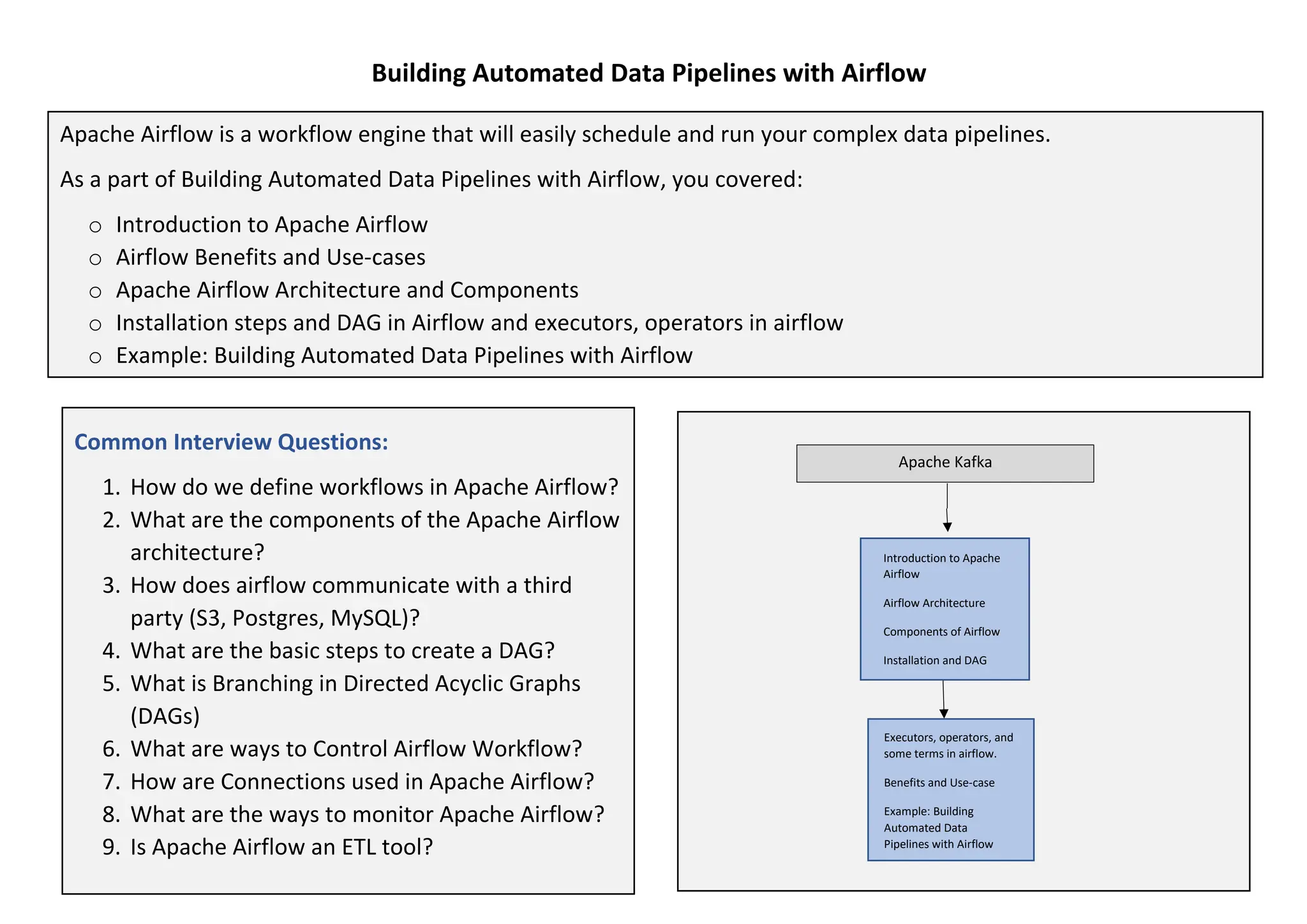
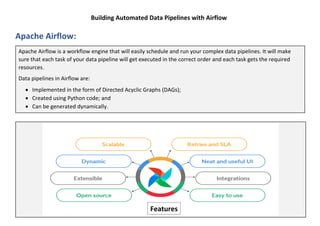
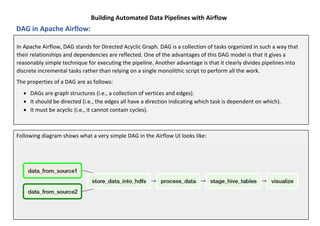
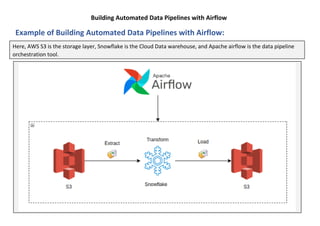
The document provides a comprehensive guide to building automated data pipelines using Apache Airflow, covering its architecture, components, and installation steps. It highlights key features, benefits, and use cases, including ETL processes and machine learning tasks, while detailing operators, executors, and the concept of directed acyclic graphs (DAGs). Additionally, it includes common interview questions and examples of code for implementing workflows.