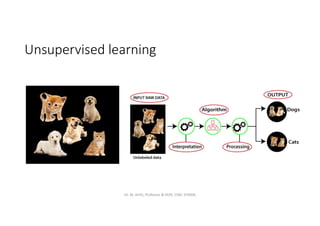
This document provides an introduction to unsupervised learning and clustering algorithms. It discusses how unsupervised learning is used to find patterns in unlabeled data. Clustering algorithms are introduced as a common unsupervised learning technique that groups similar data points together. Specific clustering algorithms covered include k-means, k-medoids, hierarchical clustering, density-based clustering, and grid-based clustering. The document also compares the k-means and k-medoids partitioning clustering algorithms.












































![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)



















![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)




















