This document analyzes a dataset containing sensor data to evaluate the predictive power of each sensor. It first imports necessary packages and loads the dataset. Various analyses are then performed, including checking for null values, descriptive statistics, and correlation. Two approaches are taken: 1) using log loss to rank the sensors based on predictive accuracy, and 2) using linear discriminant analysis (LDA) to also rank the sensors. Both approaches yield similar results, with sensors 8, 4, and 0 found to be most predictive. Strengths, weaknesses, and scalability of the methods are discussed. Suggestions are made to use log loss due to its optimization properties.
![3.2) Statistical understanding of dataset
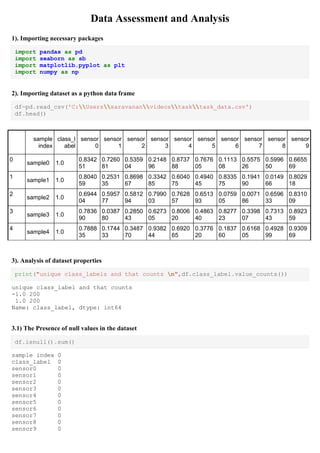
df.describe(include="all")
sampl
e
index
class_l
abel
sensor
0
sensor
1
sensor
2
sensor
3
sensor
4
sensor
5
sensor
6
sensor
7
sensor
8
sensor
9
count
400
400.00
0000
400.00
0000
400.00
0000
400.00
0000
400.00
0000
400.00
0000
400.00
0000
400.00
0000
400.00
0000
400.00
0000
400.00
0000
unique 400 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
top sampl
e98
NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
freq 1 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
mean
NaN
0.0000
00
0.5236
61
0.5092
23
0.4812
38
0.5097
52
0.4978
75
0.5010
65
0.4904
80
0.4823
72
0.4828
22
0.5419
33
std
NaN
1.0012
52
0.2681
94
0.2768
78
0.2875
84
0.2977
12
0.2882
08
0.2876
34
0.2899
54
0.2827
14
0.2961
80
0.2724
90
min
NaN
-
1.0000
00
0.0077
75
0.0038
65
0.0044
73
0.0014
66
0.0002
50
0.0004
25
0.0001
73
0.0033
22
0.0031
65
0.0004
52
25%
NaN
-
1.0000
00
0.2997
92
0.2830
04
0.2355
44
0.2626
97
0.2493
69
0.2694
30
0.2266
87
0.2428
48
0.2136
26
0.3212
64
50%
NaN
0.0000
00
0.5349
06
0.5075
83
0.4602
41
0.5100
66
0.4978
42
0.4971
08
0.4773
41
0.4634
38
0.4622
51
0.5783
89
75%
NaN
1.0000
00
0.7518
87
0.7278
43
0.7349
37
0.7689
75
0.7434
01
0.7388
54
0.7353
04
0.7324
83
0.7405
42
0.7689
90
max
NaN
1.0000
00
0.9994
76
0.9986
80
0.9929
63
0.9951
19
0.9994
12
0.9973
67
0.9971
41
0.9982
30
0.9960
98
0.9994
65
3.3) Define Predictor_variables and Target_variable
predictor_variables=df[['sensor0', 'sensor1', 'sensor2','sensor3', 'sensor4',
'sensor5', 'sensor6', 'sensor7', 'sensor8', 'sensor9']]
target_variable=df[['class_label']]
3.4) Variance of predictor_variables data
print("variance of all sensorsnn",np.var(predictor_variables))
variance of all sensors
sensor0 0.071748
sensor1 0.076470
sensor2 0.082498
sensor3 0.088411
sensor4 0.082856
sensor5 0.082527
sensor6 0.083863
sensor7 0.079727
sensor8 0.087503
sensor9 0.074065](https://image.slidesharecdn.com/dataassessmentandanalysis-190923065820/85/Data-Assessment-and-Analysis-for-Model-Evaluation-2-320.jpg)
![3.5) Probability distributions of the predictor_variables data
sensors=predictor_variables.keys()
for i in range(0,len(predictor_variables.keys())):
k=sensors[i]
sb.distplot(predictor_variables[""+k+""],label=""+k+"",hist=False)
3.6) Correlation analysis of Predictor_variables data
sb.heatmap(predictor_variables.corr())](https://image.slidesharecdn.com/dataassessmentandanalysis-190923065820/85/Data-Assessment-and-Analysis-for-Model-Evaluation-3-320.jpg)
![4) Properties of dataset:
1) Our dataset have 12 features with 400 observations.
2) It have one class_label that have either 1 or -1 with each class have equal samples like 200,200.
3) It's don't have any null values.
4) All predictor_variables data start with 0 and end with 1.
5) All predictor_variables data almost 95% normally distributed and also all variables have homogeneity of variance.
6) All predictor_variables are not highly correlated with each one.
5) Assumptions and process of thoughts:
I am going to provide solutions with two approaches.
Approach 1
1) Log loss
Our dataset predictor_variables data start with 0 and end with 1 continuously.
And our class_label (target_variable) have 1 and -1. So, based on those format it’s exactly look like sigmoid
model outputs. If we want to know each sensor performance or predictive power, we can apply log loss metric to
evaluate predictive power of each sensors.
Log loss is the best metrics for binary evolution models / sigmoid function model (logistic or probit
regression) because it will tell the exact loss value of each predicted value. In the sense we can know exact
predictive power of binary model using log loss metric.
Note:
Xi means already predicted values and Y means actual values I derived formula for our problem of case
scenario.
Y = Target_variable (class_label)
Xi …n = Predictor_variables (sensor0, sensor1...n)
n = Number of observations
Log_loss = [(Y * log(Xi)) + ((1-Y) * log(1-X1i))]
Avg_log_loss = [(-1/n)* sum(Log_loss)]](https://image.slidesharecdn.com/dataassessmentandanalysis-190923065820/85/Data-Assessment-and-Analysis-for-Model-Evaluation-4-320.jpg)





















![[M4A2] Data Analysis and Interpretation Specialization](https://cdn.slidesharecdn.com/ss_thumbnails/m4a2assignment-170709175530-thumbnail.jpg?width=640&height=640&fit=bounds)



















![PPT-HEART-DISEASE[1].pptx presentationss](https://cdn.slidesharecdn.com/ss_thumbnails/ppt-heart-disease1-250901140846-bb7a7155-thumbnail.jpg?width=640&height=640&fit=bounds)



















![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









