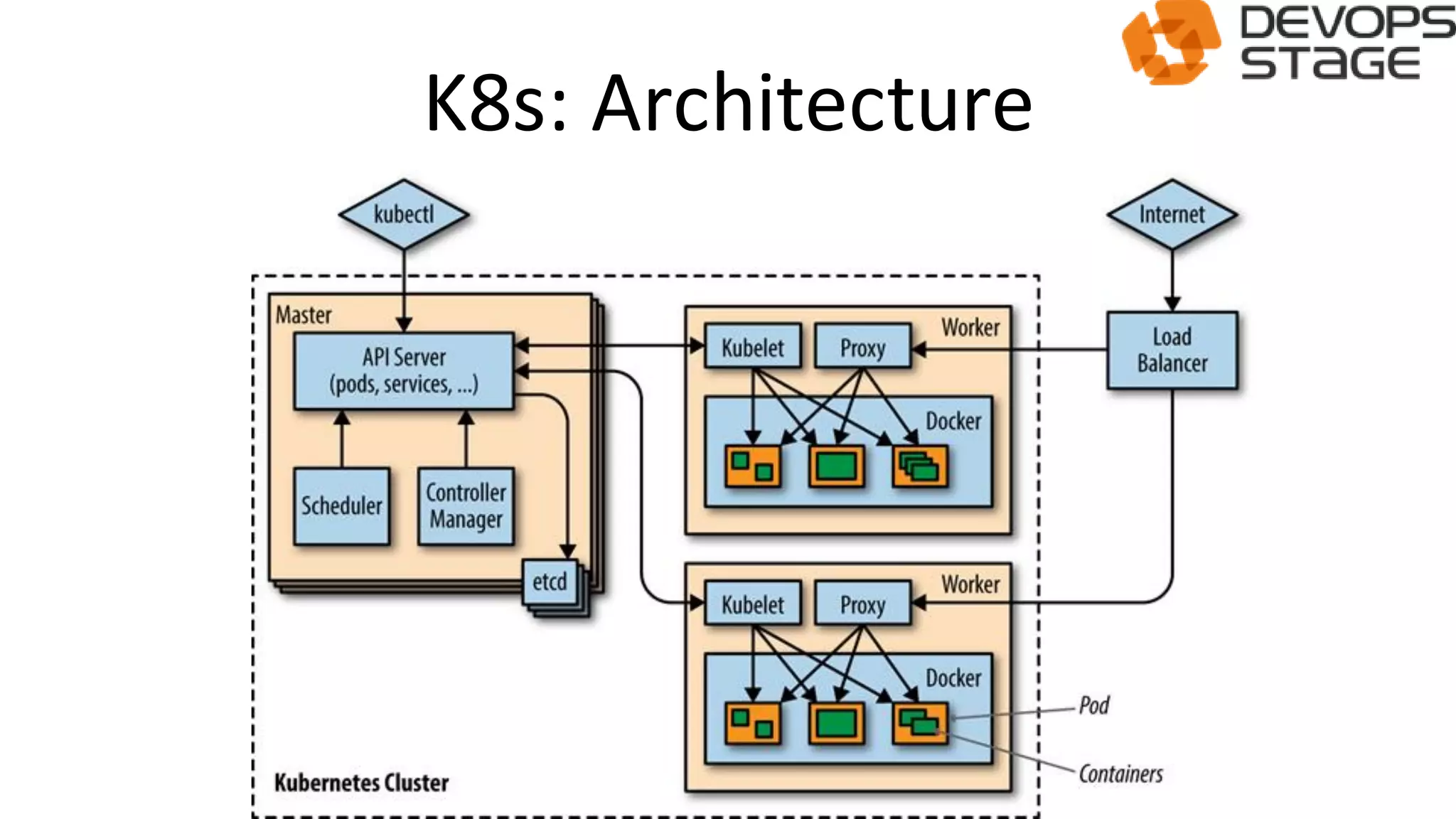
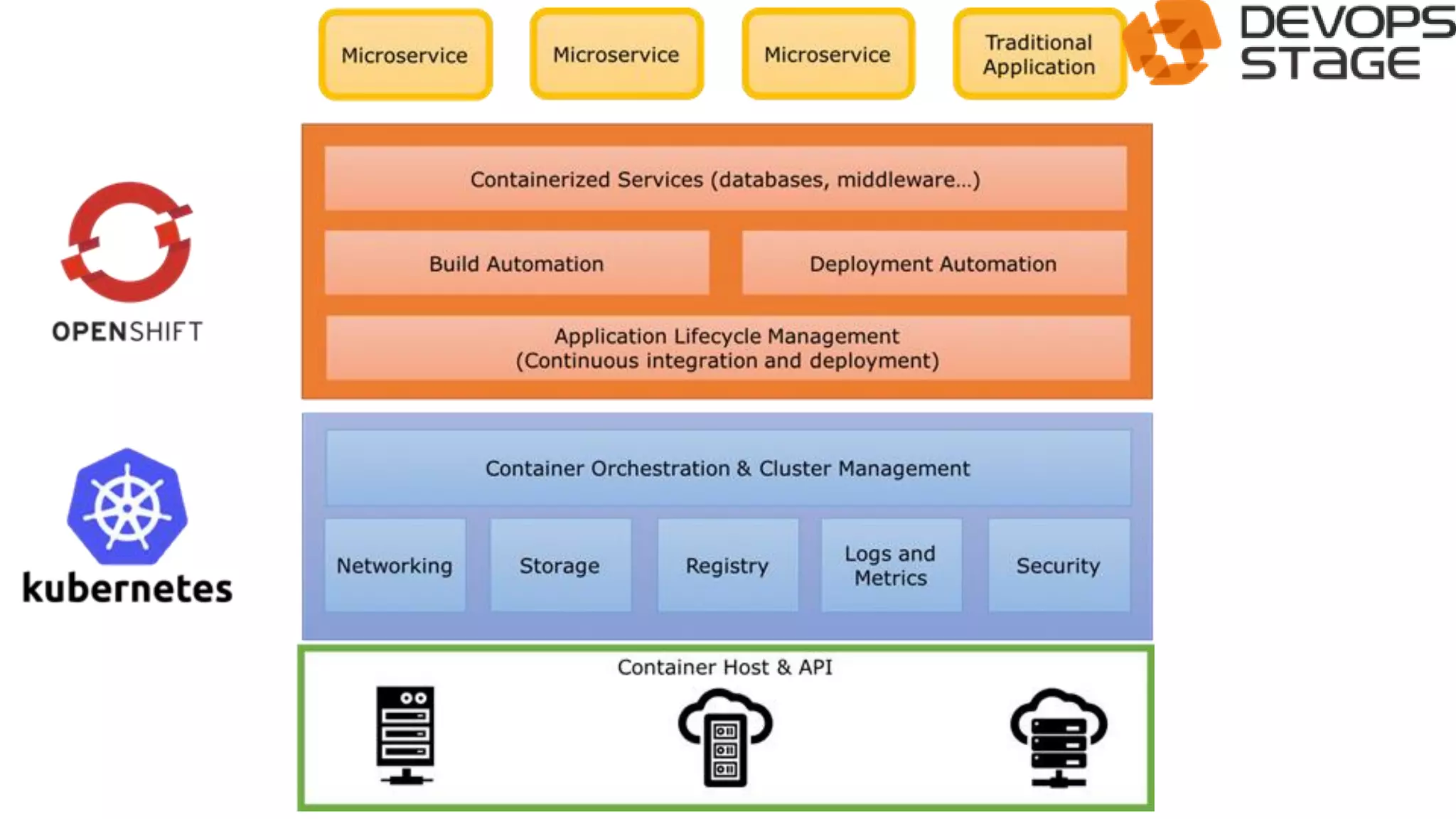
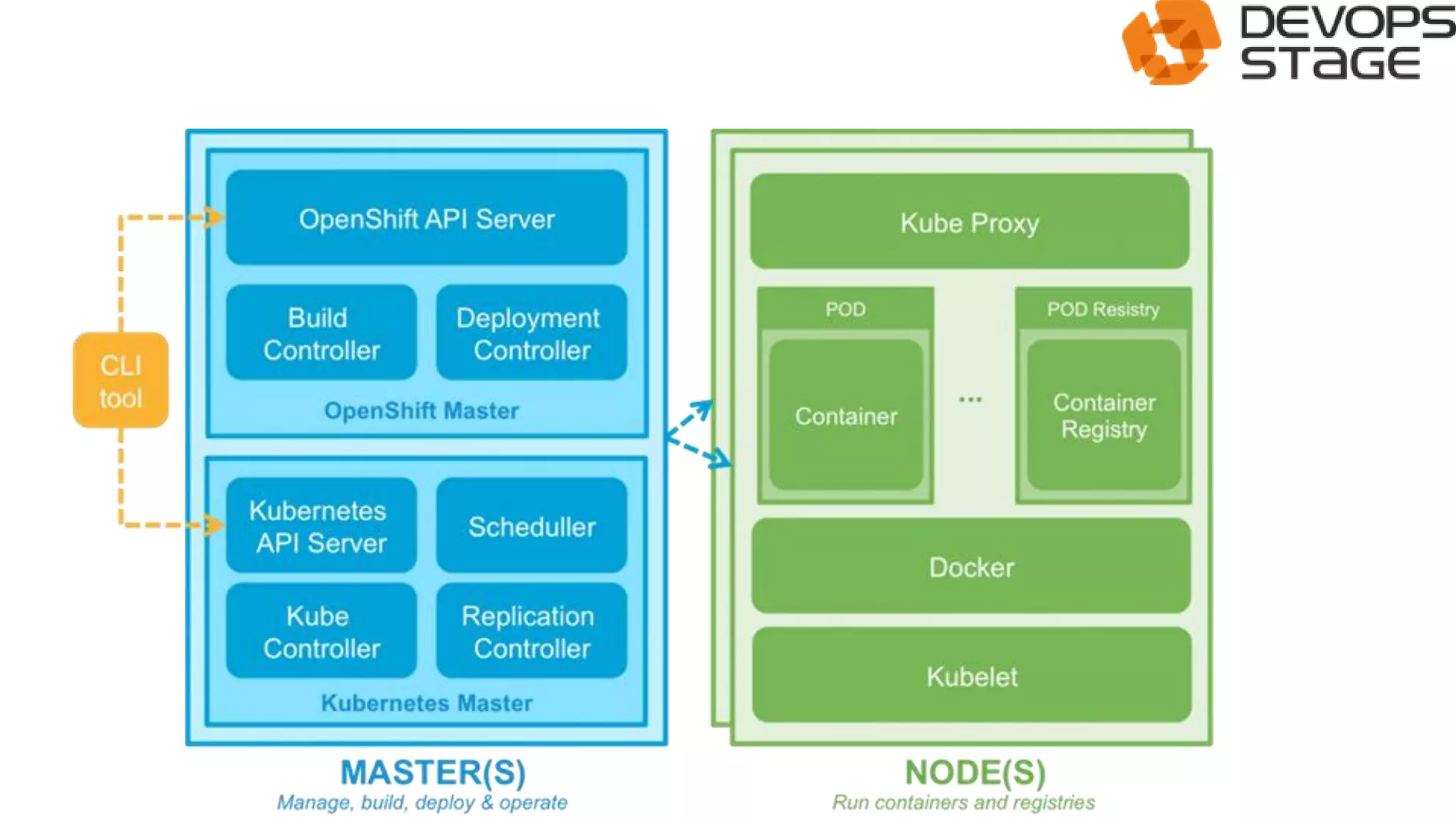
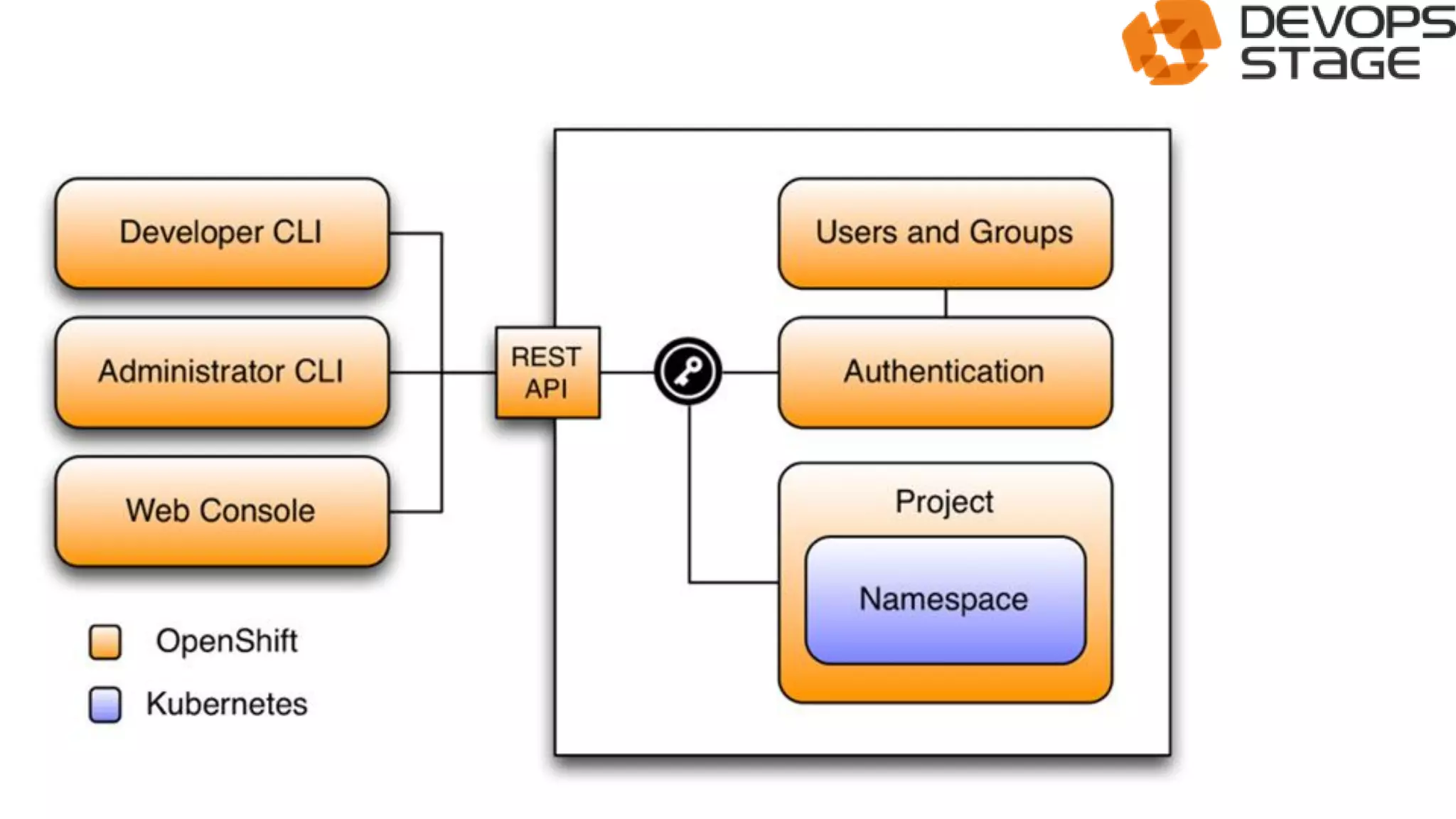
