Download to read offline












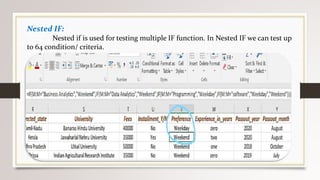

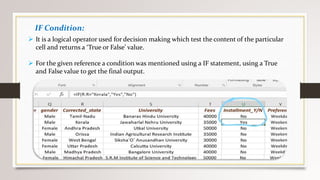
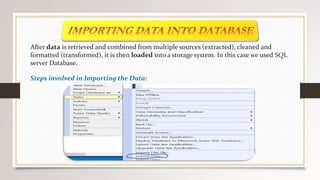
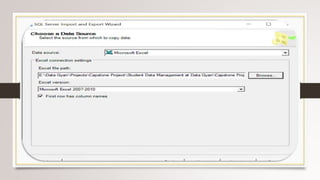

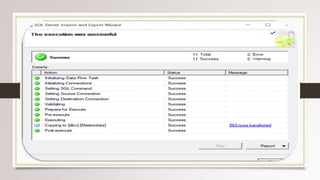

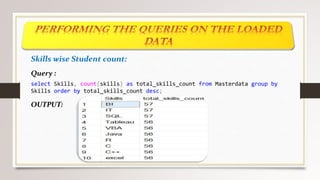
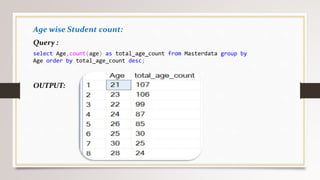

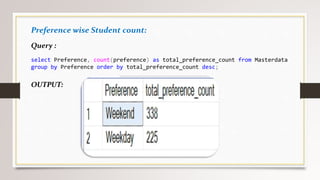

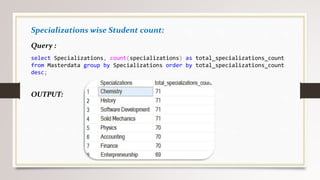


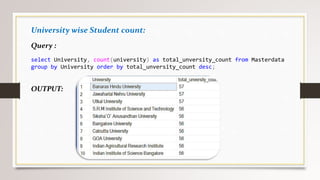
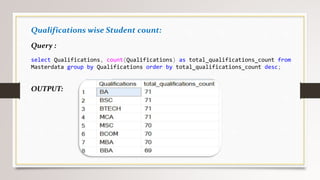
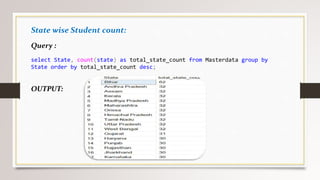
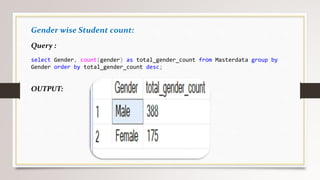
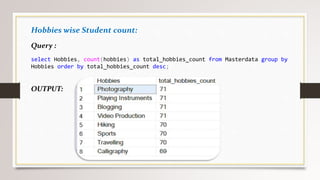

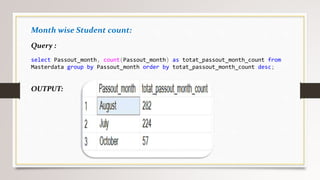







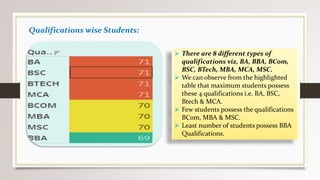
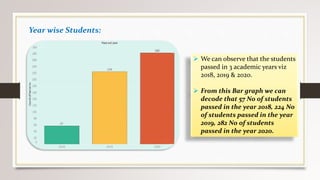
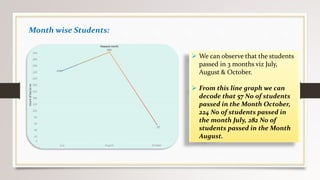

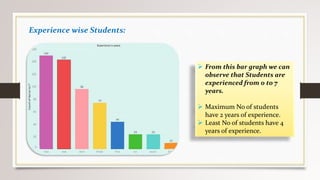

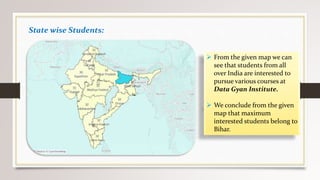




This document describes a project to collect student data from various internal and external sources, cleanse the data, load it into a SQL database, and perform analysis. Key points: - Student data was collected from the firm and sources like LinkedIn, Facebook, and Naukri. It was cleansed and merged into a master Excel file. - The cleansed data was then loaded into a SQL Server database using import functions. - Queries were written to analyze the data, such as counts of students by skills, age, fees, and other attributes. - The goal is to gain insights from the data to help the management team make decisions around areas to focus, courses to offer,


































































