Download as PDF, PPTX




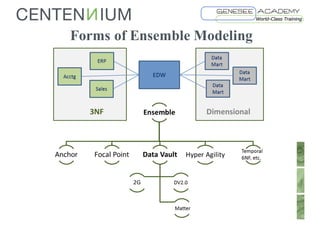






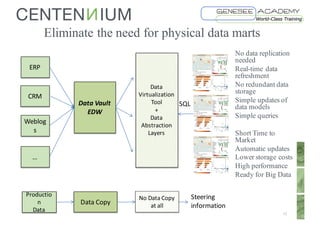
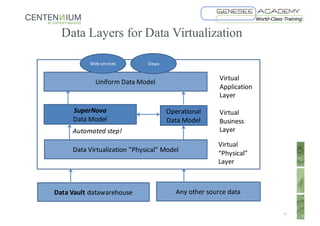








This document discusses Data Vault fundamentals and best practices. It introduces Data Vault modeling, which involves modeling hubs, links, and satellites to create an enterprise data warehouse that can integrate data sources, provide traceability and history, and adapt incrementally. The document recommends using data virtualization rather than physical data marts to distribute data from the Data Vault. It also provides recommendations for further reading on Data Vault, Ensemble modeling, data virtualization, and certification programs.







































































![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)















