2014-04-23 2 윤석준(icysword@nate.com)
이 발표에서 다루는 것
1. 병렬 프로그래밍의 이해
2. 병렬 프로그래밍 기법
2.1. Core 내부 병렬 프로그래밍
2.2. Thread 병렬 프로그래밍
2.3. Process 병렬 프로그래밍
2.4. GPGPU를 이용한 병렬 프로그래밍
3. CUDA 란 ?
4. CUDA 적용 사례
5. 최근 병렬화 이슈
6. 질의 및 응답
3.
2014-04-23 3 윤석준(icysword@nate.com)
Moore의 법칙
마이크로칩의 처리 능력이 18개월마다 2배로 늘어난다
CO-FOUNDER, INTEL
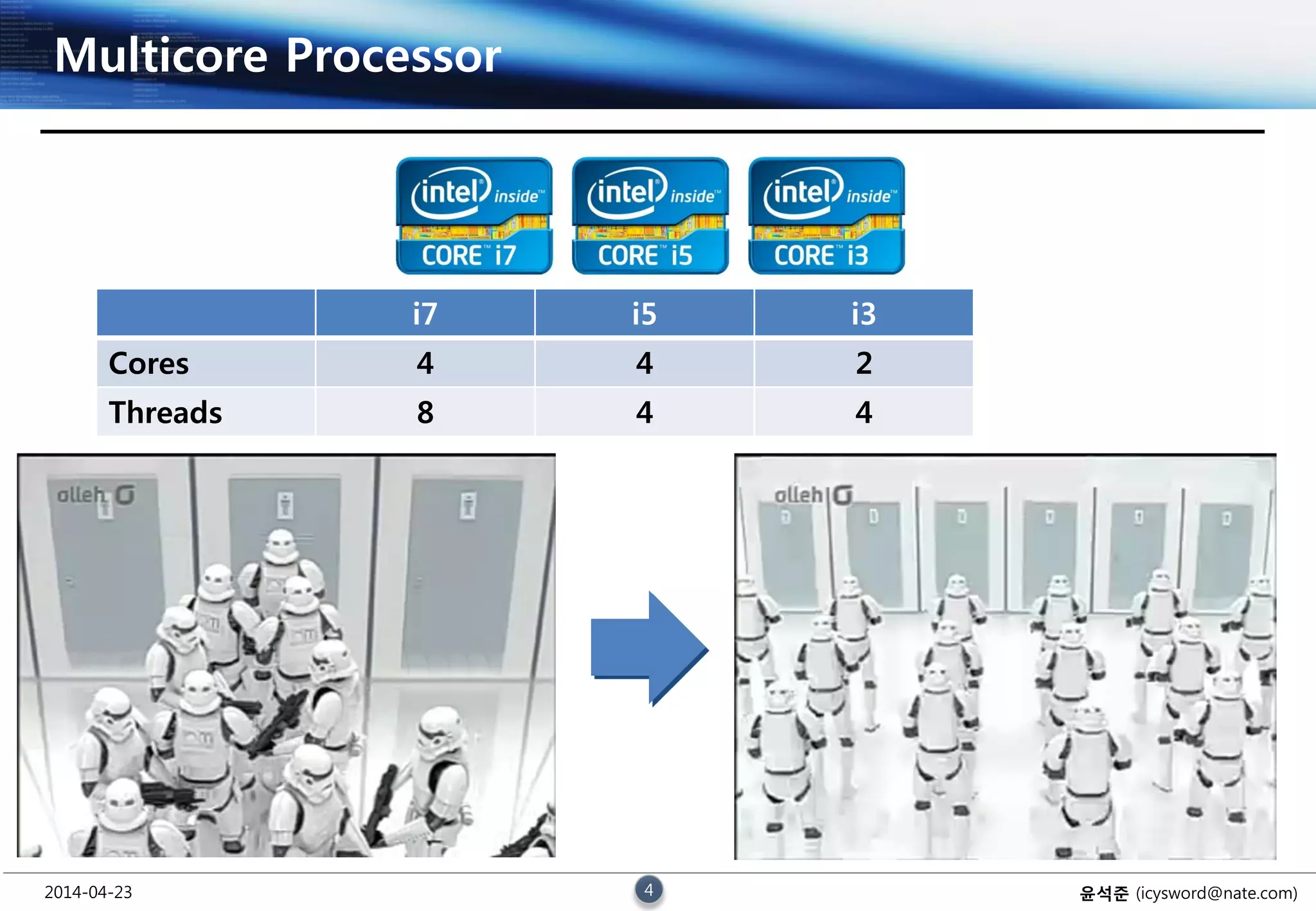
Intel Core i3 / i5 / i7