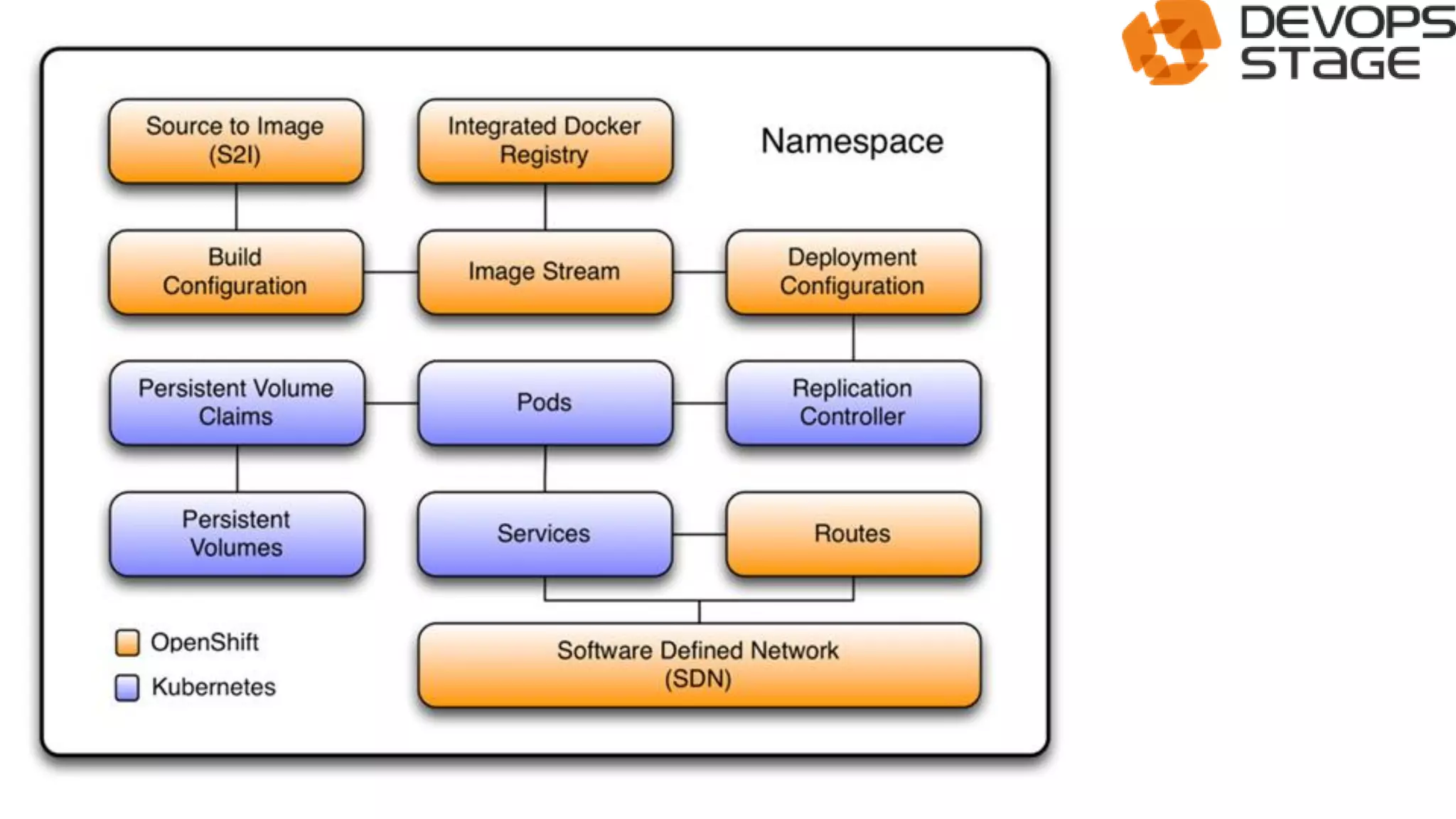
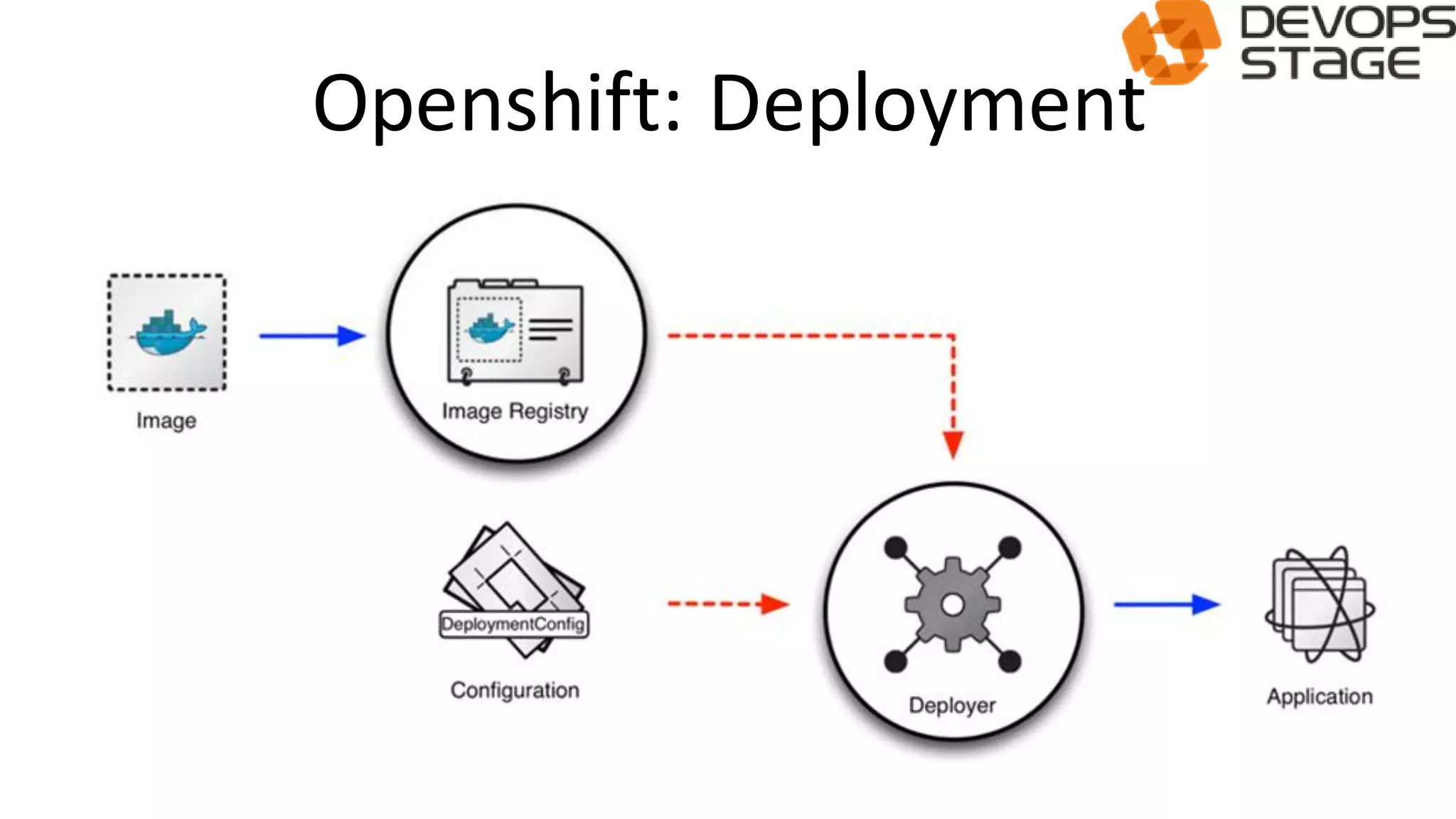
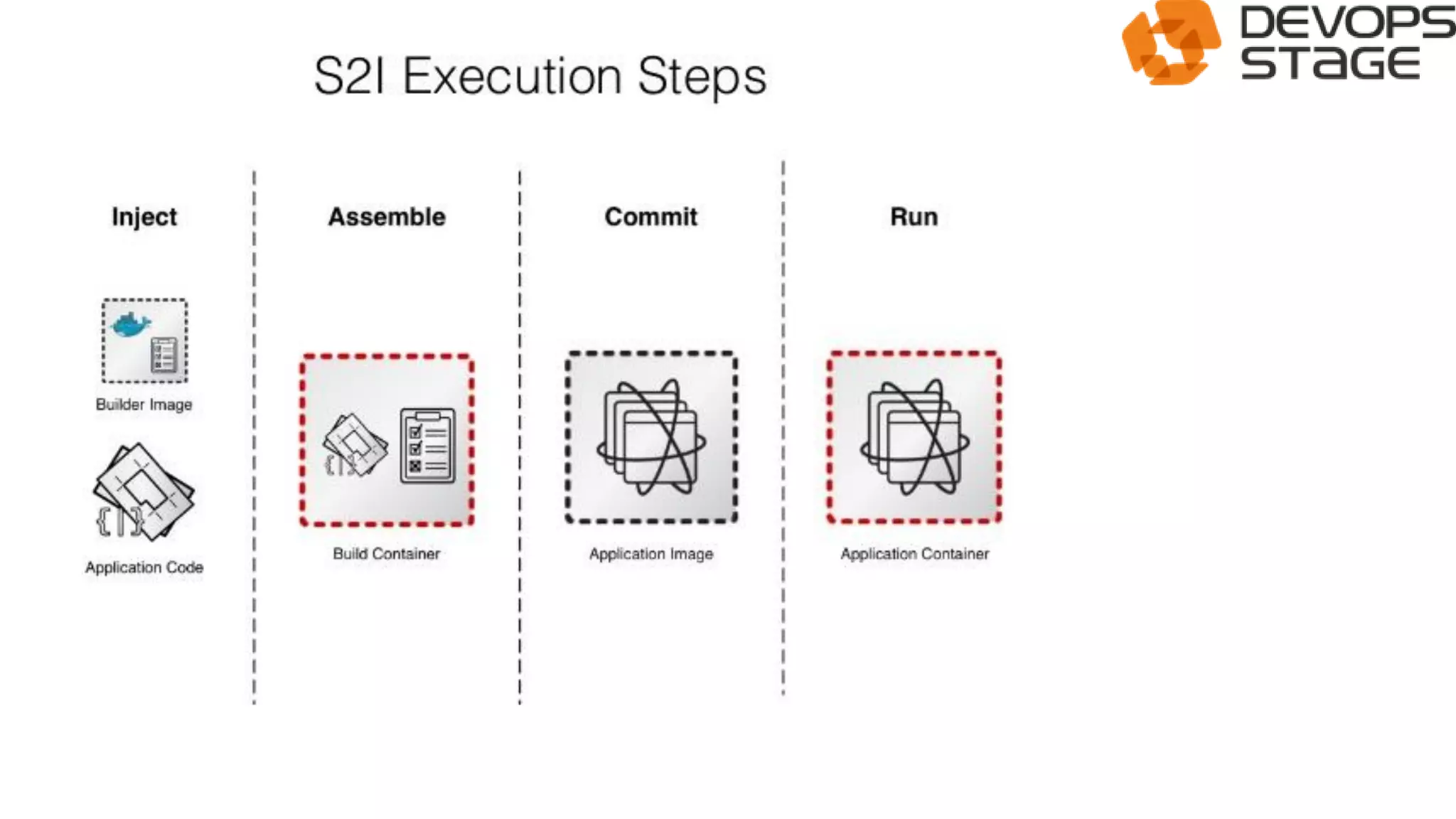
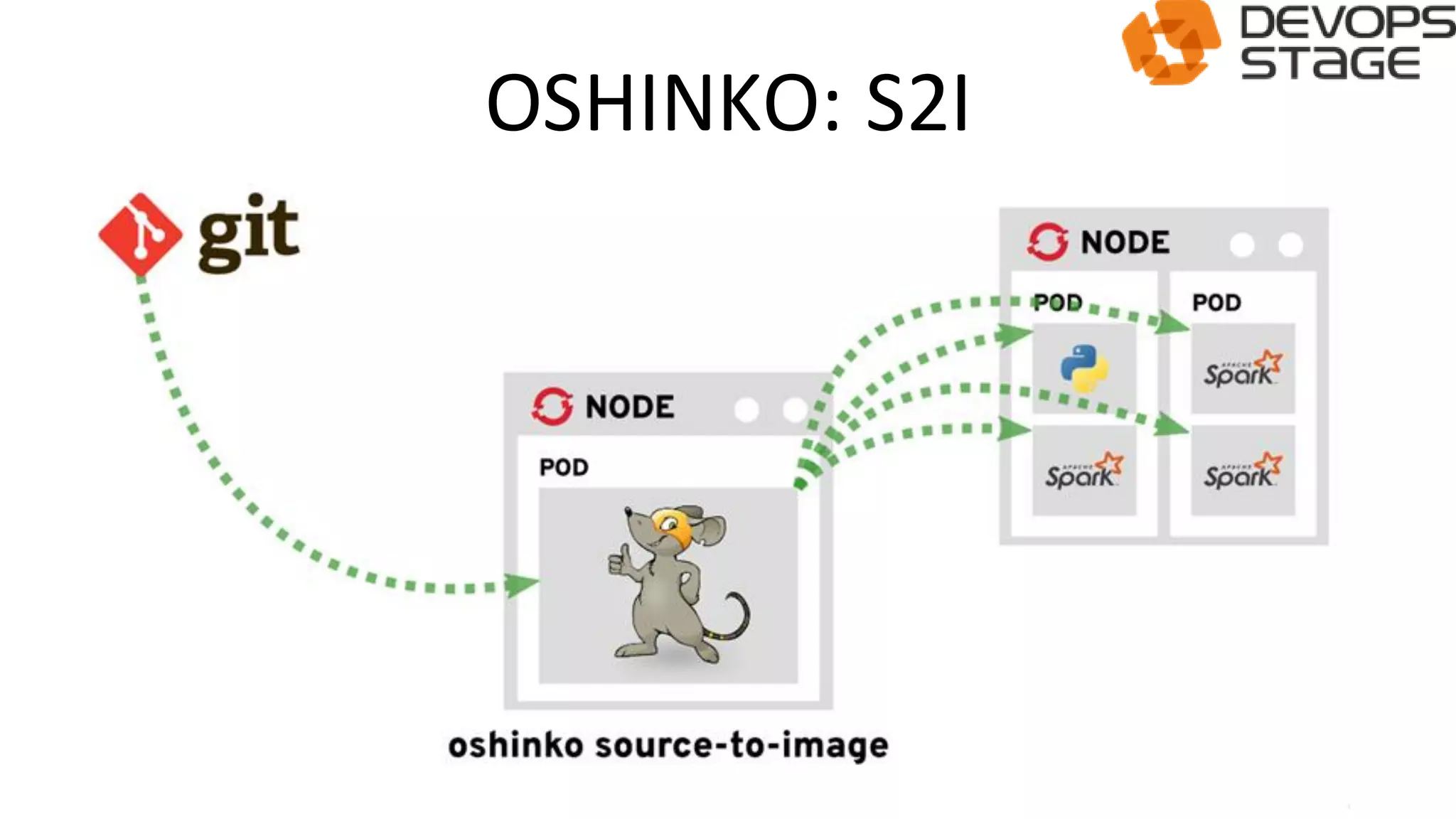
