























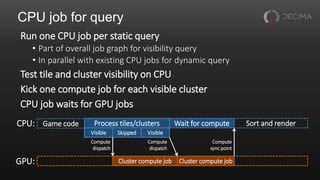
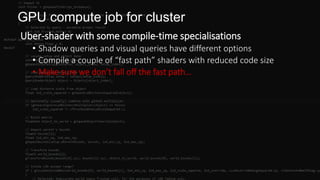



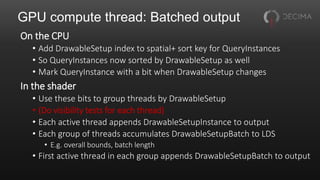
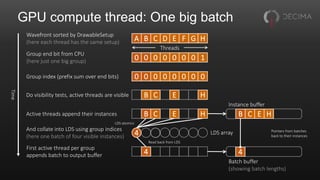
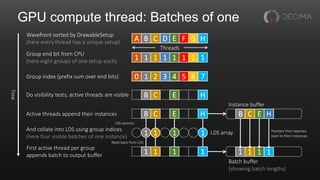
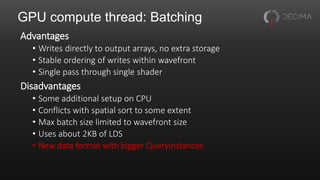
![Aside: Aggregated atomics
Compute threads often want to use global atomics
• E.g. to append to buffers, count things
Useful to aggregate these across a wavefront
• One atomic per wavefront instead of one per thread
• Saves memory traffic
• As a bonus, gives fixed append order within wavefront
Drop-in replacement for existing atomics
For more information, see [Adinetz14]](https://image.slidesharecdn.com/gcap2017decimavisibilitymodifiedfontsizefornotes-171120111828/85/Decima-Engine-Visibility-in-Horizon-Zero-Dawn-33-320.jpg)















![Reference
[Adinetz14] Optimized filtering with warp-aggregated atomics
• https://devblogs.nvidia.com/parallelforall/cuda-pro-tip-optimized-filtering-warp-aggregated-atomics/](https://image.slidesharecdn.com/gcap2017decimavisibilitymodifiedfontsizefornotes-171120111828/85/Decima-Engine-Visibility-in-Horizon-Zero-Dawn-55-320.jpg)




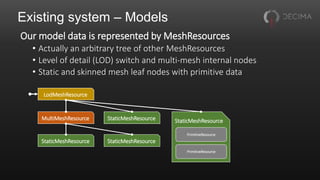
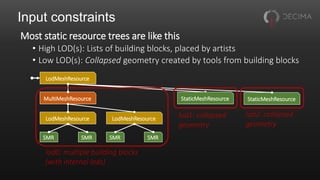
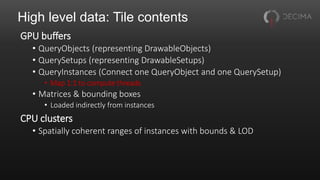
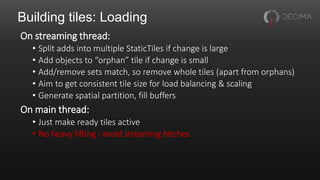
The document discusses the optimization techniques used in Horizon Zero Dawn's renderer, focusing on the management of static and dynamic content, as well as improvements to performance through spatial partitioning and parallel processing. It highlights the transition from a legacy system to a new model that efficiently handles a larger volume of content while reducing query times. Key advancements include the adoption of compute shaders for visibility queries and batching techniques that significantly enhance rendering efficiency.

































![[Unite Seoul 2019] Mali GPU Architecture and Mobile Studio](https://cdn.slidesharecdn.com/ss_thumbnails/maligpuarchitectureandmobilestudiofinal3-190717042828-thumbnail.jpg?width=640&height=640&fit=bounds)





















