2010년 1월 Clarkdale 기준
- i3 : 3.3 GHz
- i5 : 3.6 GHz
- i7 : 3.2 GHz
2014년 2월 현재 Haswell 기준
- i3 : 2.4 GHz
- i5 : 2.9 GHz
- i7 : 3.3 GHz
2014-04-23 5 윤석준(icysword@nate.com)
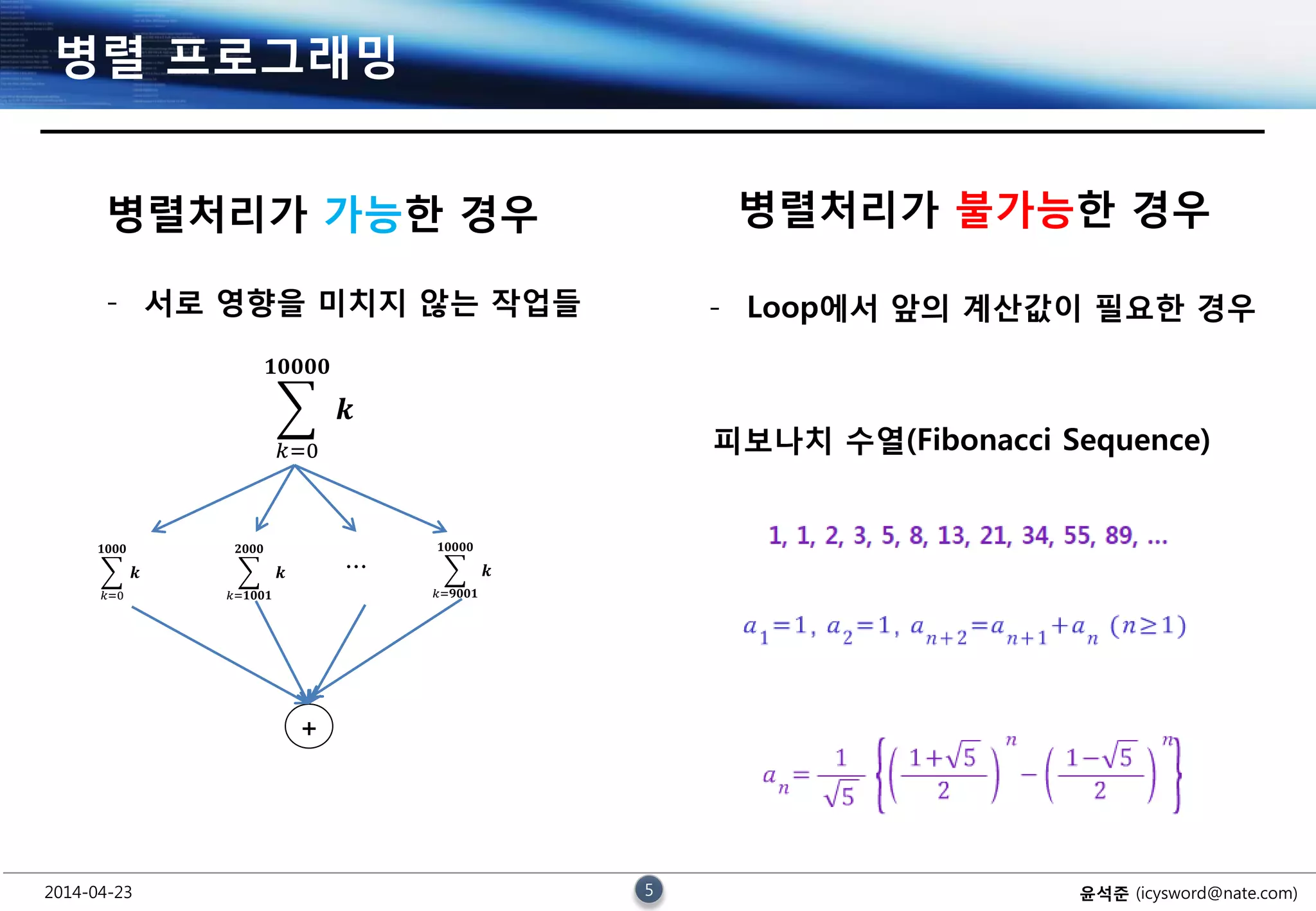
병렬 프로그래밍
𝒌
𝟏𝟎𝟎𝟎𝟎
𝑘=0
병렬처리가 가능한 경우
- 서로 영향을 미치지 않는 작업들
𝒌
𝟏𝟎𝟎𝟎
𝑘=0
𝒌
𝟐𝟎𝟎𝟎
𝑘=𝟏𝟎𝟎𝟏
𝒌
𝟏𝟎𝟎𝟎𝟎
𝑘=𝟗𝟎𝟎𝟏
…
+
병렬처리가 불가능한 경우
- Loop에서 앞의 계산값이 필요한 경우
피보나치 수열(Fibonacci Sequence)
6.
