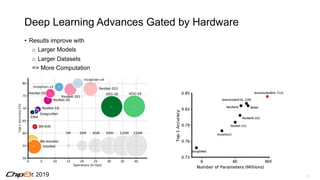
This document discusses advances in hardware that have enabled progress in artificial intelligence. It notes that deep learning advances have been gated by hardware capabilities, and that more computation is needed for larger models and datasets. Specialized hardware designs for deep learning can improve efficiency by utilizing techniques like reduced precision data types, pruning of unimportant weights, and bringing computation closer to memory. Future opportunities include non-Von Neumann architectures, memory-compute integration, and continued co-design across algorithms, architectures and circuits to most efficiently solve domain-specific problems like artificial intelligence.



![62019
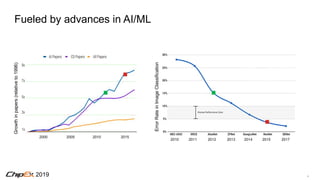
Deep Learning Advances Gated by Hardware
[Bill Dally, SysML 2018]](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-6-320.jpg)
![82019
Data Set and Model Size Scaling
[Hestess et al. Arxiv 17.12.00409]
• 256X data
• 64X model size
Þ Compute 32,000 X](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-8-320.jpg)
![92019
How Much Compute?
12 HD Cameras
Inferencing**
• 25 Million Weights
• 300 Gops for HD Image
• 9.4 Tops for 30fps
• 12 Cameras, 3 nets = 338 Tops
Training
• 30Tops x 108 (train set) x 10^2 (epochs) =
1023 Ops
**ResNet-50
[Bill Dally, SysML 2018]](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-9-320.jpg)
![102019
Challenge: End of Line for CMOS Scaling
• Device scaling down slowing
• Power Density stopped scaling in 2005
[Olukotun, Horowitz][IMEC]](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-10-320.jpg)

![122019
Energy Cost for Operations
Instruction Fetch/D 70
[Horowitz ISSCC 2014]
*45nm](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-12-320.jpg)


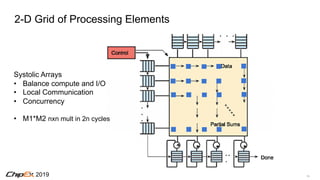
![162019
TPUv2
• 8GB + 8GB HBM
• 600 GB/s Mem BW
• 32b float
• MXU fp32 accumulation
• Reduced precision mult.
[Dean NIPS’17]](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-16-320.jpg)


![192019
Extreme Datatypes
• Q: What can we do with single bit or ternary (+a, -b, 0) representations
• A: Surprisingly, a lot. Just retrain/increase the number of activation layers
[Chenzhuo et al,, arxiv 1612.01064]
Network](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-19-320.jpg)

![212019
Quantization – How many distinct values?
16 Values => 4 bits representation
Instead of 16 fp32 numbers, store16 4-bit indices
[Han et al, 2015]](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-21-320.jpg)

![232019
Memory and inter-chip communication advances
[Graphcore 2018]
pJ
64pJ/B
16GB
900GB/s @ 60W
10pJ/B
256MB
6TB/s @ 60W
1pJ/B
1000 x 256KB
60TB/s @ 60W
Memory power density
Is ~25% of logic power density](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-23-320.jpg)
![242019
In-Memory Compute
[Ando et al., JSSC 04/18]
In-memory compute with low-bits/value, low cost ops](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-24-320.jpg)

![262019
AI Application-System Co-design
[Reagen et al, Minerva, ISCA 2016]
• Co-design across the algorithm, architecture, and circuit levels
• Optimize DNN hardware accelerators across multiple datasets](https://image.slidesharecdn.com/chipexkeynote-190520002701/85/ChipEx-2019-keynote-26-320.jpg)

















































