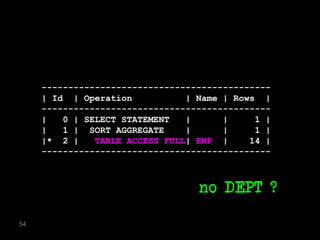
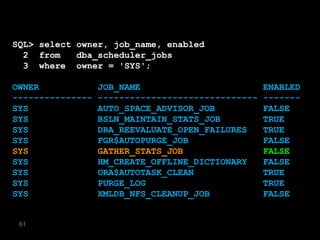
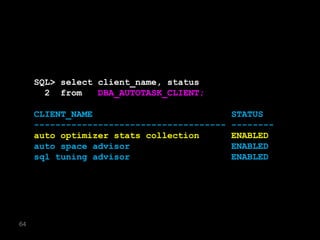
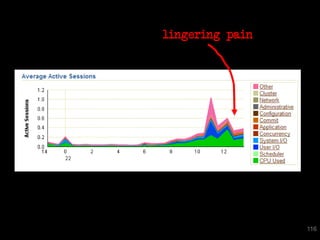
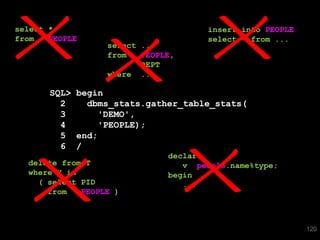
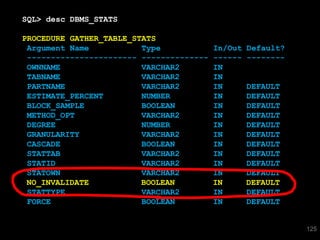
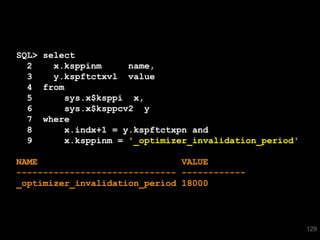
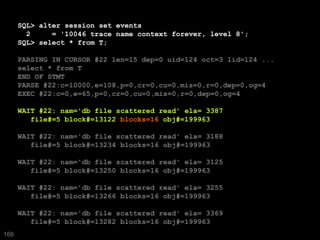
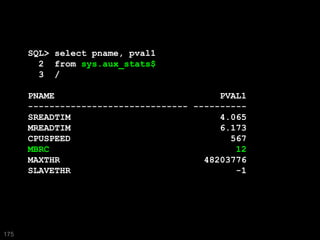
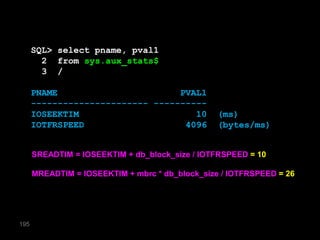
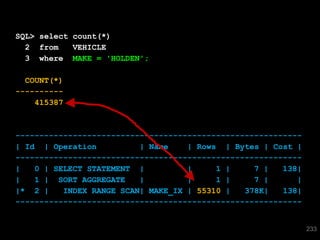
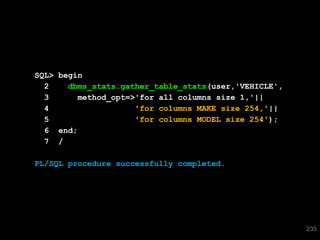
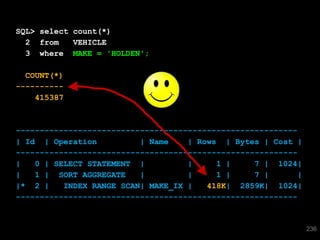
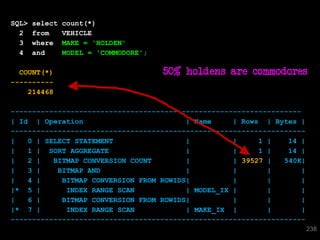
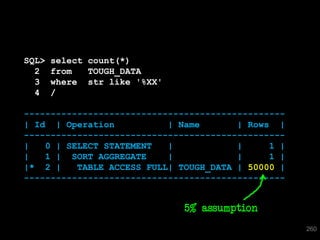
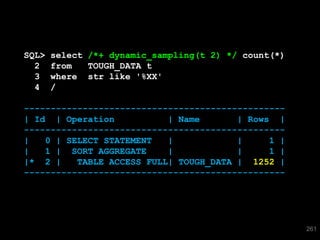
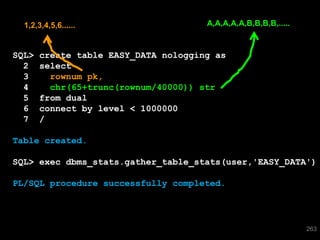
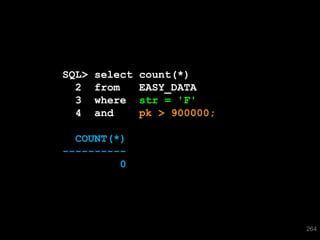
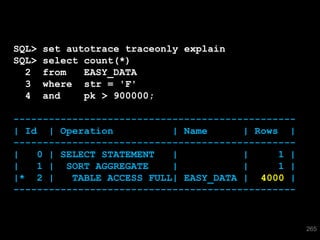
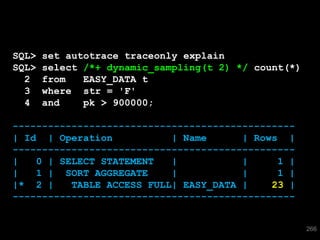
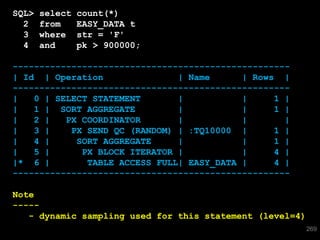