2014-04-23 6 윤석준(icysword@nate.com)
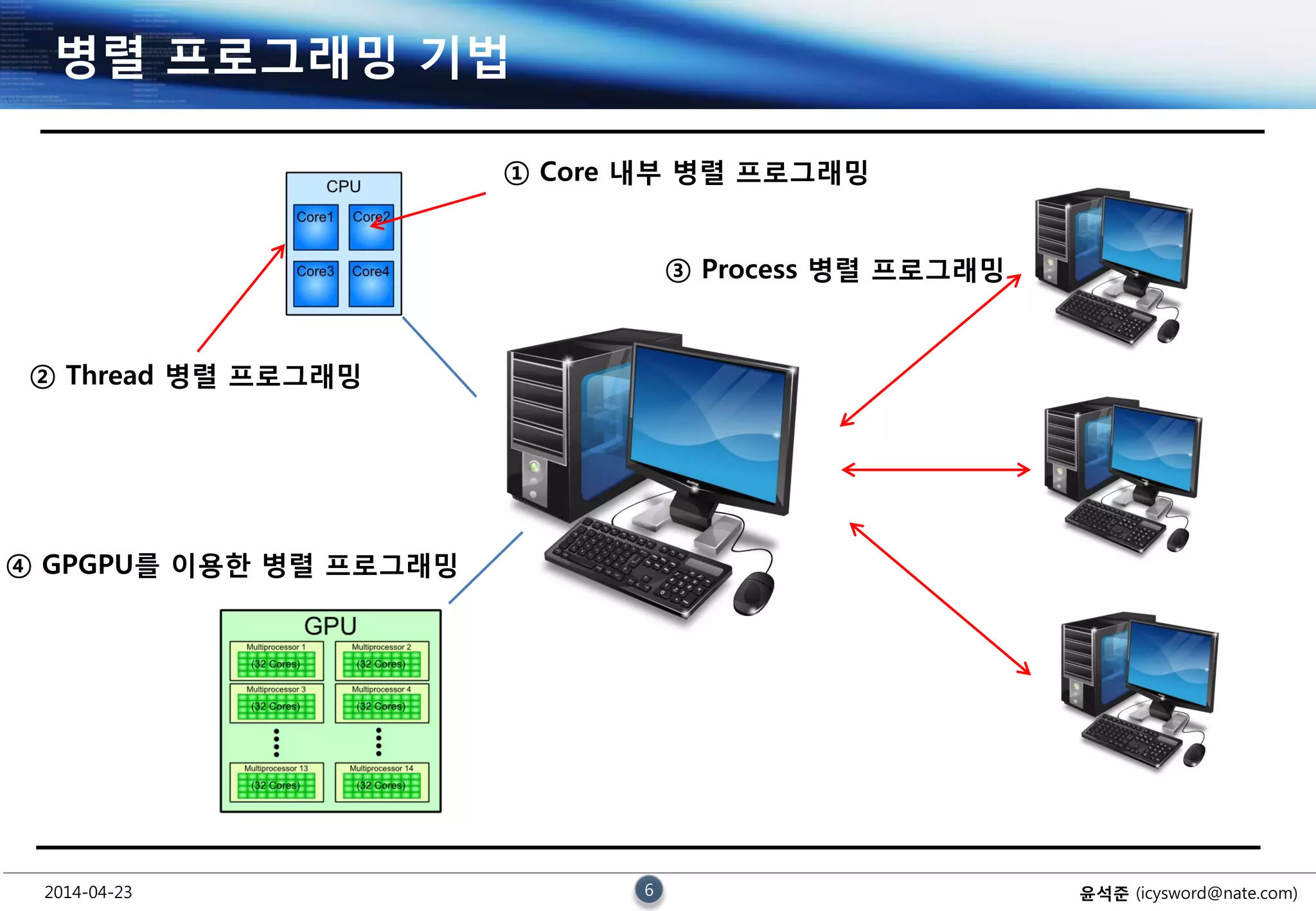
병렬 프로그래밍 기법
① Core 내부 병렬 프로그래밍
② Thread 병렬 프로그래밍
③ Process 병렬 프로그래밍
④ GPGPU를 이용한 병렬 프로그래밍
7.
