Download to read offline



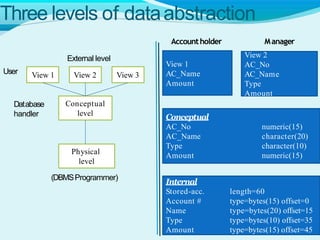

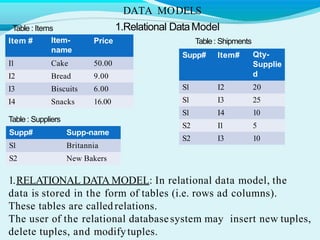
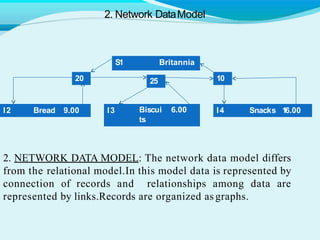



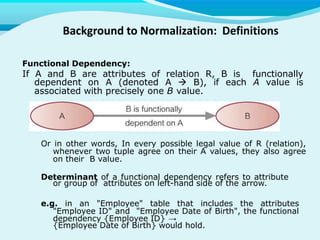





The document discusses key concepts related to databases and database management systems. It defines what a database is as a collection of organized data and what a database management system (DBMS) is as software that enables users to create, access, manage and control a database. It provides examples of common DBMS like MySQL and Microsoft Access. The document also summarizes the purpose of databases in reducing data redundancy and inconsistencies while facilitating data sharing and security. Finally, it discusses important database concepts like data models, normalization, and relational model terminology.



















































