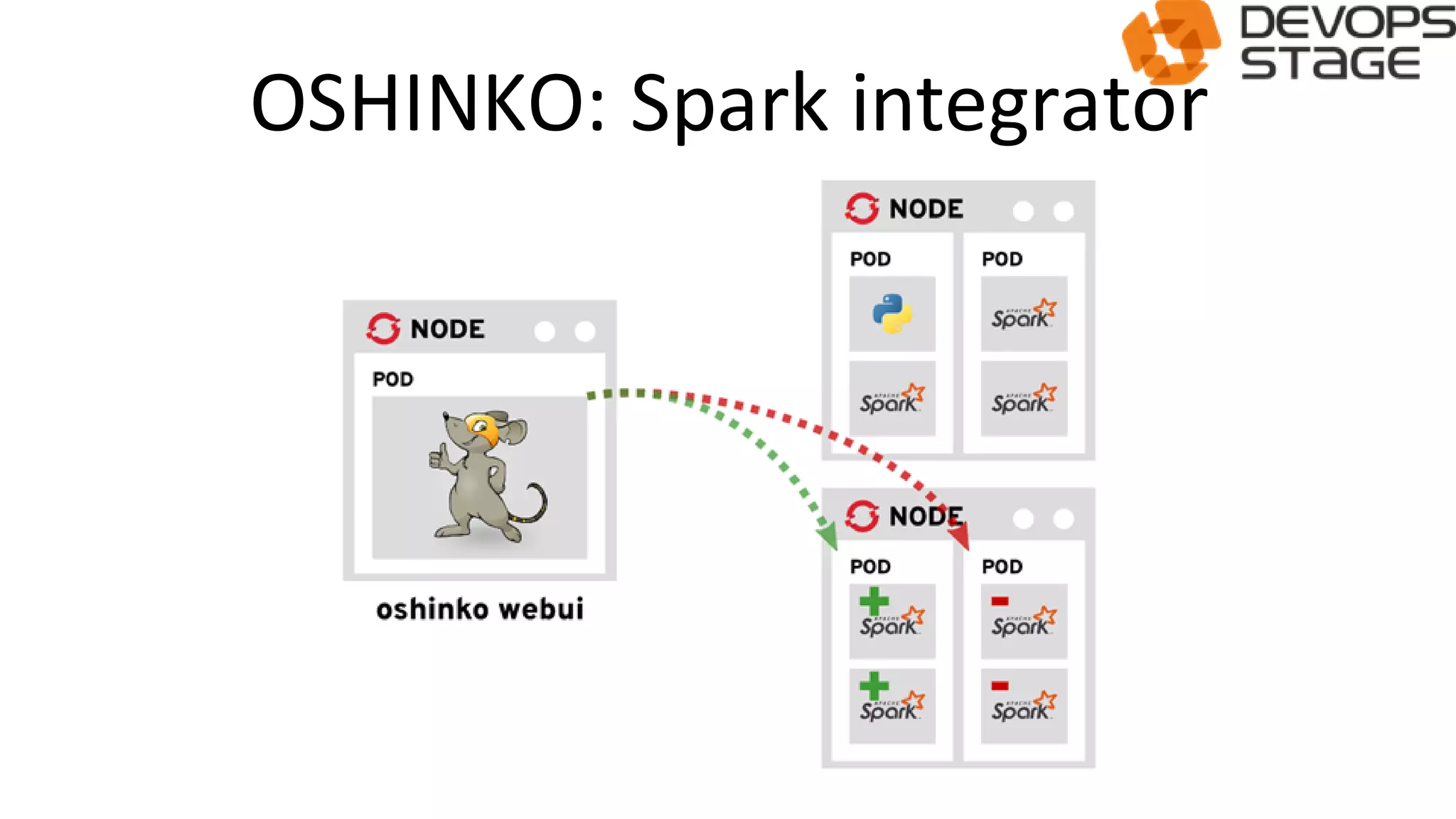
This document discusses using OpenShift as a cloud platform for data science. It provides an overview of Kubernetes and OpenShift, comparing