2014-04-23 7 윤석준(icysword@nate.com)
Core 내부 병렬 프로그램
SIMD
(Single Instruction Multiple Data)
int a = 1 + 2;
int b = 3 + 4;
int c = 5 + 6;
int d = 7 + 8;
SISD
1 2a = +
3 4b = +
5 6c = +
7 8d = +
SIMD
1 3 5 7 2 4 6 8= +a b c d
• 기본적인 사칙 연산만 가능
• 별도의 Memory 할당 필요
• 제한된 Registor 개수
8.
2014-04-23 8 윤석준(icysword@nate.com)
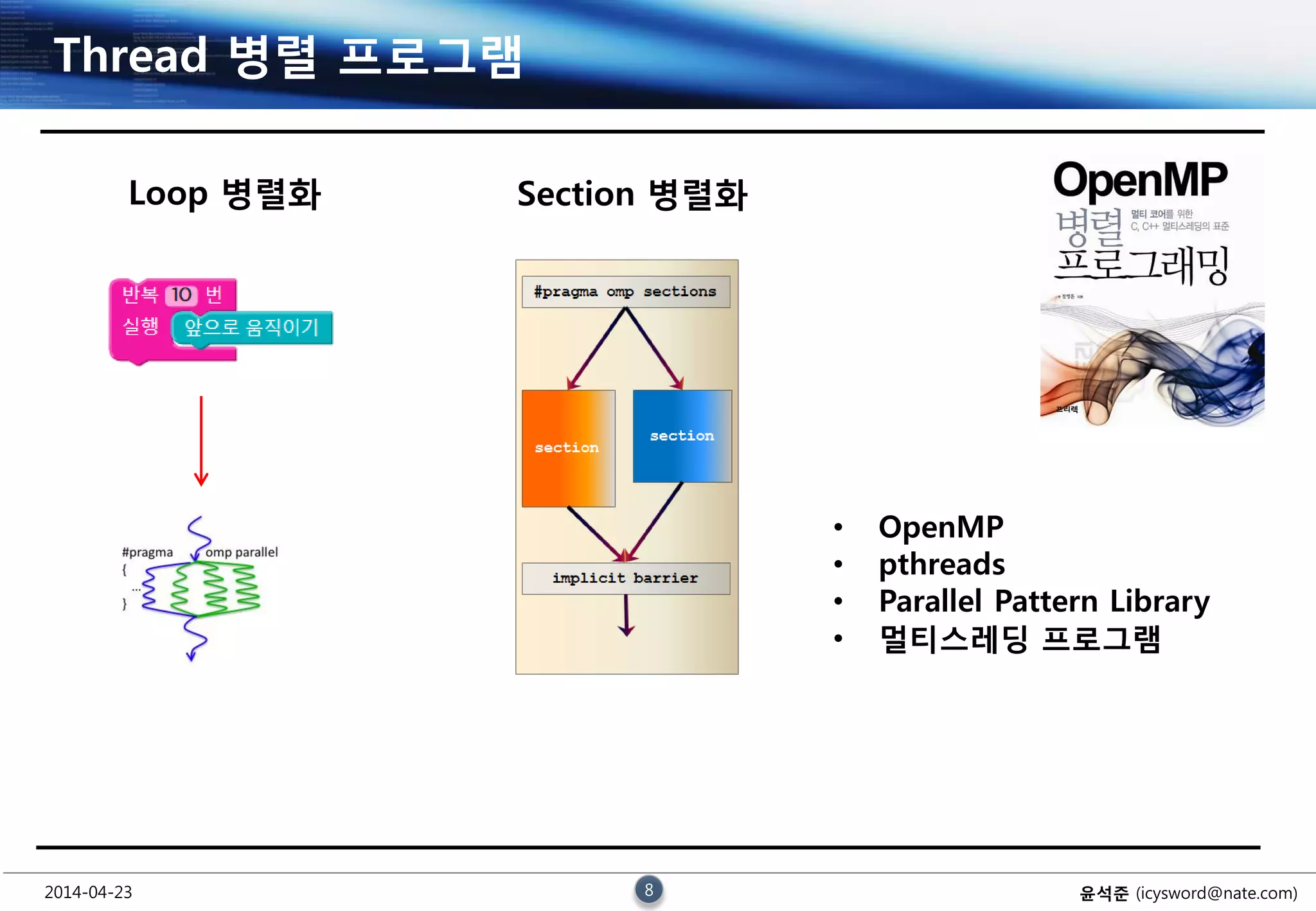
Thread 병렬 프로그램
• OpenMP
• pthreads
• Parallel Pattern Library
• 멀티스레딩 프로그램
Loop 병렬화 Section 병렬화
9.
