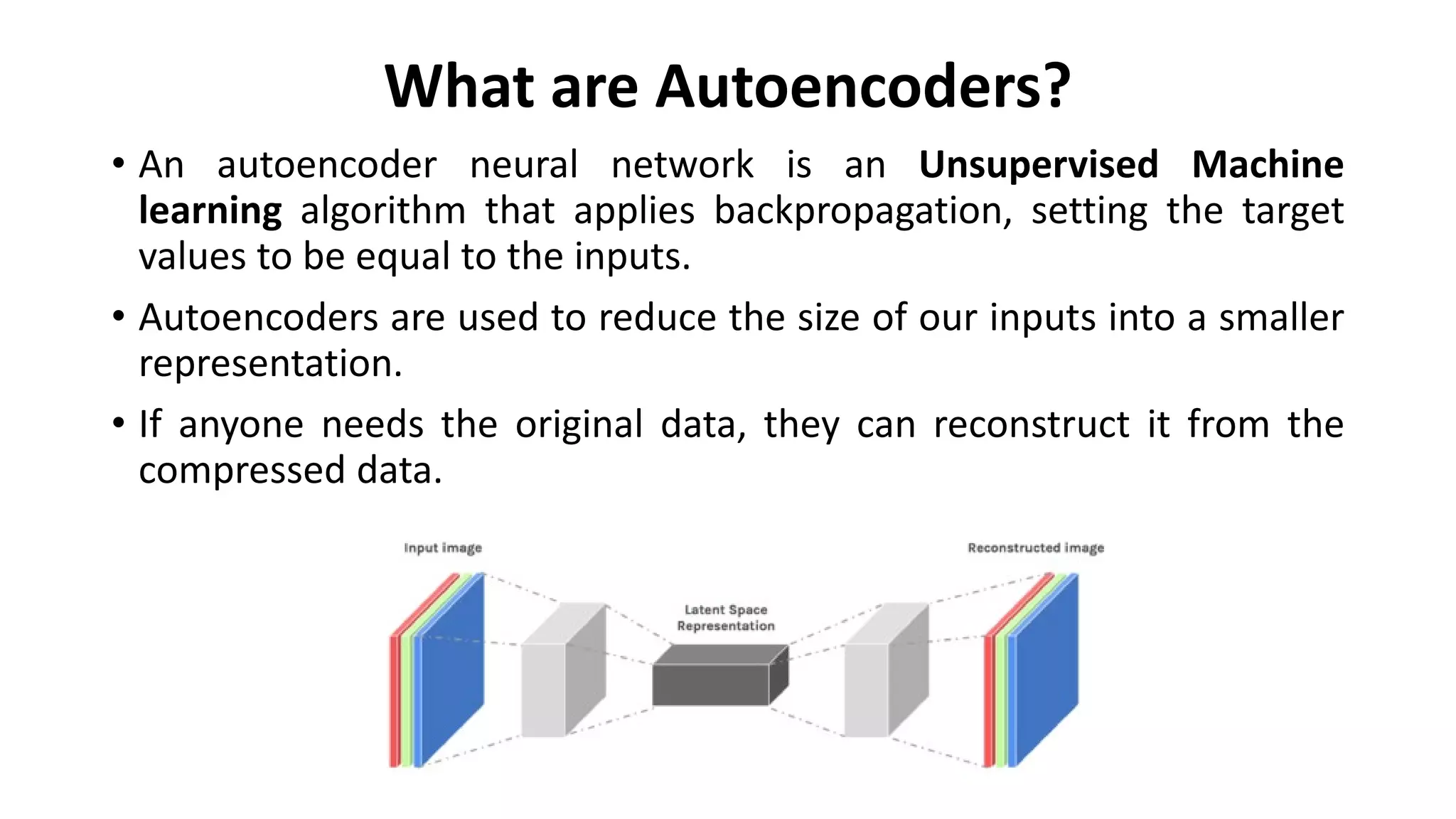
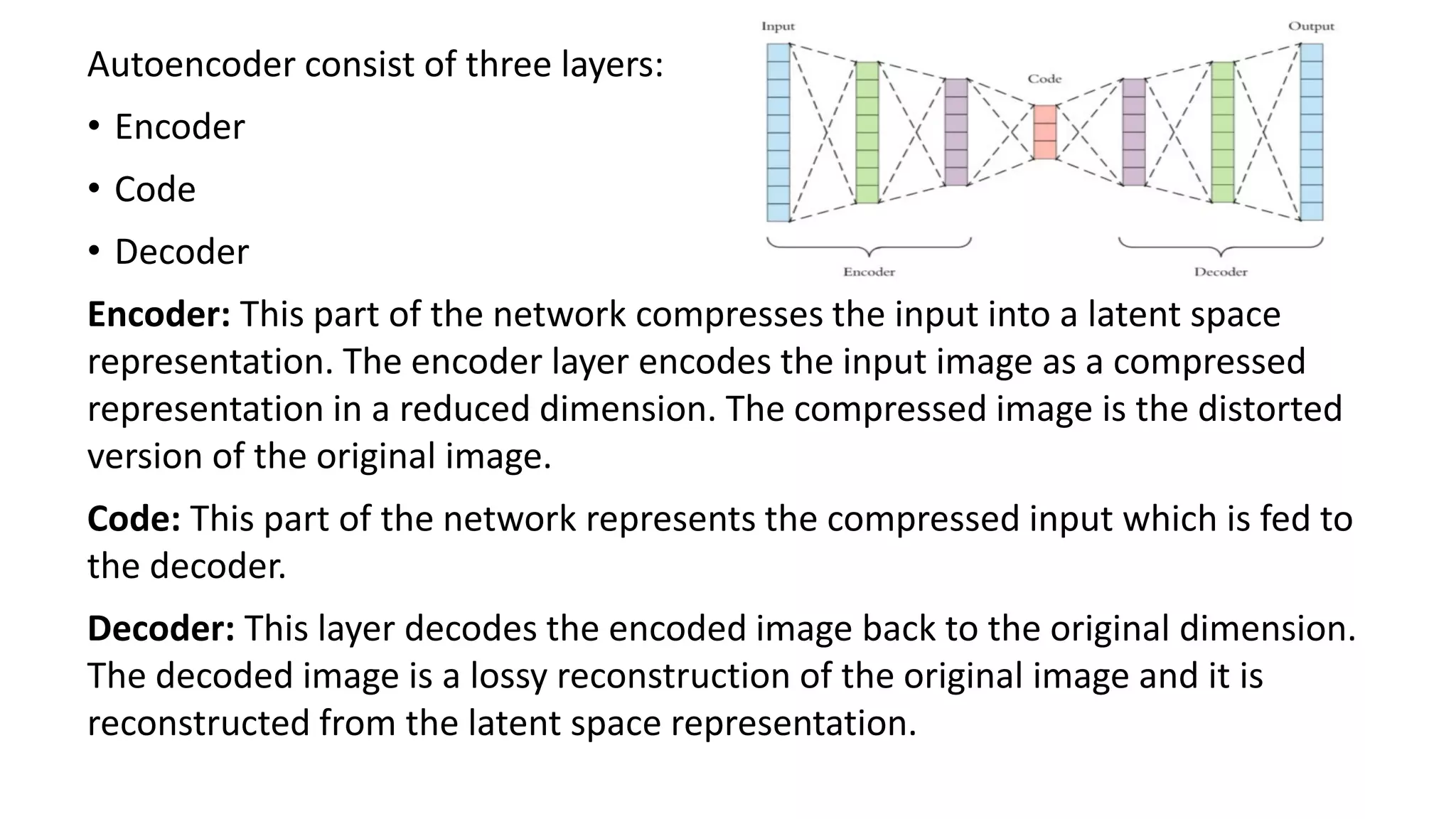
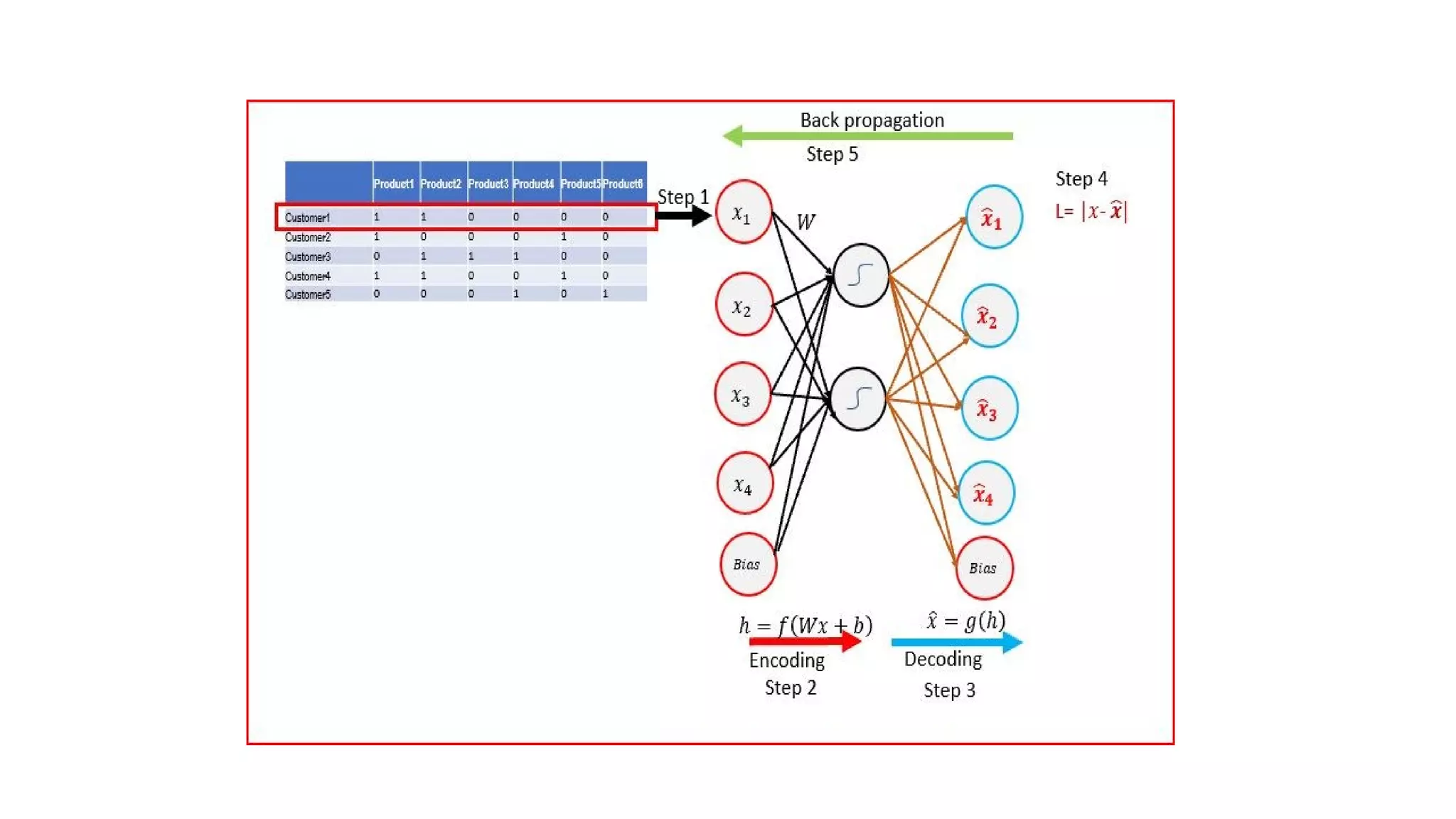
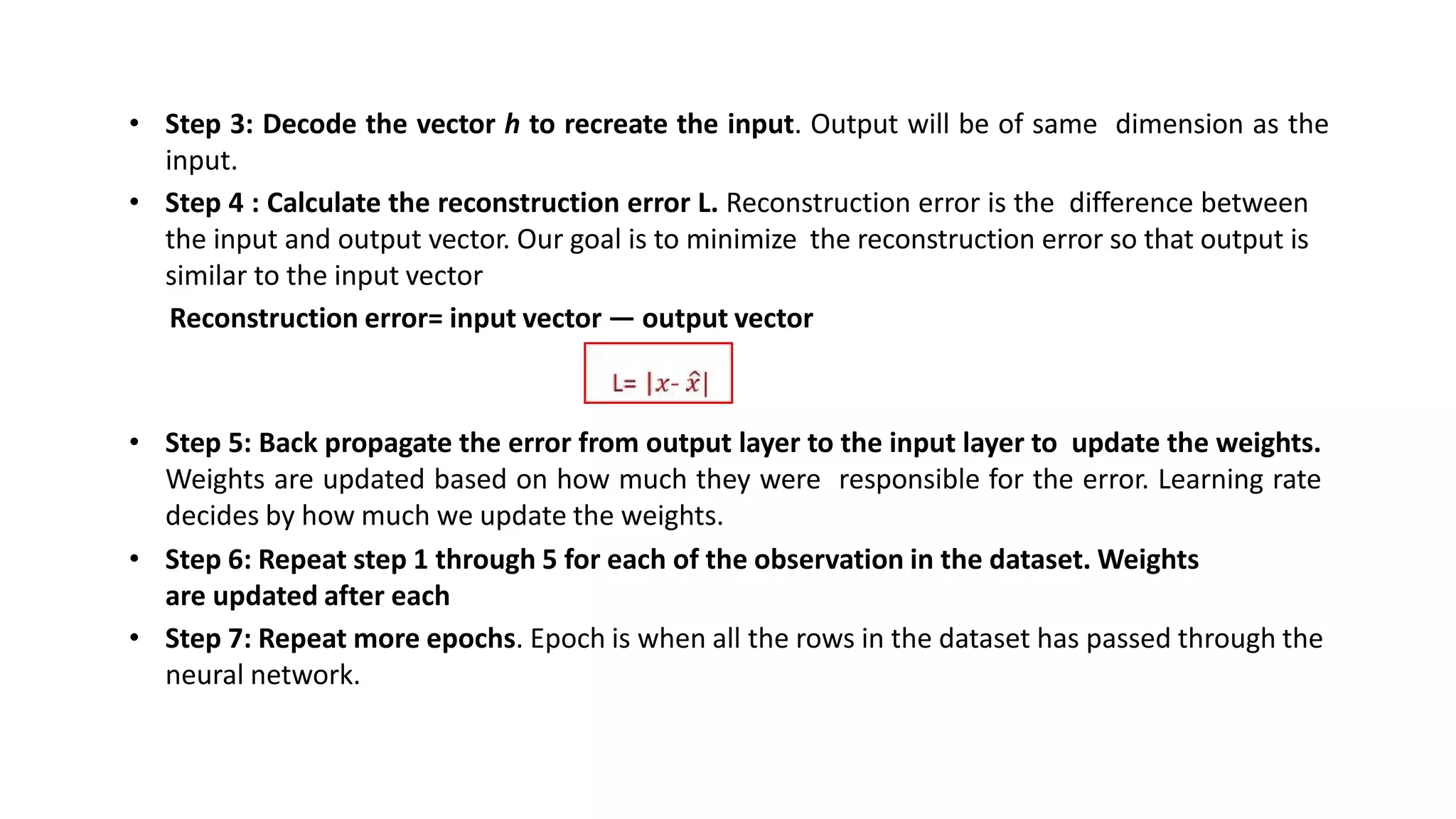
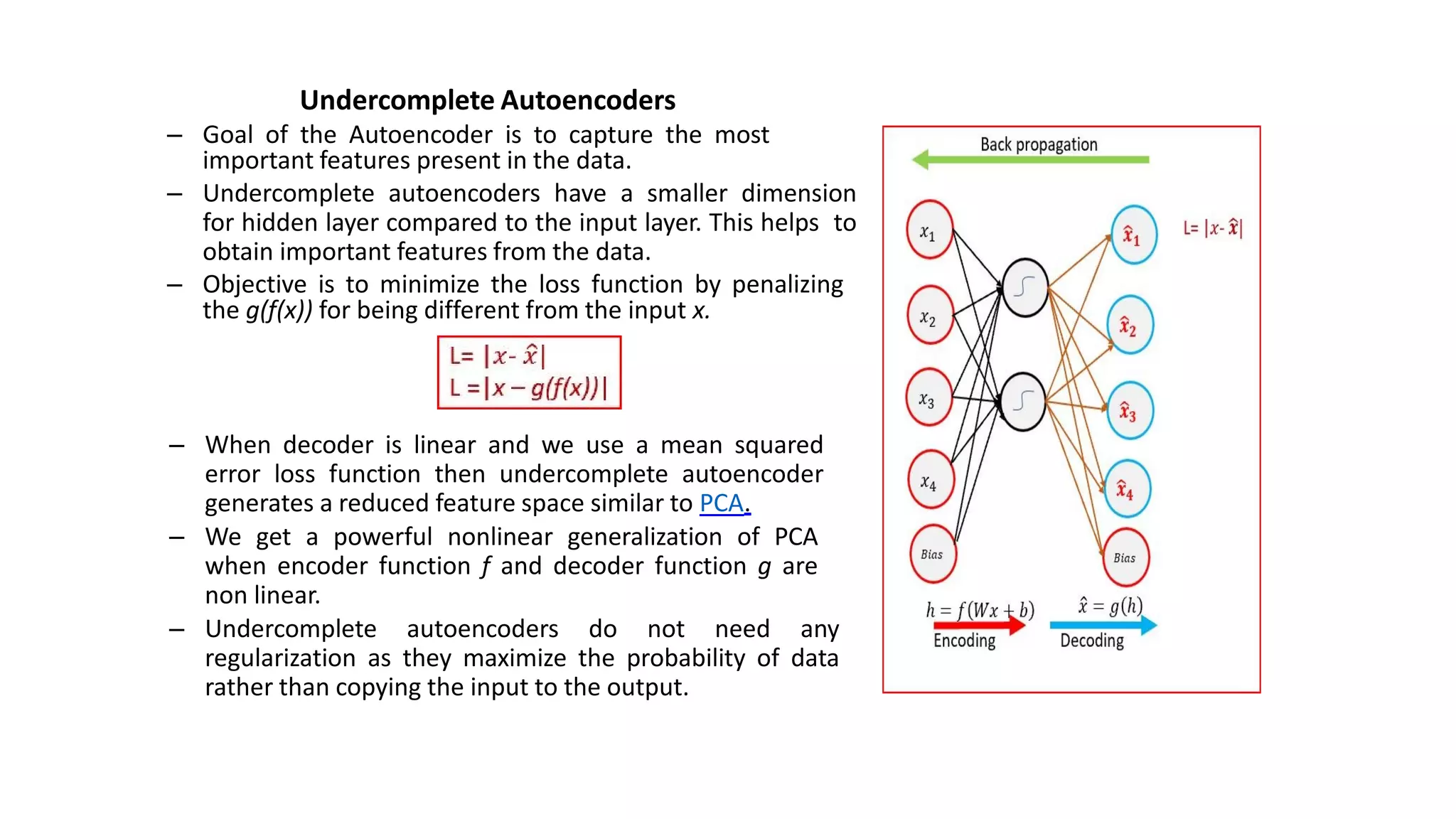
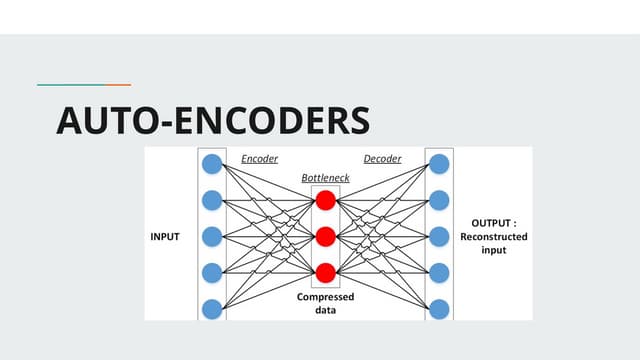
- Autoencoders are unsupervised neural networks that compress input data into a latent space representation and then reconstruct the output from this representation. They aim to copy their input to their output with minimal loss of information.
- Autoencoders consist of an encoder that compresses the input into a latent space and a decoder that decompresses this latent space back