Downloaded 27 times



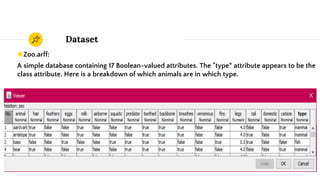



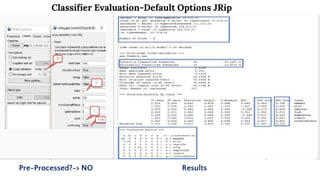

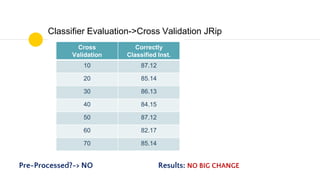




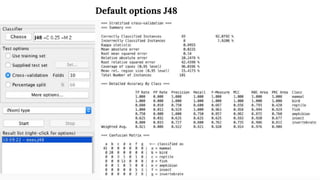


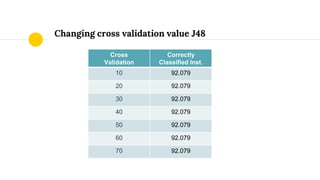


The presentation discusses data analysis using the Weka zoo.arff dataset, which contains 17 boolean-valued attributes with a focus on the 'type' class attribute. It covers dataset visualization, pre-processing techniques for handling incomplete, noisy, and inconsistent data, and evaluates classifiers such as J48 and JRip using cross-validation methods. The findings suggest that while different classifiers yield various results, pre-processing is essential for improving data quality before classification.














































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)
