2014-04-23 9 윤석준(icysword@nate.com)
Process 병렬 프로그램
• MPI
• HPF
• PVM
2014-04-23 11 윤석준(icysword@nate.com)
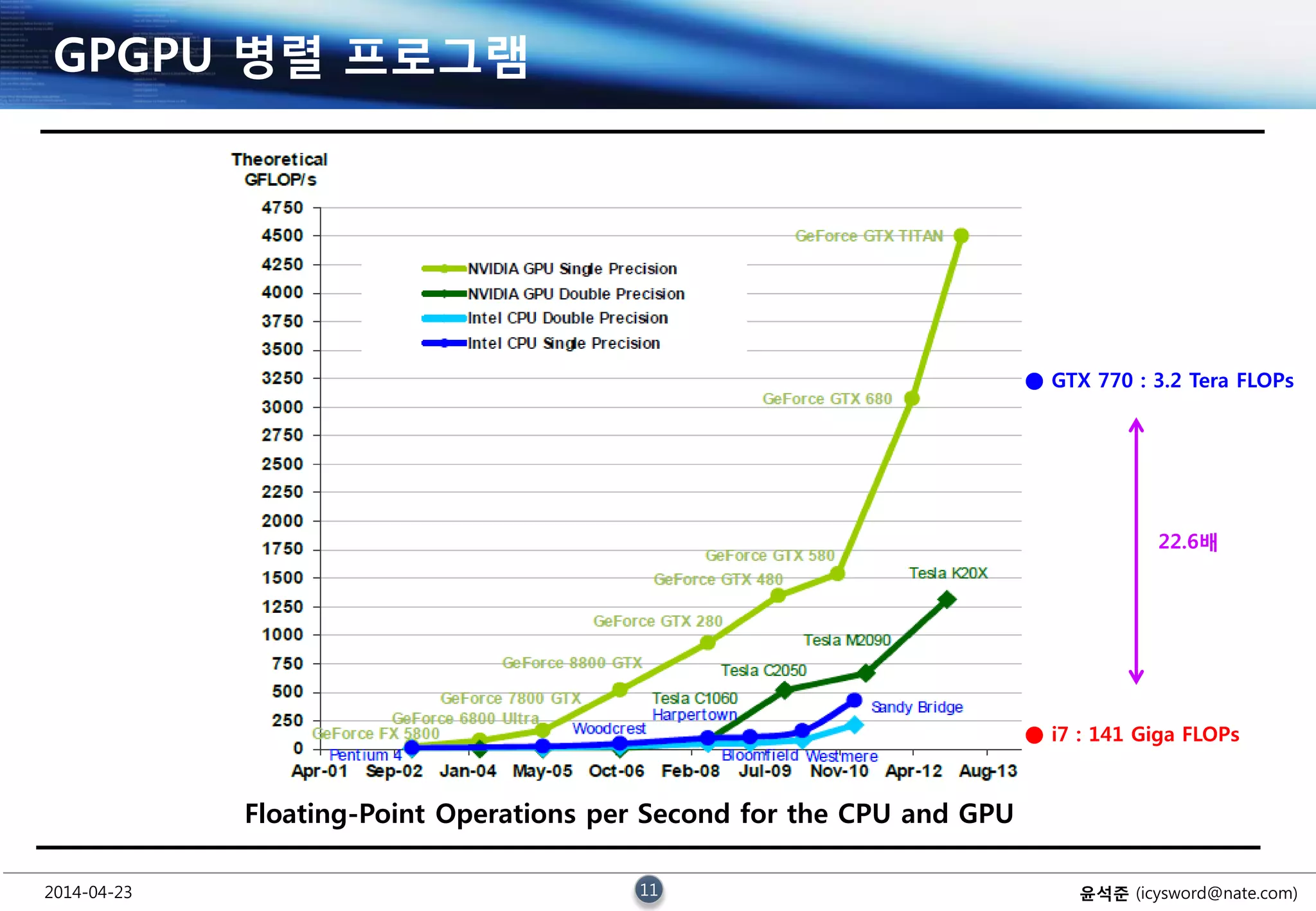
GPGPU 병렬 프로그램
Floating-Point Operations per Second for the CPU and GPU
● GTX 770 : 3.2 Tera FLOPs
● i7 : 141 Giga FLOPs
22.6배
12.