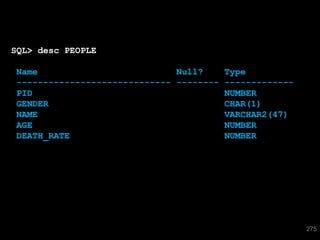
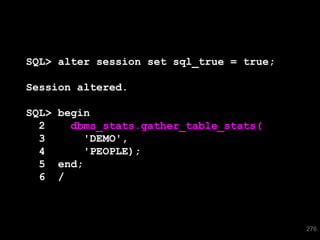
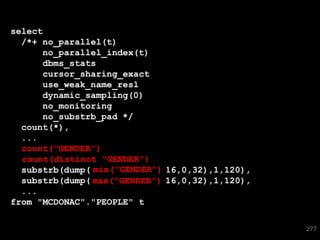
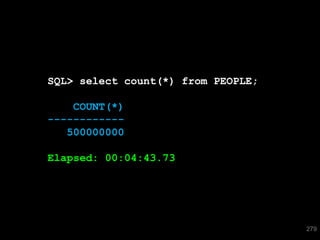
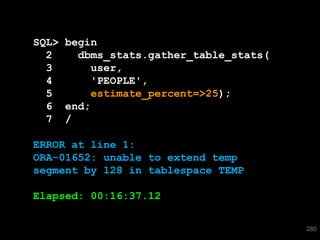
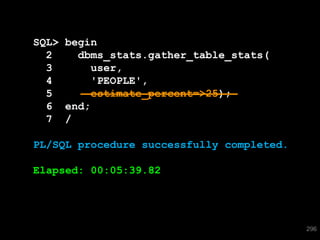
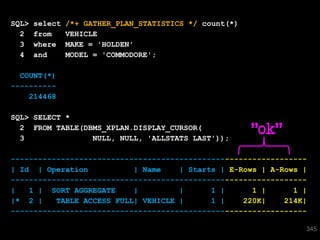
The document discusses the risks and challenges of automatically gathering statistics in an Oracle database. It notes that while gathering statistics is intended to optimize SQL performance, it can sometimes have the unintended effect of adding more expensive SQL or invalidating cached execution plans, potentially slowing performance. The recommendation is that unless database performance is known to be poor, statistics should not be changed automatically and the risks of gathering statistics outweigh the potential benefits.






















