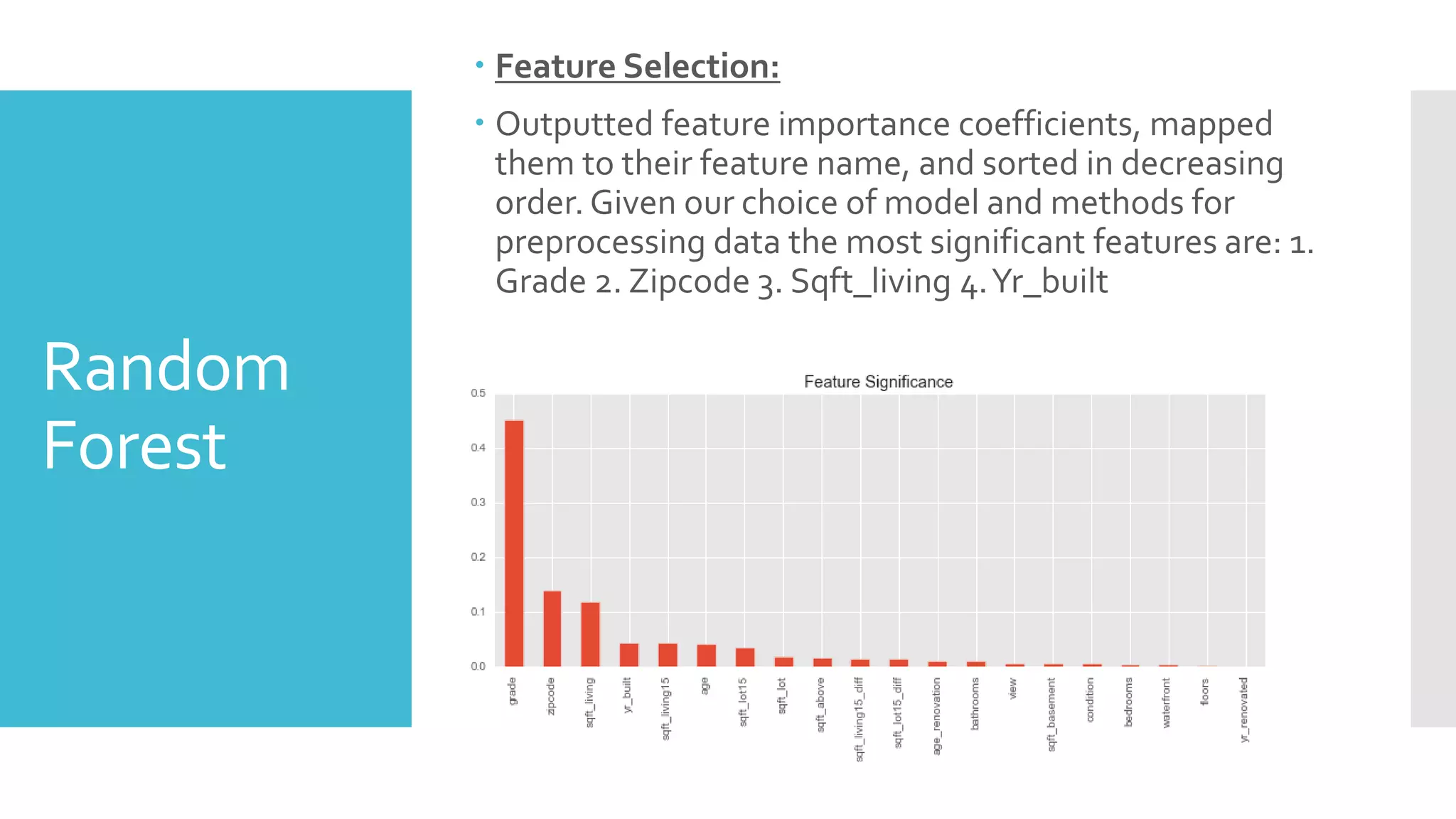
The document provides an overview of different machine learning algorithms used to predict house sale prices in King County, Washington using a dataset of over 21,000 house sales. Linear regression, neural networks, random forest, support vector machines, and Gaussian mixture models were applied. Neural networks with 100 hidden neurons performed best with an R-squared of 0.9142 and RMSE of 0.0015. Random forest had an R-squared of 0.825. Support vector machines achieved 73% accuracy. Gaussian mixture modeling clustered homes into three groups and achieved 49% accuracy.