2014-04-23 12 윤석준(icysword@nate.com)
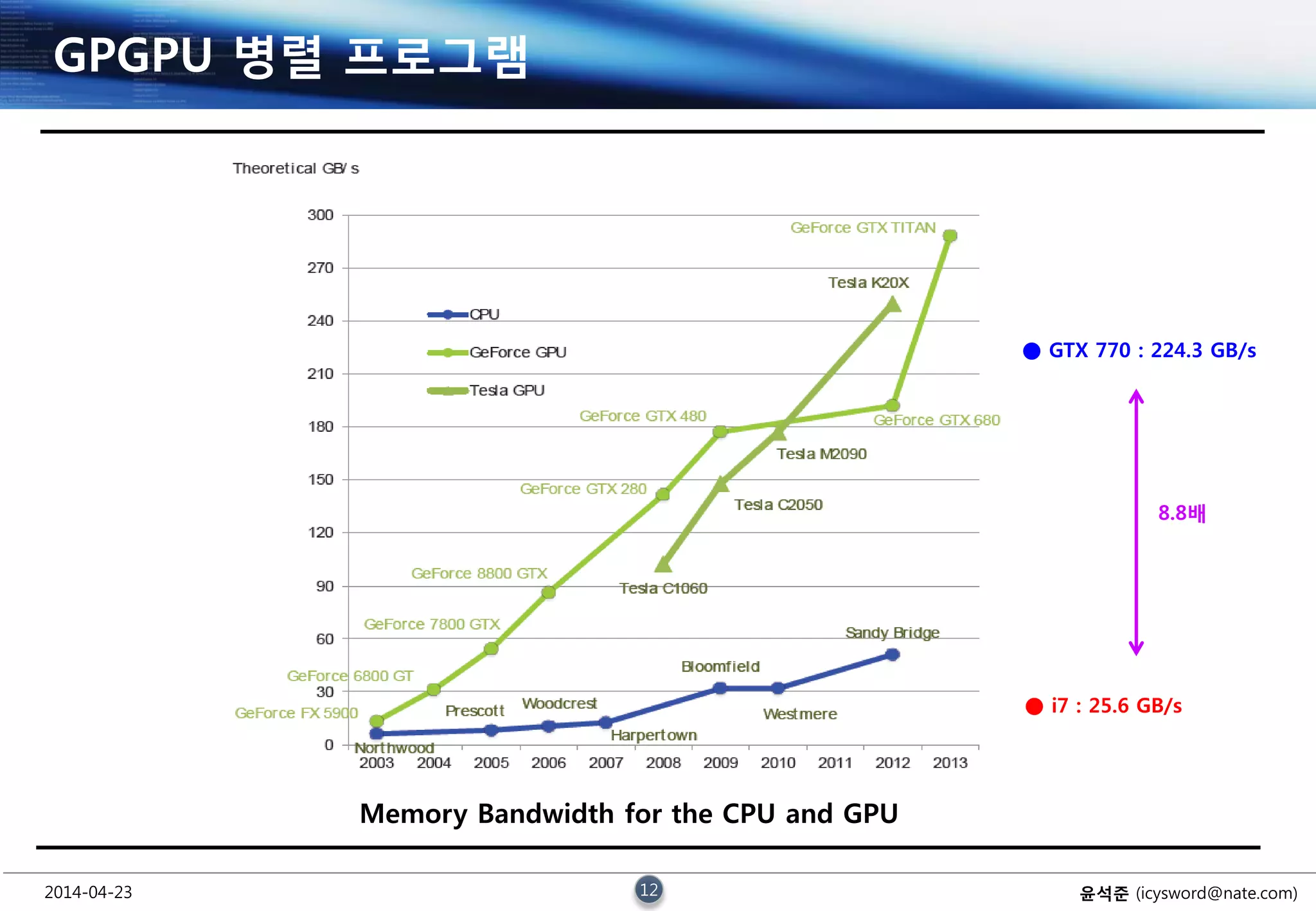
GPGPU 병렬 프로그램
Memory Bandwidth for the CPU and GPU
● GTX 770 : 224.3 GB/s
● i7 : 25.6 GB/s
8.8배
13.
