Downloaded 16 times


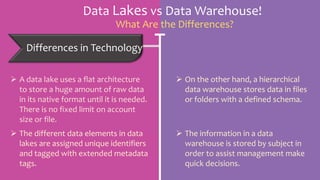


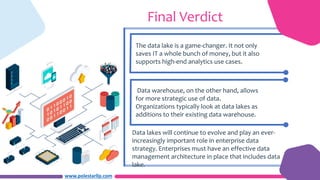

The document discusses the differences between data lakes and data warehouses, highlighting their distinct architectures, use cases, and accessibility. Data lakes allow for the storage of raw data and experimentation, primarily catering to data scientists, while data warehouses store structured data for business users seeking refined insights. Ultimately, organizations see data lakes as complementary to data warehouses, as they evolve to become crucial in enterprise data management strategies.










































































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)