their key differences. It then discusses how Apache Spark can be used for data science in the cloud and integrated with OpenShift using Oshinko, which provides tools to deploy and manage Spark clusters on OpenShift. It demonstrates running a sample workflow of deploying a Spark cluster, Zeppelin notebook, and running an example notebook on the Spark cluster using Oshinko on OpenShift.







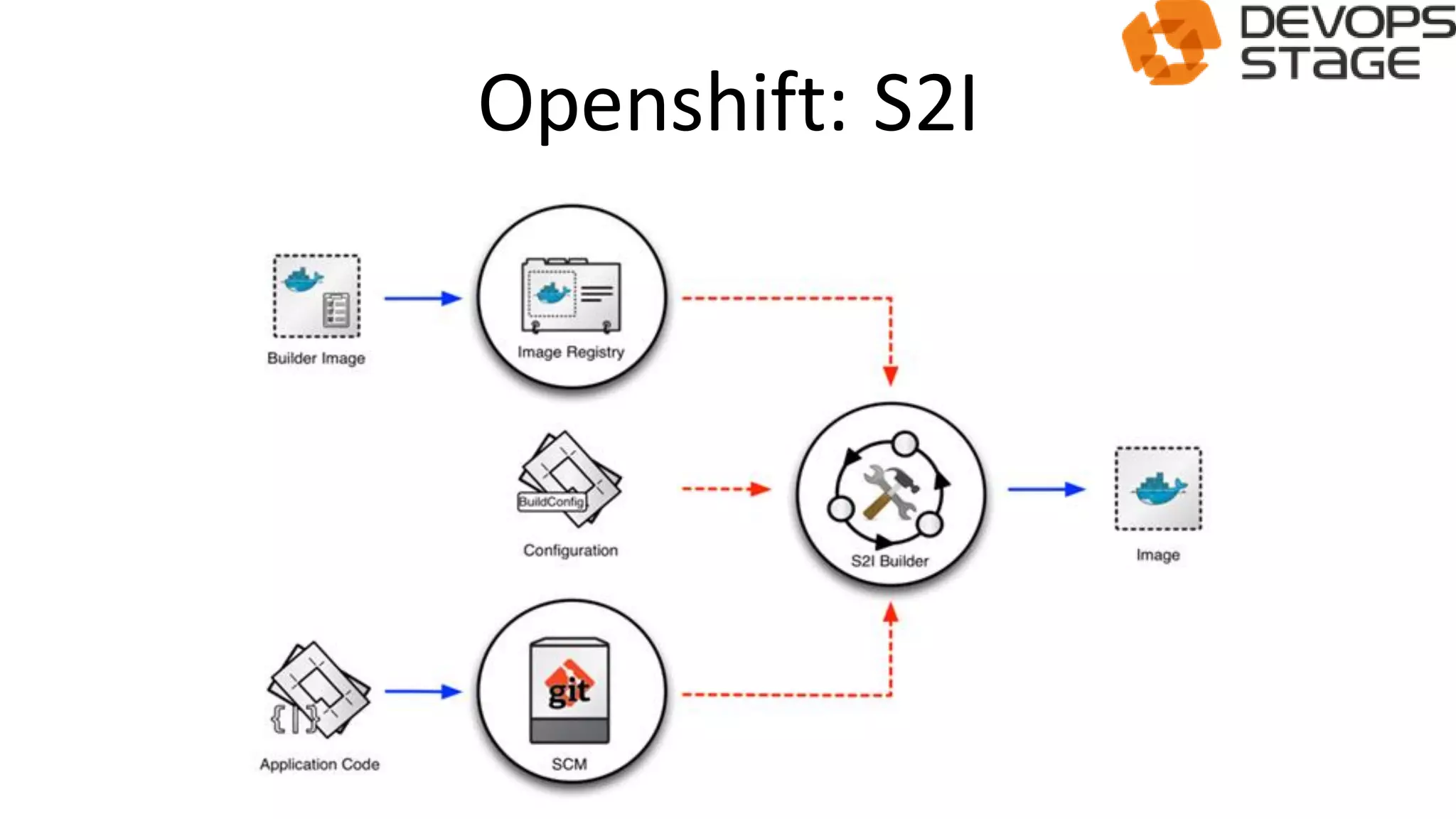
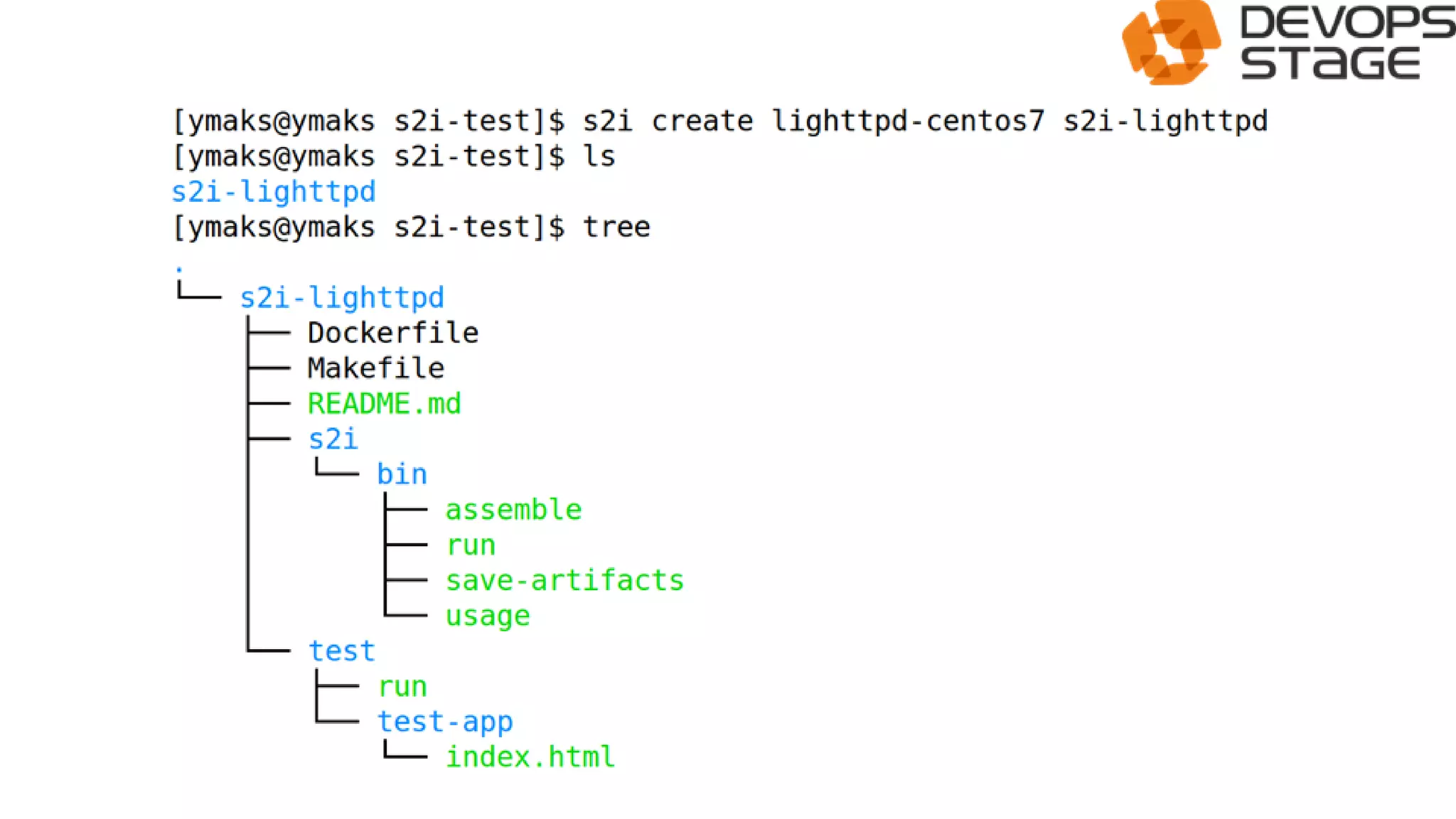




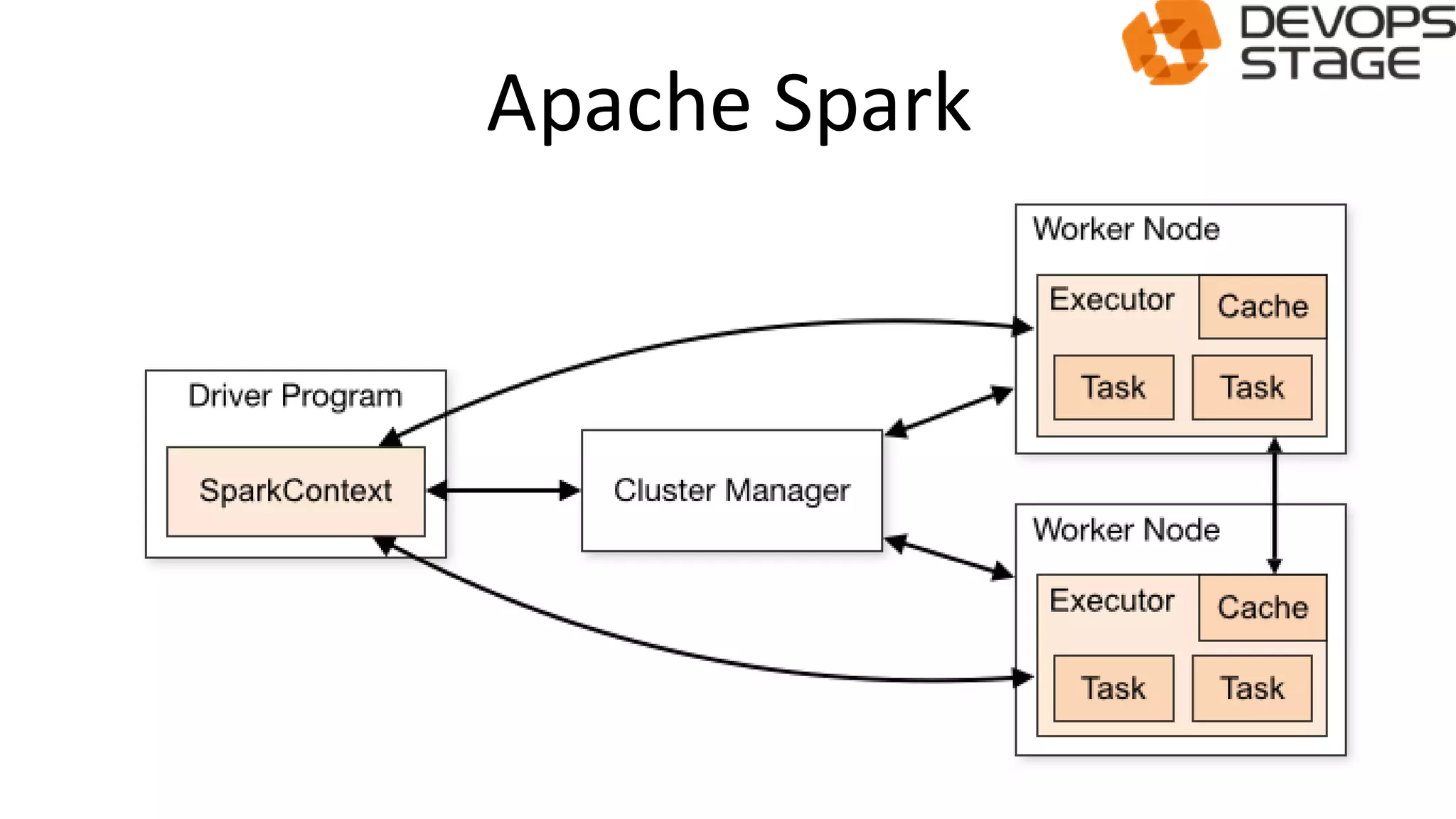
