Downloaded 92 times







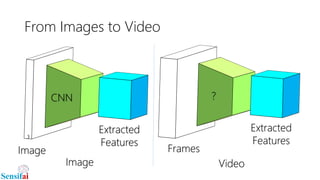
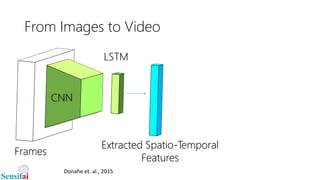
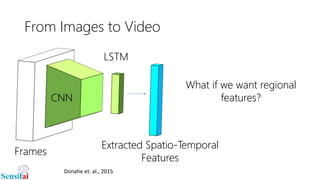
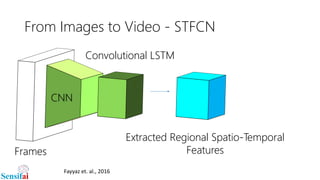
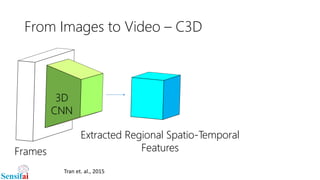

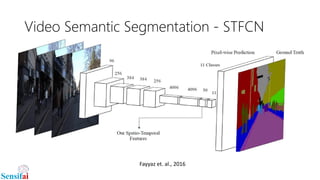

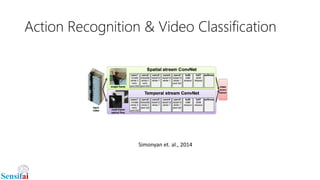

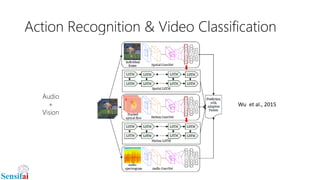



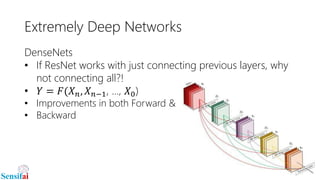


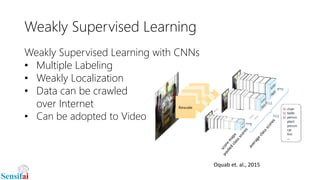

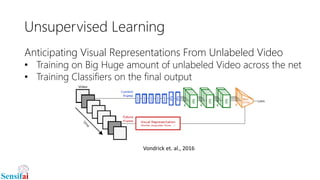



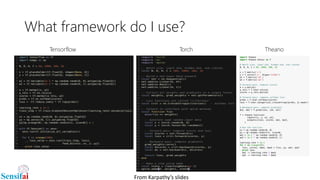



This document discusses deep learning for video processing and applications. It begins by explaining that video can be processed as batches of frames using convolutional neural networks (CNNs) and recurrent neural networks (RNNs) like LSTMs. Examples of applications that require video processing are self-driving cars using video semantic segmentation, robots using action recognition, and video tagging for YouTube. The document then reviews different deep learning architectures for video like STFCN, C3D, ResNet, and Highway Networks. It also discusses weakly supervised and unsupervised methods for video using large unlabeled datasets. The document concludes by mentioning hardware and frameworks commonly used for deep learning like TensorFlow and recommendations for distributed training.















































