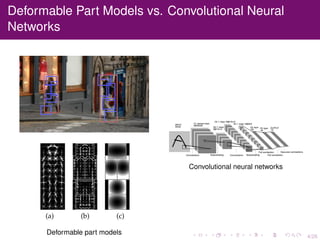
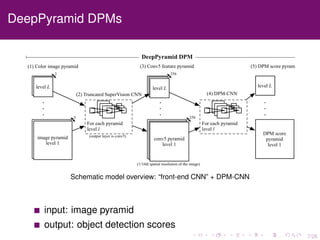
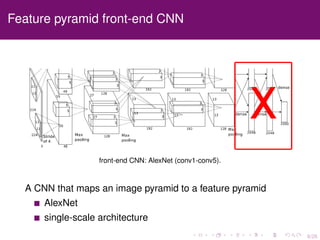
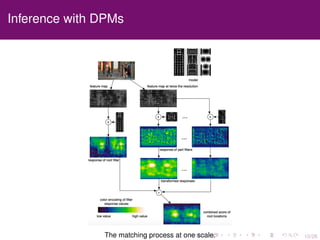
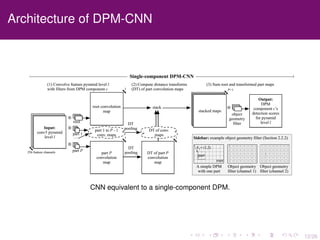
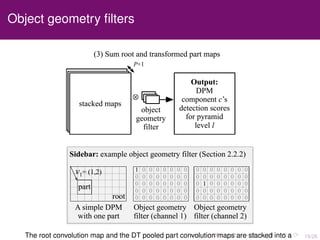
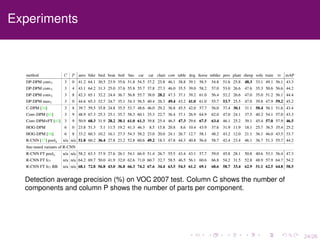
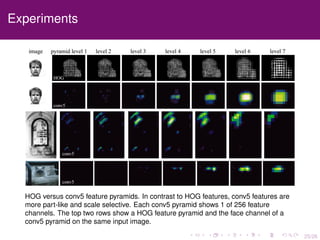
The document discusses the equivalence of deformable part models (DPMs) and convolutional neural networks (CNNs), presenting a framework to construct a CNN from any DPM. It describes the architecture of a DPM-CNN that combines features from both models and details various implementation strategies and experiments. The paper highlights performance improvements using DPM-CNNs over traditional feature extraction methods.













![13/26
Traditional distance transform
Traditional distance transforms are defined for sets of points on
a grid [FH05].
G: grid
d(p−q): measure of
distance between points
p,q ∈ G
B ⊆ G
Then the distance transform of
B on G
DB(p) = min
q∈B
d(p−q)
Distance transform (Euclidean distance)](https://image.slidesharecdn.com/zaretl0tfe7mpjczzfhi-signature-c49d91823adccb2b6c85907d81c211b7b4e70481d292a3154e593d2695e66032-poli-160811023311/85/Deformable-Part-Models-are-Convolutional-Neural-Networks-18-320.jpg)


![16/26
Distance transform in DPM
In DPM, after computing filter responses we transform the
responses of the part filters to allow spatial uncertainty,
Di(x,y) = max
dx,dy
(Ri(x+dx,y+dy)−wi ·φd(dx,dy))
where
φd(dx,dy) = [dx,dy,dx2
,,dy2
]
The value Di(x,y) is the maximum contribution of the part
to the score of a root location that places the anchor of this
part at position (x,y).](https://image.slidesharecdn.com/zaretl0tfe7mpjczzfhi-signature-c49d91823adccb2b6c85907d81c211b7b4e70481d292a3154e593d2695e66032-poli-160811023311/85/Deformable-Part-Models-are-Convolutional-Neural-Networks-21-320.jpg)
![16/26
Distance transform in DPM
In DPM, after computing filter responses we transform the
responses of the part filters to allow spatial uncertainty,
Di(x,y) = max
dx,dy
(Ri(x+dx,y+dy)−wi ·φd(dx,dy))
where
φd(dx,dy) = [dx,dy,dx2
,,dy2
]
The value Di(x,y) is the maximum contribution of the part
to the score of a root location that places the anchor of this
part at position (x,y).
By letting p = (x,y), p−q = (dx,dy) and
d(p−q) = w·φ(p−q), we can see that it is exactly in the
form of distance transform.](https://image.slidesharecdn.com/zaretl0tfe7mpjczzfhi-signature-c49d91823adccb2b6c85907d81c211b7b4e70481d292a3154e593d2695e66032-poli-160811023311/85/Deformable-Part-Models-are-Convolutional-Neural-Networks-22-320.jpg)


![18/26
Generalize max pooling to distance transform pooling
We can generalize max pooling to distance transform pooling:
unlike max pooling, the distance transform of f at p is
taken over the entire domain G
rather than specifying a fixed pooling window a priori, the
shape of the pooling region can be learned from the data.
The released code does not include the DT pooling layer.
Please refer to [OW13] for more details.](https://image.slidesharecdn.com/zaretl0tfe7mpjczzfhi-signature-c49d91823adccb2b6c85907d81c211b7b4e70481d292a3154e593d2695e66032-poli-160811023311/85/Deformable-Part-Models-are-Convolutional-Neural-Networks-25-320.jpg)
![20/26
Combining mixture components with maxout
CNN equivalent to a multi-component DPM. A multi-component DPM-CNN is
composed of one DPM-CNN per component and a maxout [GWFM+13] layer that
takes a max over component DPM-CNN outputs at each location.](https://image.slidesharecdn.com/zaretl0tfe7mpjczzfhi-signature-c49d91823adccb2b6c85907d81c211b7b4e70481d292a3154e593d2695e66032-poli-160811023311/85/Deformable-Part-Models-are-Convolutional-Neural-Networks-27-320.jpg)









![2014.03.31.bach glc-pham-finalizing[conflict]](https://cdn.slidesharecdn.com/ss_thumbnails/2014-150417024004-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)






































![[Mmlab seminar 2016] deep learning for human pose estimation](https://cdn.slidesharecdn.com/ss_thumbnails/mucdgsomrcs8cgkh9gsp-signature-54f17826ed7e29e13653ed835b10fabd79d8e26ac84412798c7e96ef7d109006-poli-160811023645-thumbnail.jpg?width=640&height=640&fit=bounds)






















![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)


