into the original input space. The network is trained to minimize the reconstruction loss between the input and output.
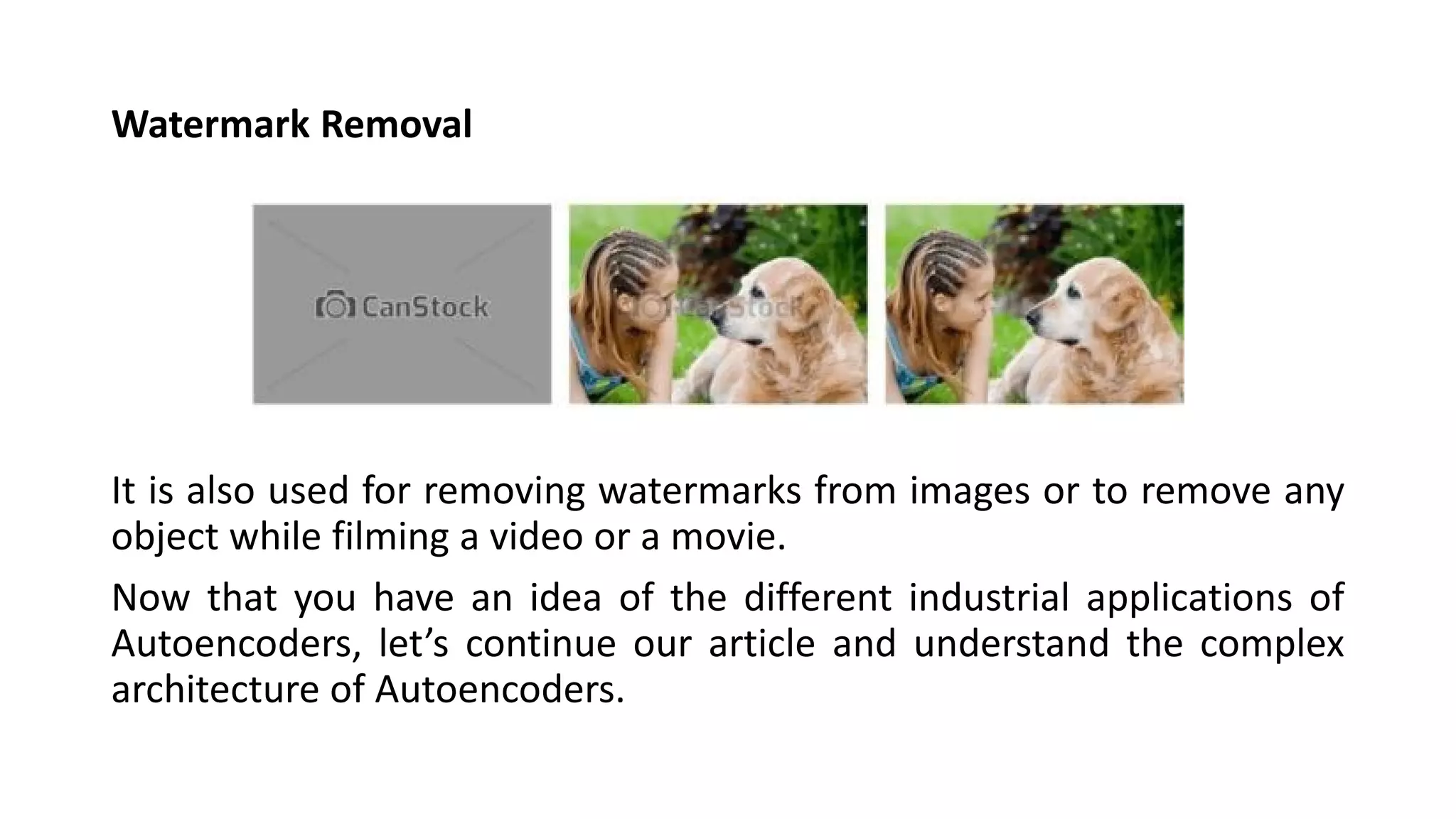
- Autoencoders are commonly used for dimensionality reduction, feature extraction, denoising images, and generating new data similar to the training data distribution.


















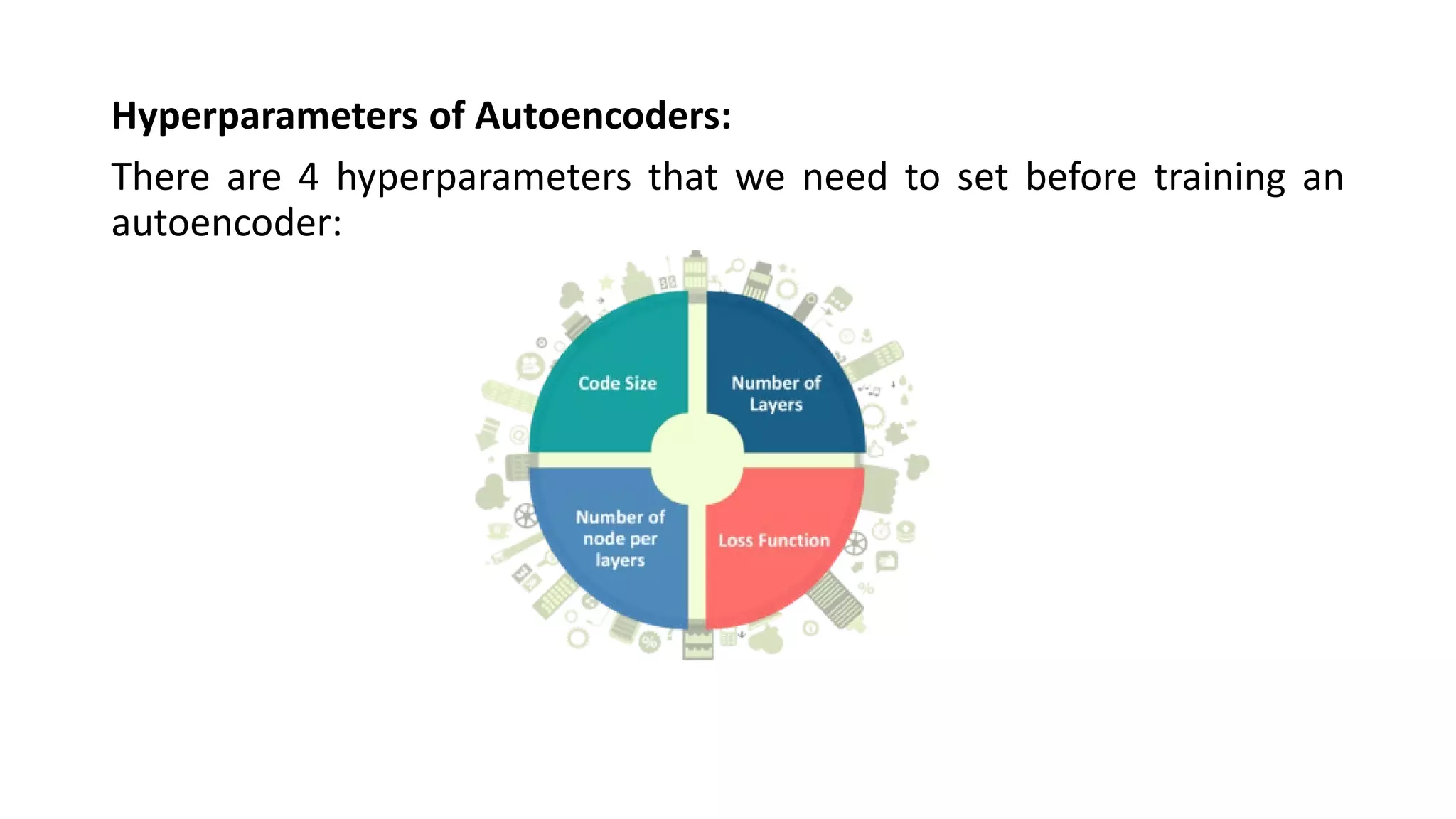
![Code size: It represents the number of nodes in the middle layer.
Smaller size results in more compression.
Number of layers: The autoencoder can consist of as many layers as we
want.
Number of nodes per layer: The number of nodes per layer decreases