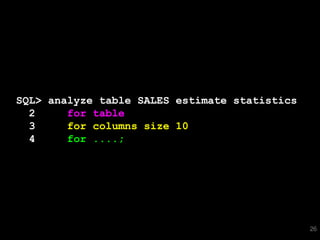





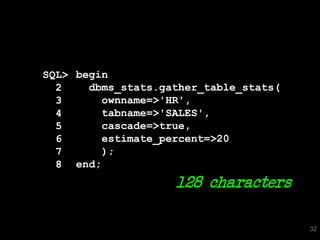




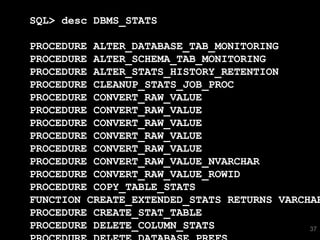















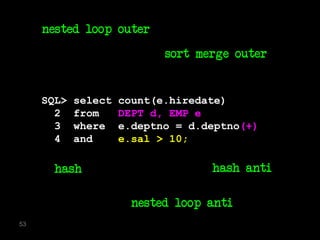




































































































































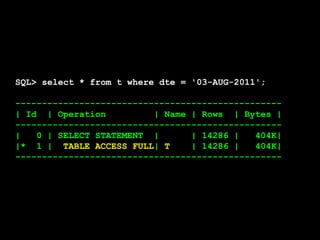






















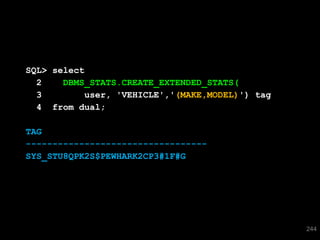
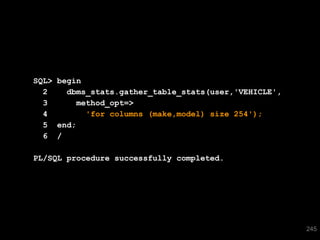
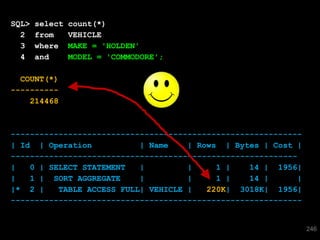











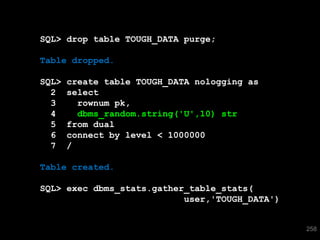














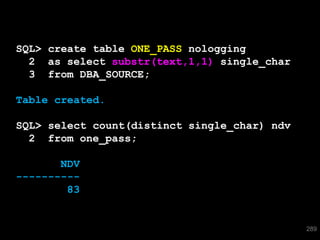


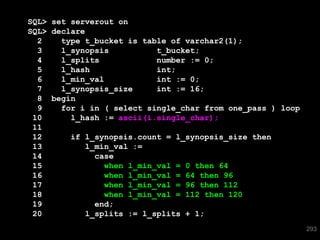
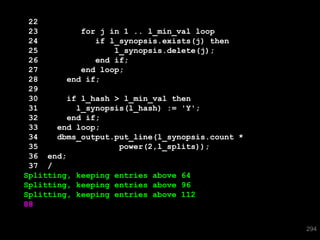













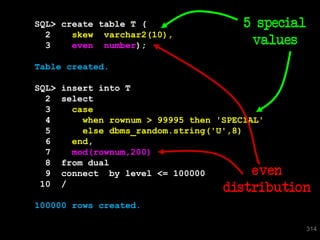
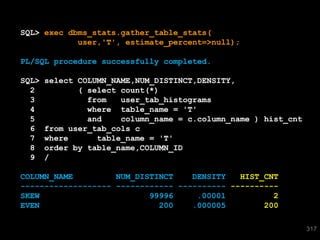
![SQL> select * from T where skew = 'SPECIAL';
SKEW VAL
---------- ----------
SPECIAL 196
SPECIAL 197
SPECIAL 198
SPECIAL 199
SPECIAL 0
5 rows selected.
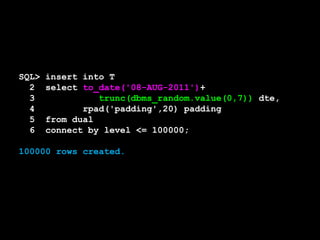
SQL> select * from T where even = 5;
TAG VAL
---------- ----------
IBRXGVIE 5
[snip]
500 rows selected.
316](https://image.slidesharecdn.com/databse-technology-2-connor-mcdonald-managing-optimiser-statistics-a-better-waypdf3745/85/Databse-Technology-2-Connor-McDonald-Managing-Optimiser-Statistics-A-better-way-pdf-316-320.jpg)

















































































![[INSIGHT OUT 2011] A15 how to design optimal sql(jonathan lewis)](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011a15howtodesignoptimalsqljonathanlewis-111114180713-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