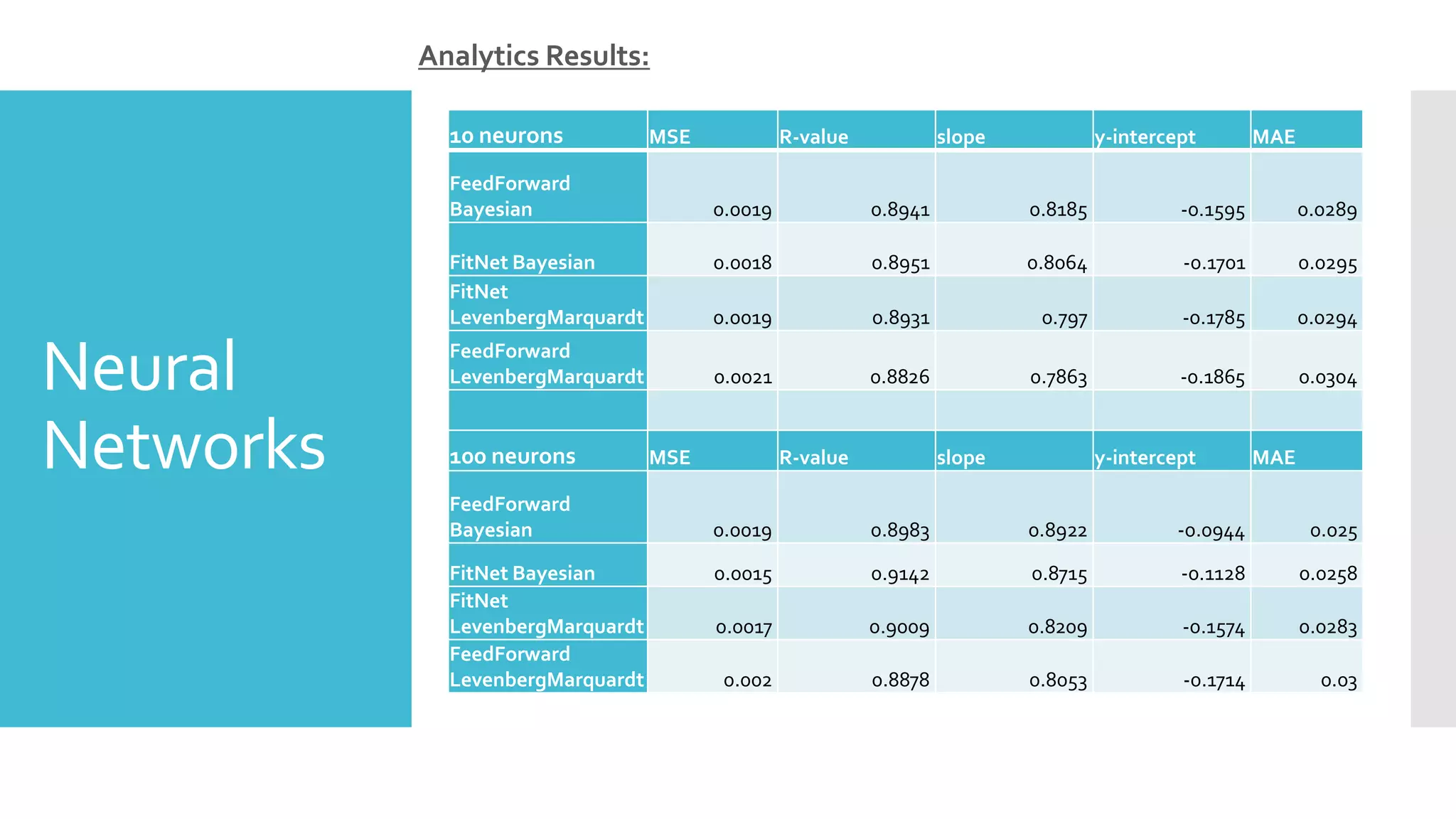
![Neural
Networks
Used Matlab’s built in functions: fitnet and feedforwardnet
Tried two different methods: Levenberg-Marquardt and Bayesian
Normalized with mapminmax to scale the targets, where the
output of the network will be trained to produce outputs in the
range [–1,+1]
Started with 1 hidden layer and 10 neurons.
Ran each combination again with 100 hidden neurons to
determine which one would perform better.](https://image.slidesharecdn.com/26b0727b-0c56-410c-8588-6f532a9717b9-161210152600/75/House-Sale-Price-Prediction-9-2048.jpg)














![Algorithm
Comparisons
Gaussian Mixture Model:
Accuracy = 0.49
Negative Log-Likelihood = 6.85e+04 = 68544
SupportVector Machine:
Accuracy= 0.73
AUC :[0.86 58,0.5426,0.20]
Classification/Clustering Algorithms:
Class 1 Class 2 Class 3
Recall 0.65 0.58 0.08
Precision 0.35 0.59 0.56
AUC 0.7176 0.5517 0.7943](https://image.slidesharecdn.com/26b0727b-0c56-410c-8588-6f532a9717b9-161210152600/75/House-Sale-Price-Prediction-26-2048.jpg)
















