with each subsequent layer of the encoder, and increases back in the
decoder. The decoder is symmetric to the encoder in terms of the layer
structure.
Loss function: We either use mean squared error or binary cross-
entropy. If the input values are in the range [0, 1] then we typically use
cross-entropy, otherwise, we use the mean squared error.](https://image.slidesharecdn.com/unit-4-221009105314-7ee685b1/75/UNIT-4-pdf-26-2048.jpg)

![Then we need to build the encoder model and decoder model separately so that we can easily differentiate
between the input and output.
# This model shows encoded images
encoder = Model(input_img, encoded)
# Creating a decoder model
encoded_input = Input(shape=(encoding_dim,))
# last layer of the autoencoder model
decoder_layer = autoencoder.layers[-1]
# decoder model
decoder = Model(encoded_input, decoder_layer(encoded_input))
Then we need to compile the model with the ADAM optimizer and cross-entropy loss function fitment.
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
Then you need to load the data :
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)](https://image.slidesharecdn.com/unit-4-221009105314-7ee685b1/75/UNIT-4-pdf-28-2048.jpg)
![If you want to see how the data is actually, you can use the following line of code :
plt.imshow(x_train[0].reshape(28,28))
Then you need to train your model :
autoencoder.fit(x_train, x_train,
epochs=15,
batch_size=256,
validation_data=(x_test, x_test))
After training, you need to provide the input and you can plot the results using the following code :
encoded_img = encoder.predict(x_test)
decoded_img = decoder.predict(encoded_img)
plt.figure(figsize=(20, 4))
for i in range(5):
# Display original
ax = plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, 5, i + 1 + 5)
plt.imshow(decoded_img[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()](https://image.slidesharecdn.com/unit-4-221009105314-7ee685b1/75/UNIT-4-pdf-29-2048.jpg)