2014-04-23 13 윤석준(icysword@nate.com)
CUDA란 ? (Compute Unified Device Architecture)
• 2006년 11월 GeForce 8800 GTX 이후 생산되는 GPU
• Geforce : 일반적인 Graphic Card
• Quadro : 고성능의 Graphic 작업 전용
• Tesla : Graphic 기능 없이 고성능 연산 전용
14.
2014-04-23 14 윤석준(icysword@nate.com)
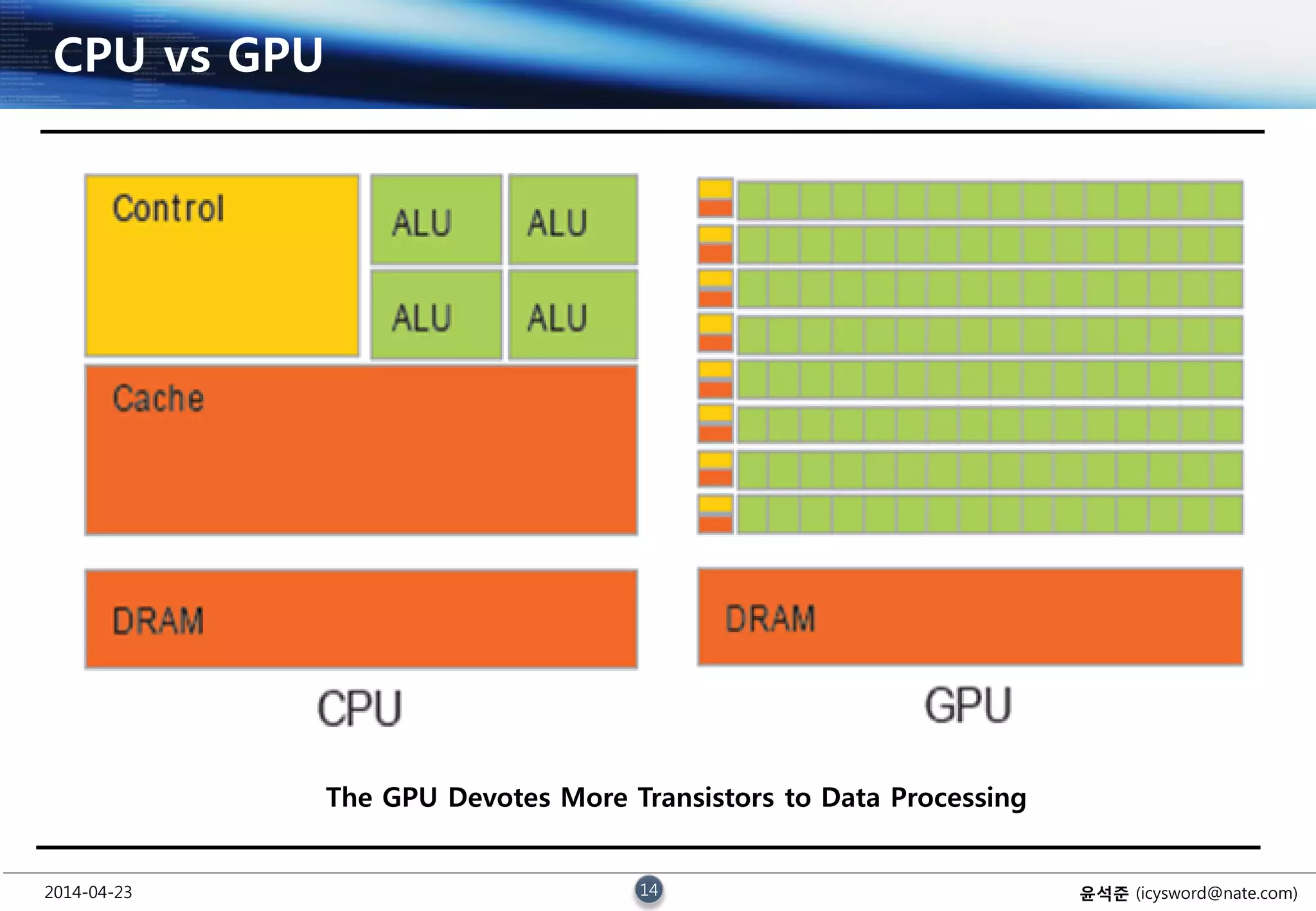
CPU vs GPU
The GPU Devotes More Transistors to Data Processing
15.
