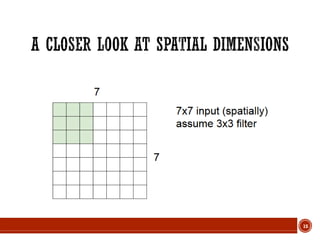
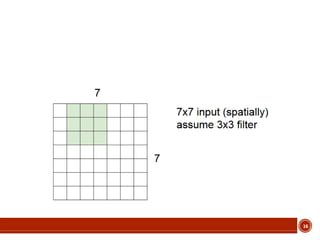
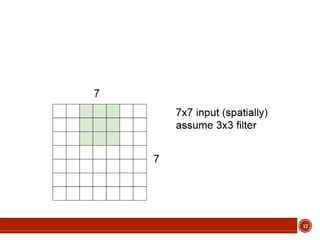
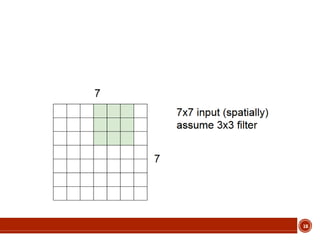
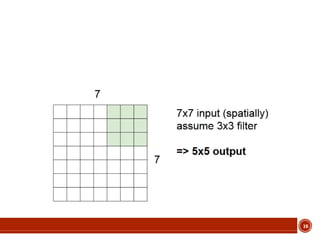
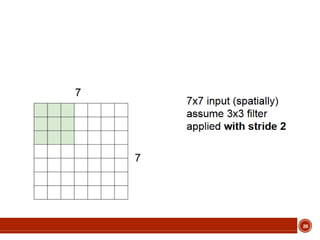
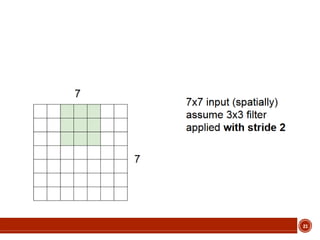
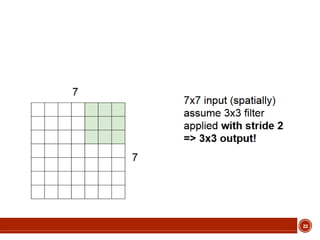
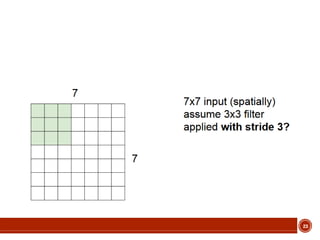
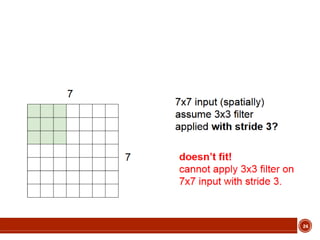
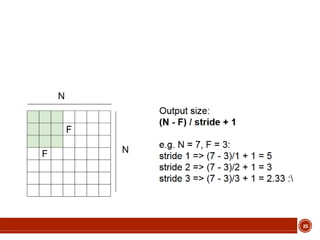
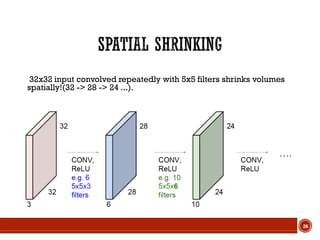
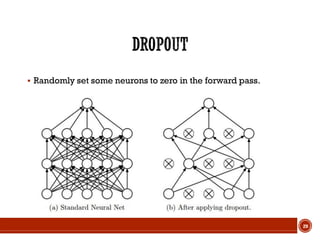
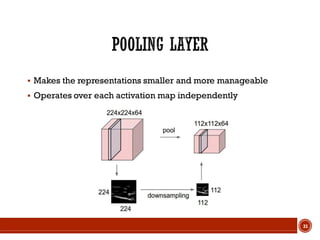
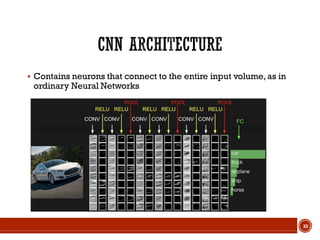
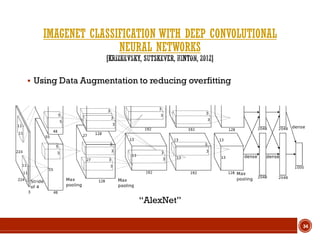
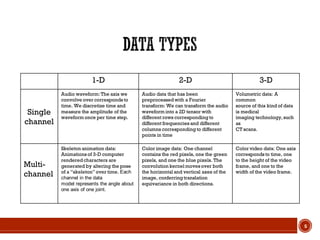
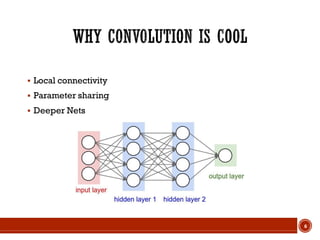
This document summarizes a presentation on deep learning given by Prof. Mohammad-R.Akbarzadeh-T at Ferdowsi University of Mashhad. The presentation was given by Hosein Mohebbi and M.-Sajad Abvisani and covered topics including convolutional neural networks, pooling, dropout, and using deep CNNs for ImageNet classification. It provided examples of 1D, 2D, and 3D data that can be used as inputs to CNNs and discussed concepts such as local connectivity, parameter sharing, and deeper networks.




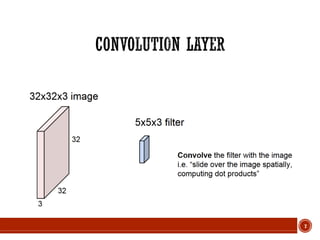
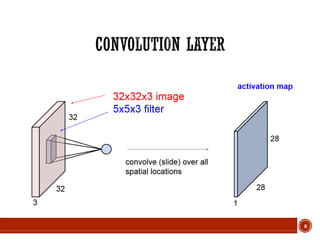
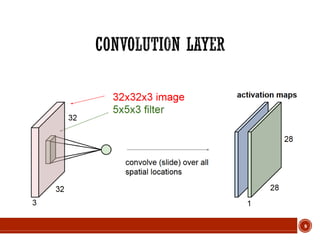

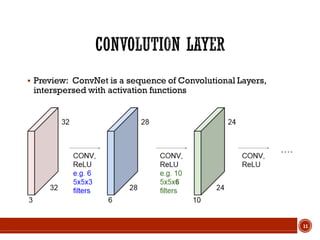

![13
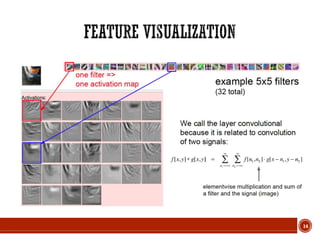
Feature visualization of convolutional net trained on ImageNet from [Zeiler & Fergus 2013]](https://image.slidesharecdn.com/deeplearning-180609194338/85/Deep-learning-13-320.jpg)