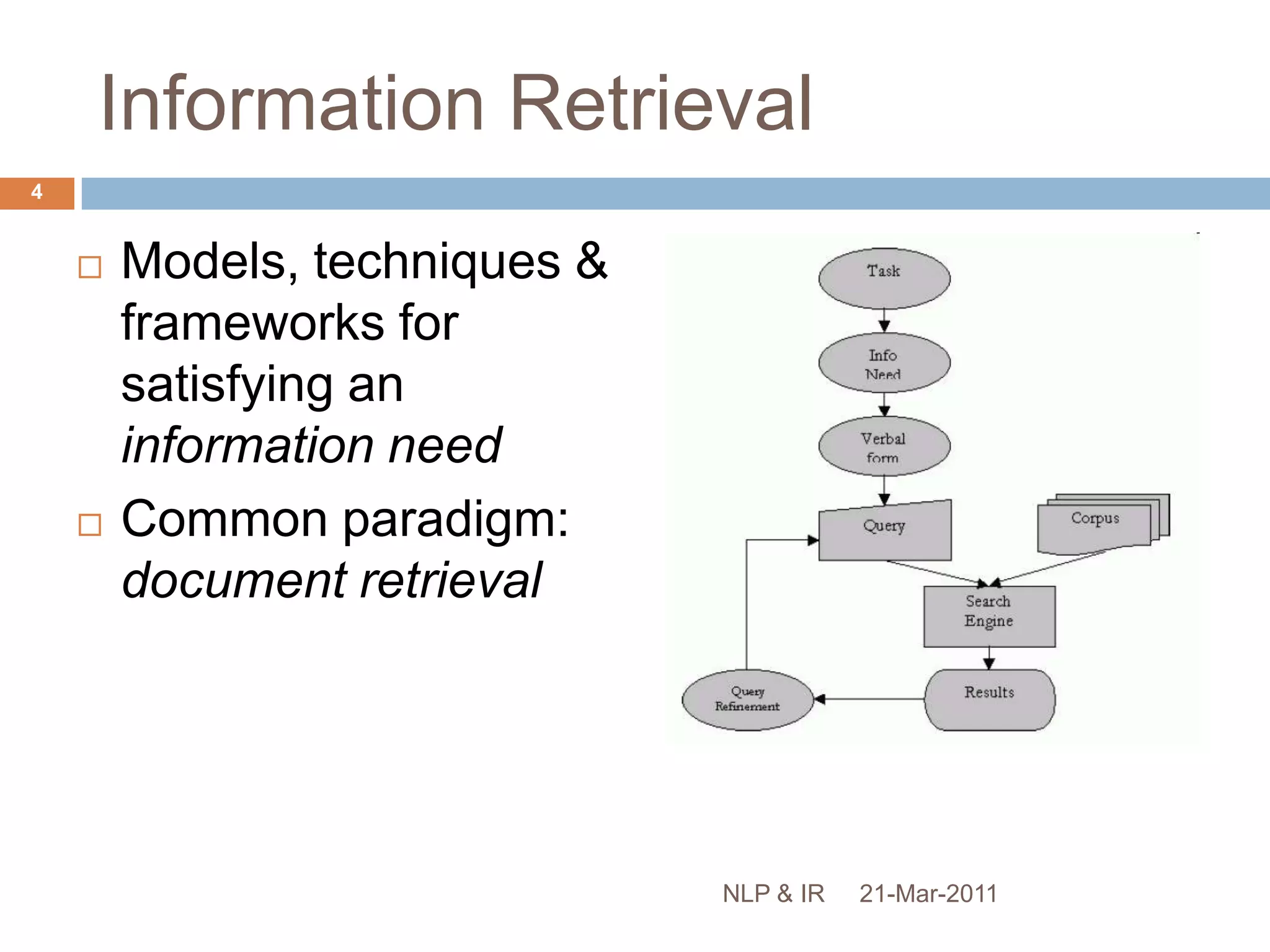
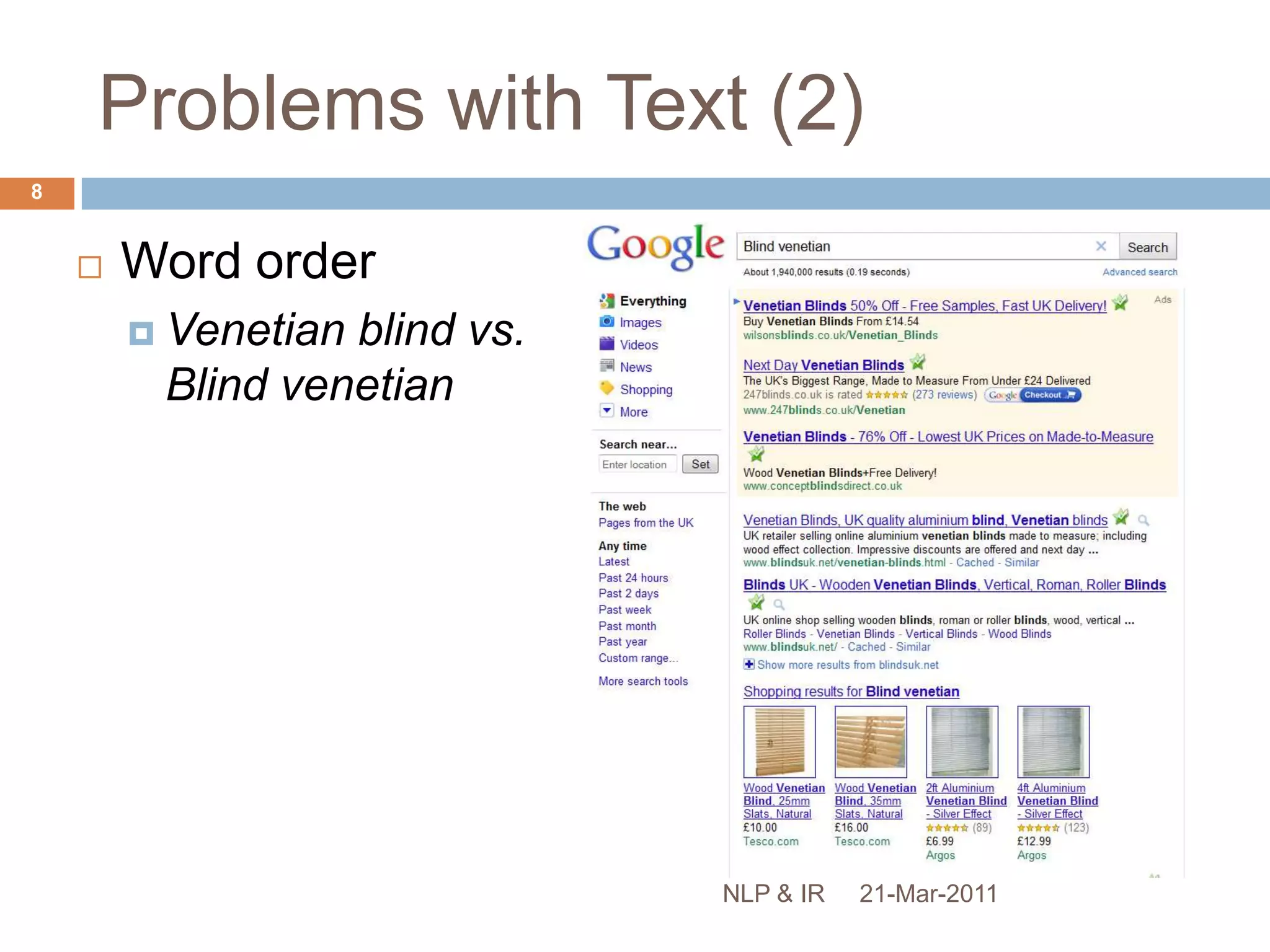
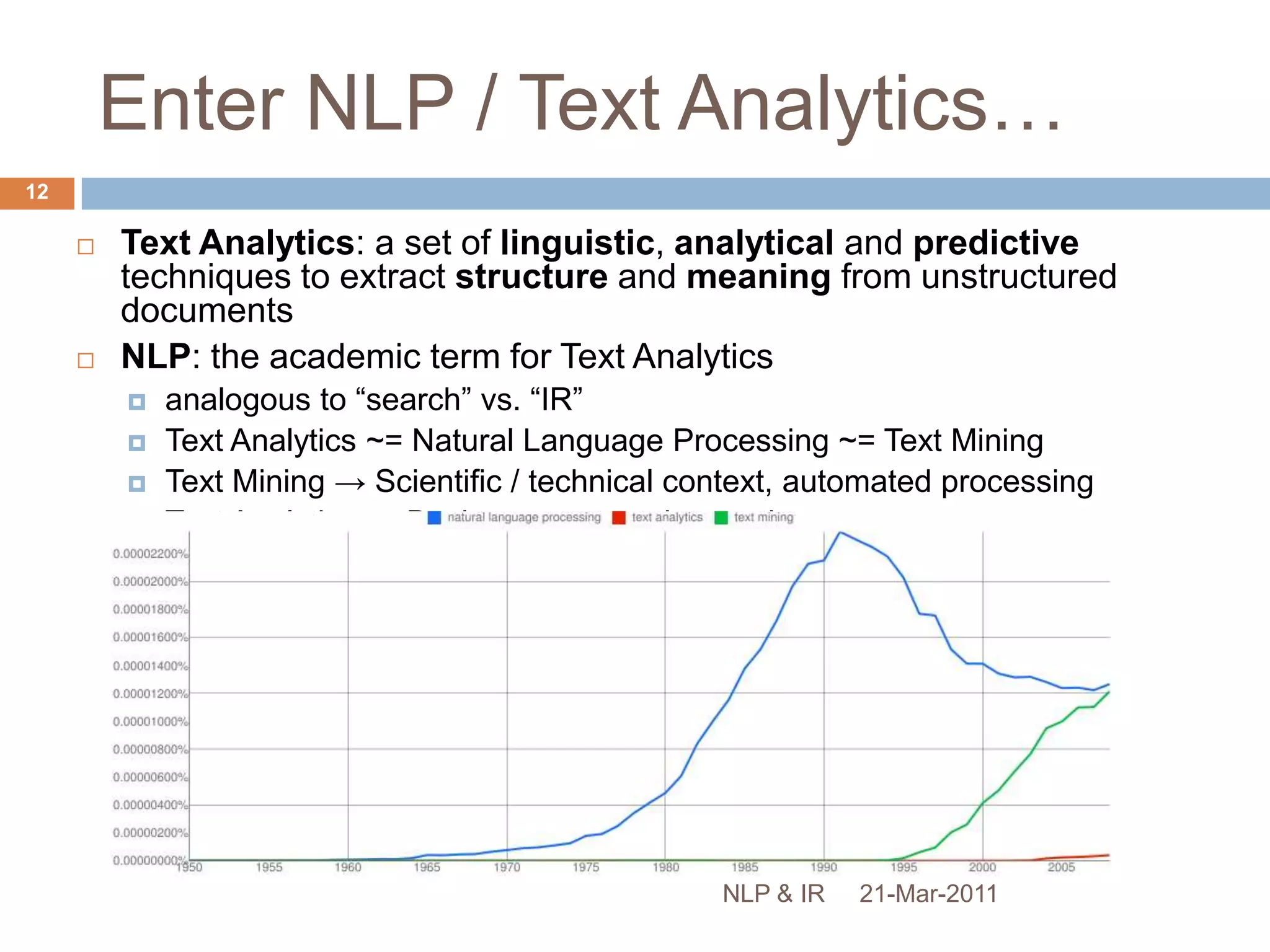
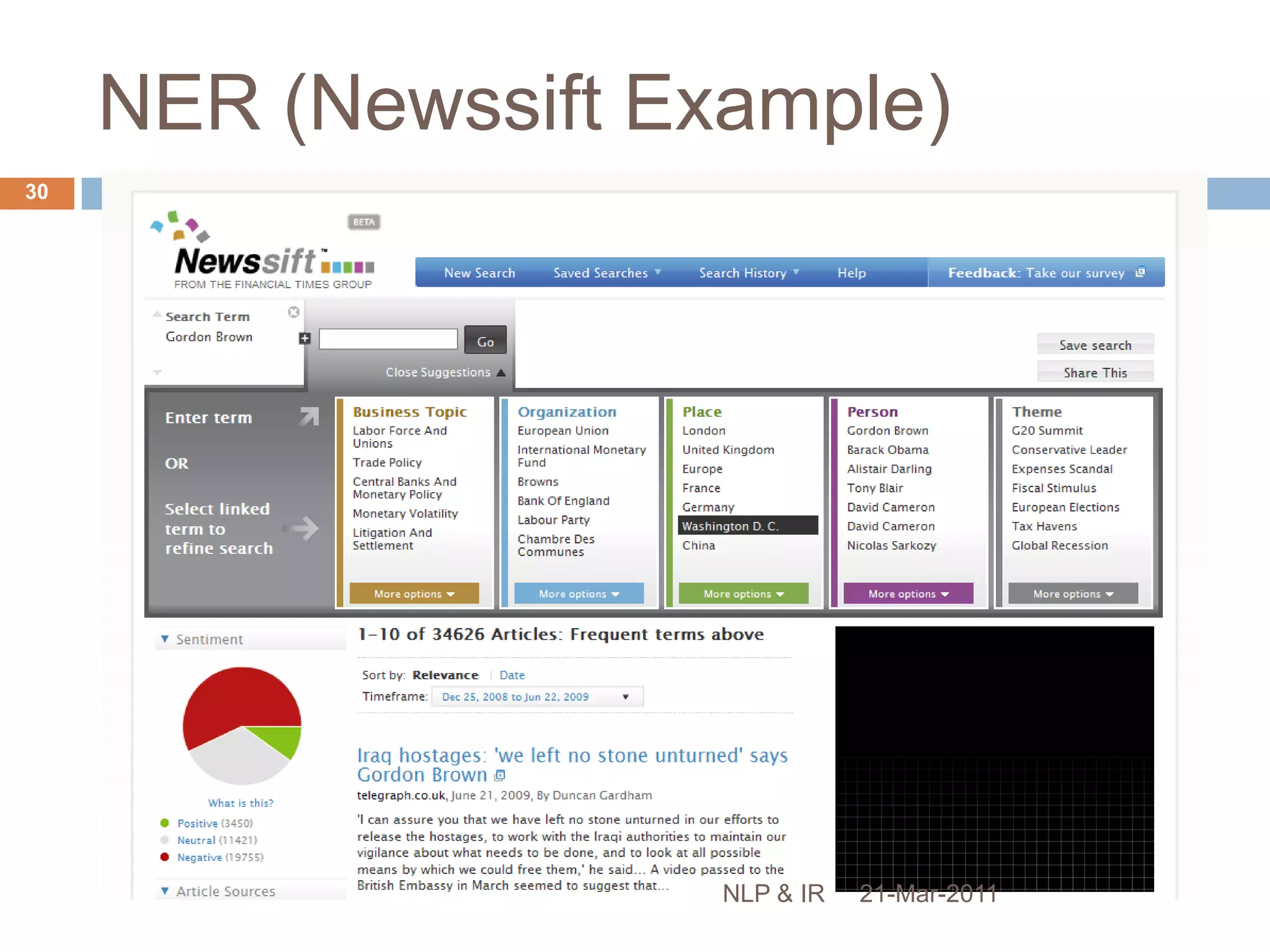