![Now you need to load the data and training the
model
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28,
1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
model.fit(x_train, x_train,
epochs=15,
batch_size=128,
validation_data=(x_test, x_test))
Now you need to provide the input and plot the output for the
following results
pred = model.predict(x_test)
plt.figure(figsize=(20, 4))
for i in range(5):
# Display original
ax = plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, 5, i + 1 + 5)
plt.imshow(pred[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()](https://image.slidesharecdn.com/unit-4-221009105314-7ee685b1/75/UNIT-4-pdf-38-2048.jpg)
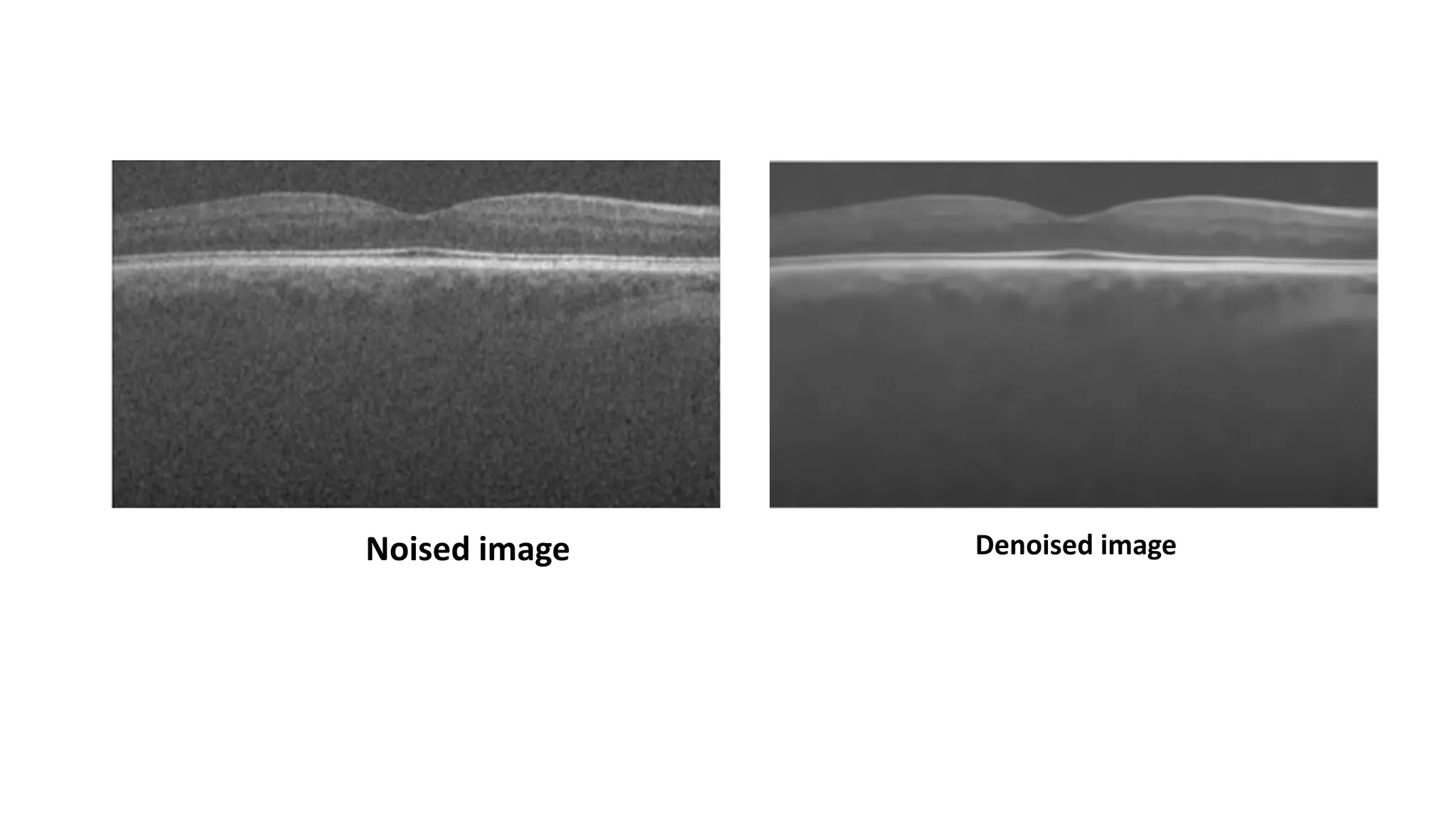
![3. Denoising Autoencoder
Now we will see how the model performs with noise in the image. What we mean by noise is blurry
images, changing the color of the images, or even white markers on the image.
noise_factor = 0.7
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
Here is how the noisy images look right now.
plt.figure(figsize=(20, 2))
for i in range(1, 5 + 1):
ax = plt.subplot(1, 5, i)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()](https://image.slidesharecdn.com/unit-4-221009105314-7ee685b1/75/UNIT-4-pdf-39-2048.jpg)

![After the training, we will provide the input and write a plot function to see the final
results.
pred = model.predict(x_test_noisy)
plt.figure(figsize=(20, 4))
for i in range(5):
# Display original
ax = plt.subplot(2, 5, i + 1)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, 5, i + 1 + 5)
plt.imshow(pred[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()](https://image.slidesharecdn.com/unit-4-221009105314-7ee685b1/75/UNIT-4-pdf-41-2048.jpg)















































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)










