Download to read offline

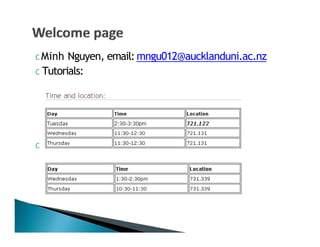








This document discusses floating point numbers and how they are represented in computers using binary rather than decimal. It notes that floating point numbers are approximations and certain calculations may result in numbers like 0.999999999 instead of the expected 1. This is due to the limitations of binary representation. It then explains how floating point numbers use a significand and exponent to represent a wide range of values with limited precision. Finally, it provides some examples of converting between decimal and IEEE 754 single-precision floating point format.























































![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)