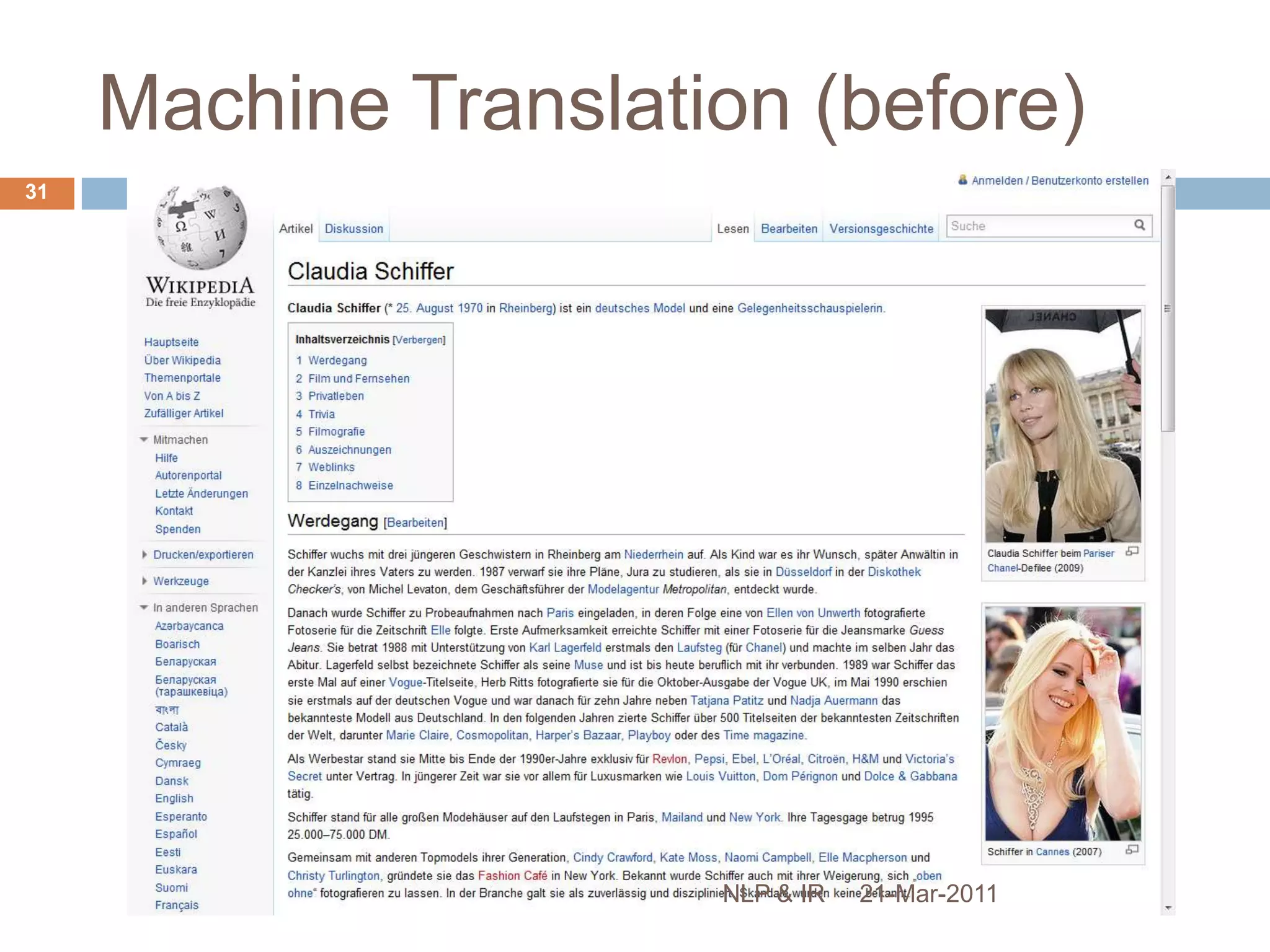
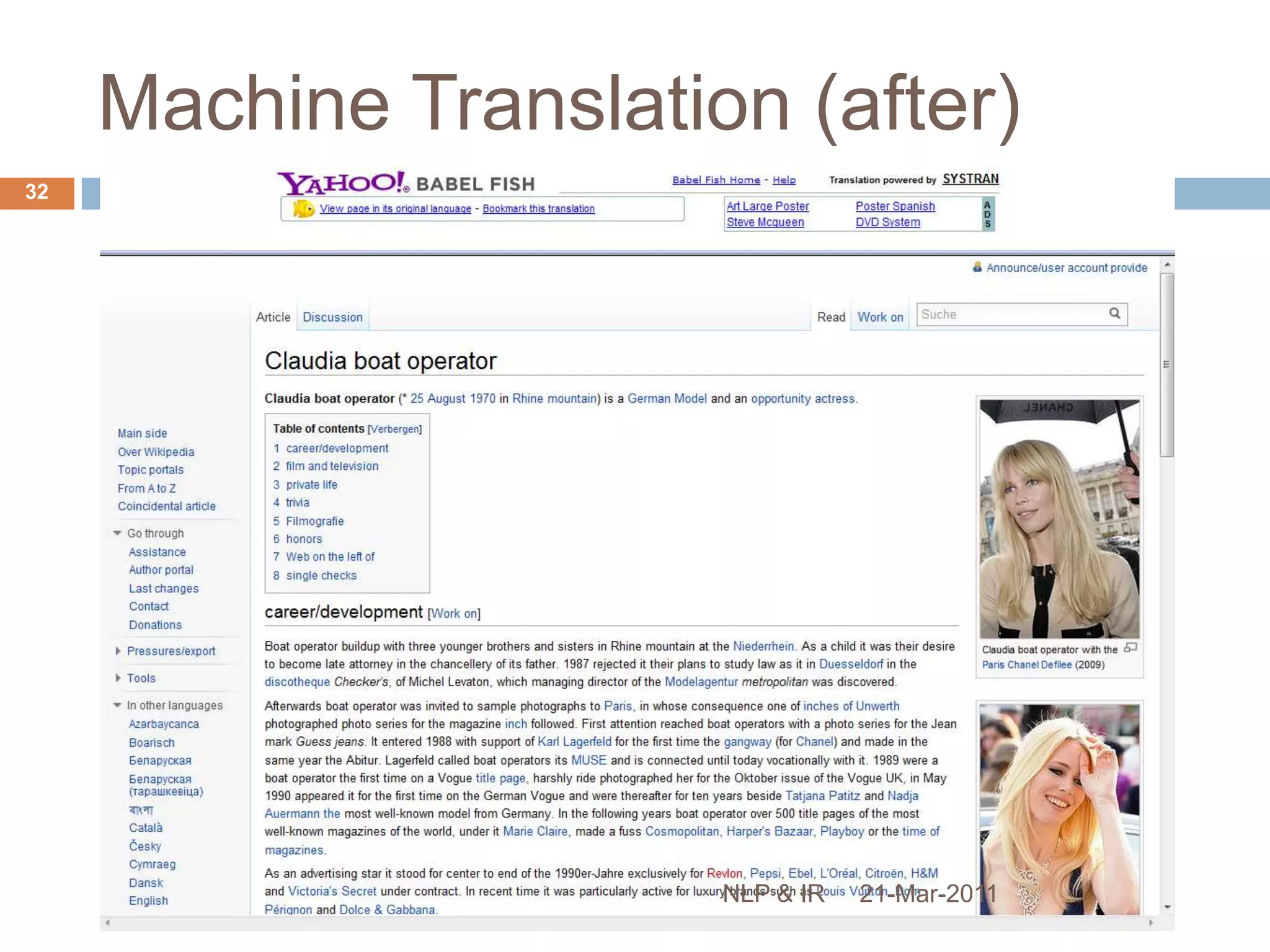
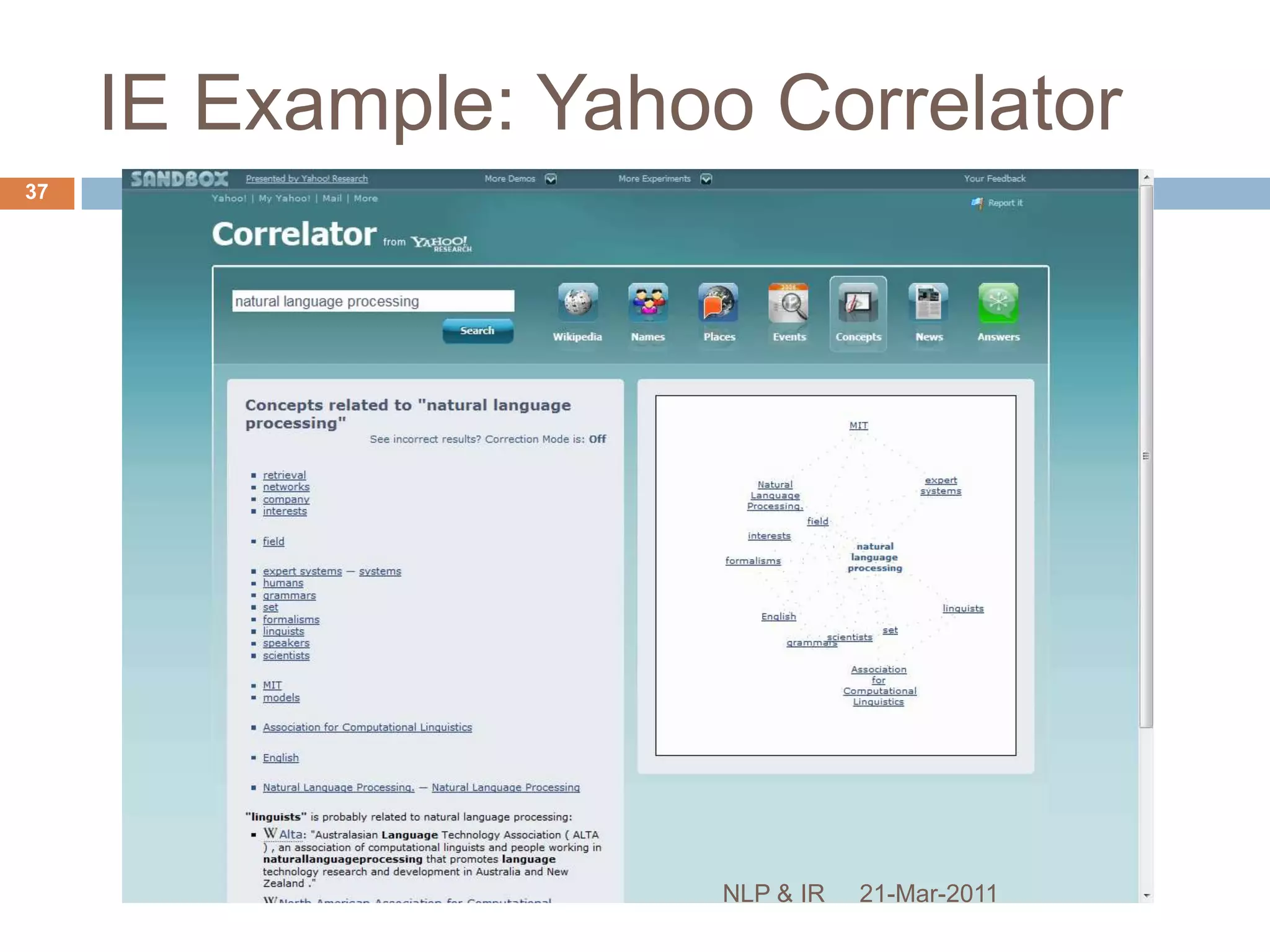
The document discusses the role of natural language processing (NLP) in information retrieval. It provides background on NLP, describing some of the fundamental problems in processing text like ambiguity and the contextual nature of language. It then outlines several common NLP tools and techniques used to analyze text at different levels, from part-of-speech tagging to named entity recognition and information extraction. The document concludes that NLP can help address some of the limitations of traditional document retrieval models by identifying implicit meanings and relationships within text.







































































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

