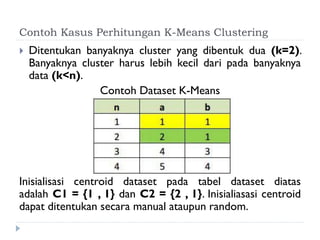
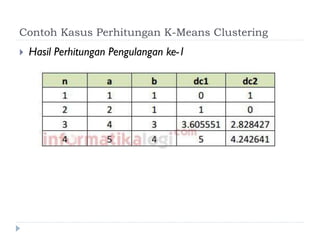
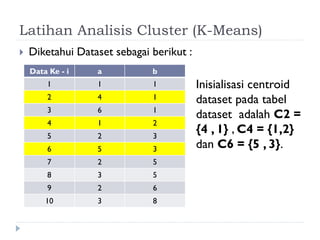
Dokumen ini membahas tentang algoritma k-means yang digunakan untuk analisis cluster dalam data mining. Algoritma ini dapat mengelompokkan data berdasarkan atribut tertentu ke dalam sejumlah cluster dengan meminimalisasi variasi intra-cluster dan memaksimalkan variasi inter-cluster. K-means adalah metode unsupervised yang memerlukan inisialisasi centroid dan memiliki sensitivitas terhadap pembangkitan centroid awal.






















![[Pk] pertemuan 12 Decision Tree](https://cdn.slidesharecdn.com/ss_thumbnails/pkpertemuan10-decisiontree-190514092121-thumbnail.jpg?width=640&height=640&fit=bounds)
























































