Downloaded 30 times





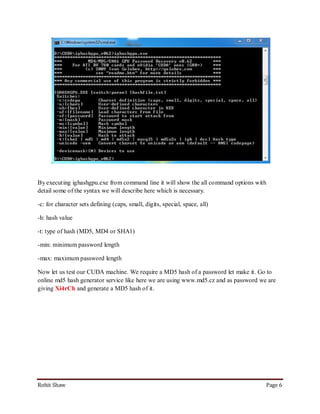
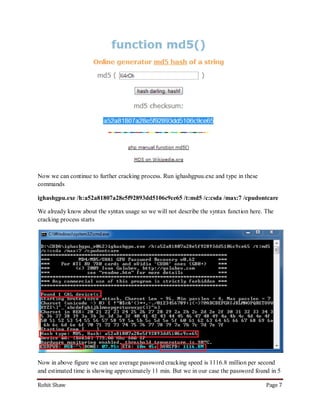
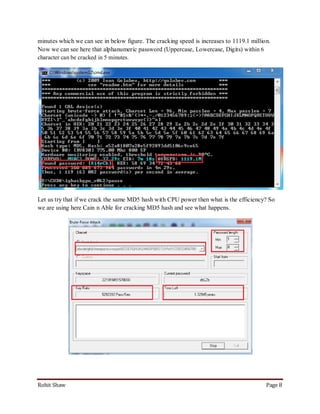


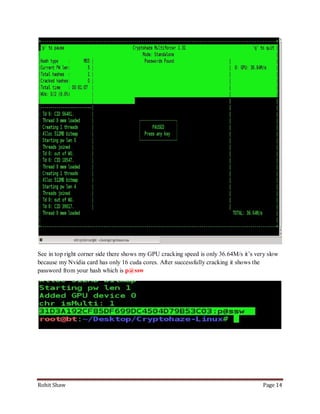



This document discusses using graphics processing units (GPUs) to crack passwords through CUDA cracking. It provides instructions on building a CUDA machine with multiple GPUs, selecting GPUs with many CUDA cores for best performance, and describes several password cracking tools that support GPU acceleration on Windows and Linux operating systems. Examples are given demonstrating that GPU cracking can crack a simple MD5 hash hundreds of times faster than CPU-only cracking.



























