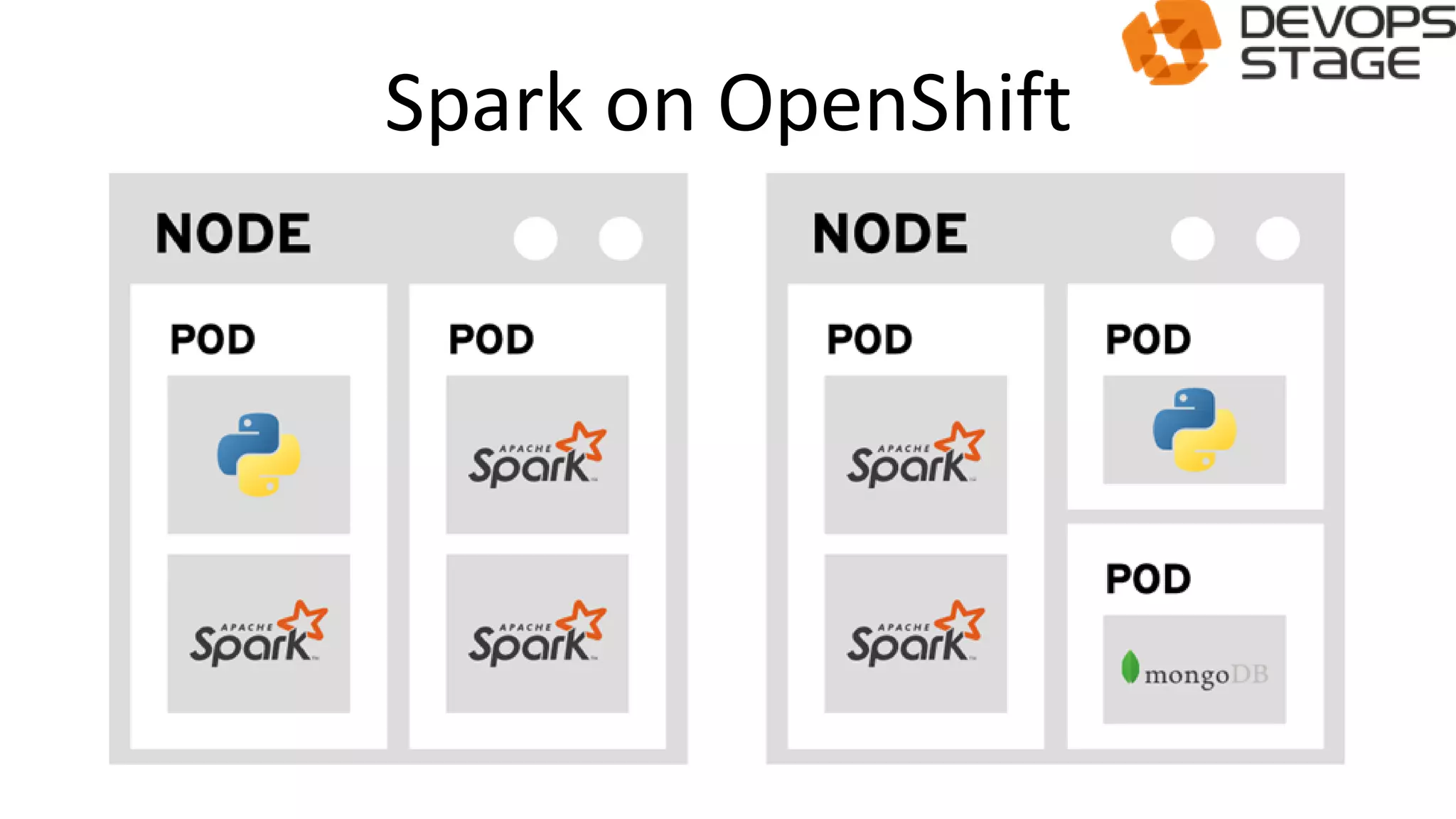









































![[DevDay 2017] OpenShift Enterprise - Speaker: Linh Do - DevOps Engineer at Ax...](https://cdn.slidesharecdn.com/ss_thumbnails/linhdoopenshiftenterprises-170420095822-thumbnail.jpg?width=640&height=640&fit=bounds)






