2014-04-23 15 윤석준(icysword@nate.com)
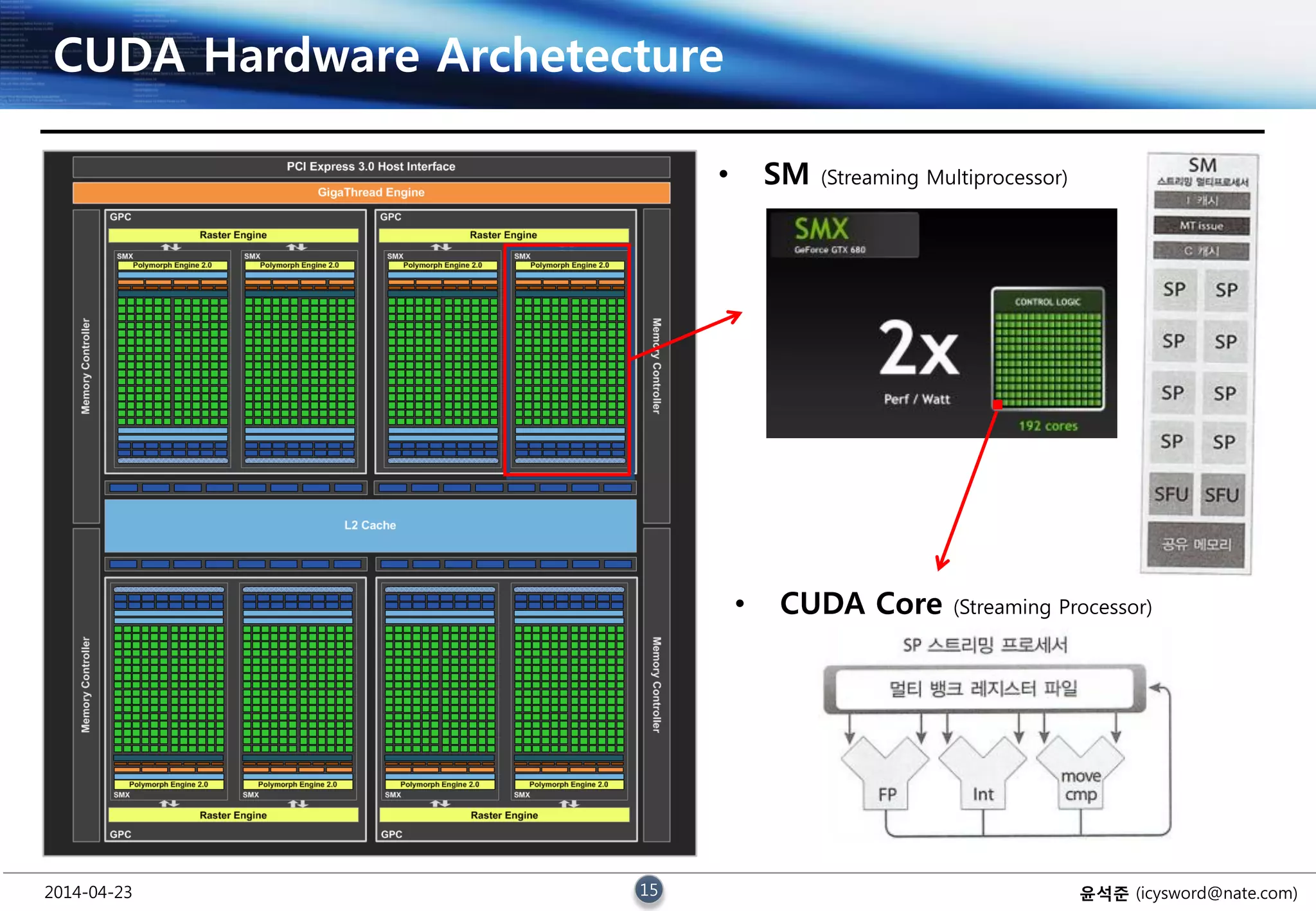
CUDA Hardware Archetecture
• SM (Streaming Multiprocessor)
• CUDA Core (Streaming Processor)
16.
2014-04-23 16 윤석준(icysword@nate.com)
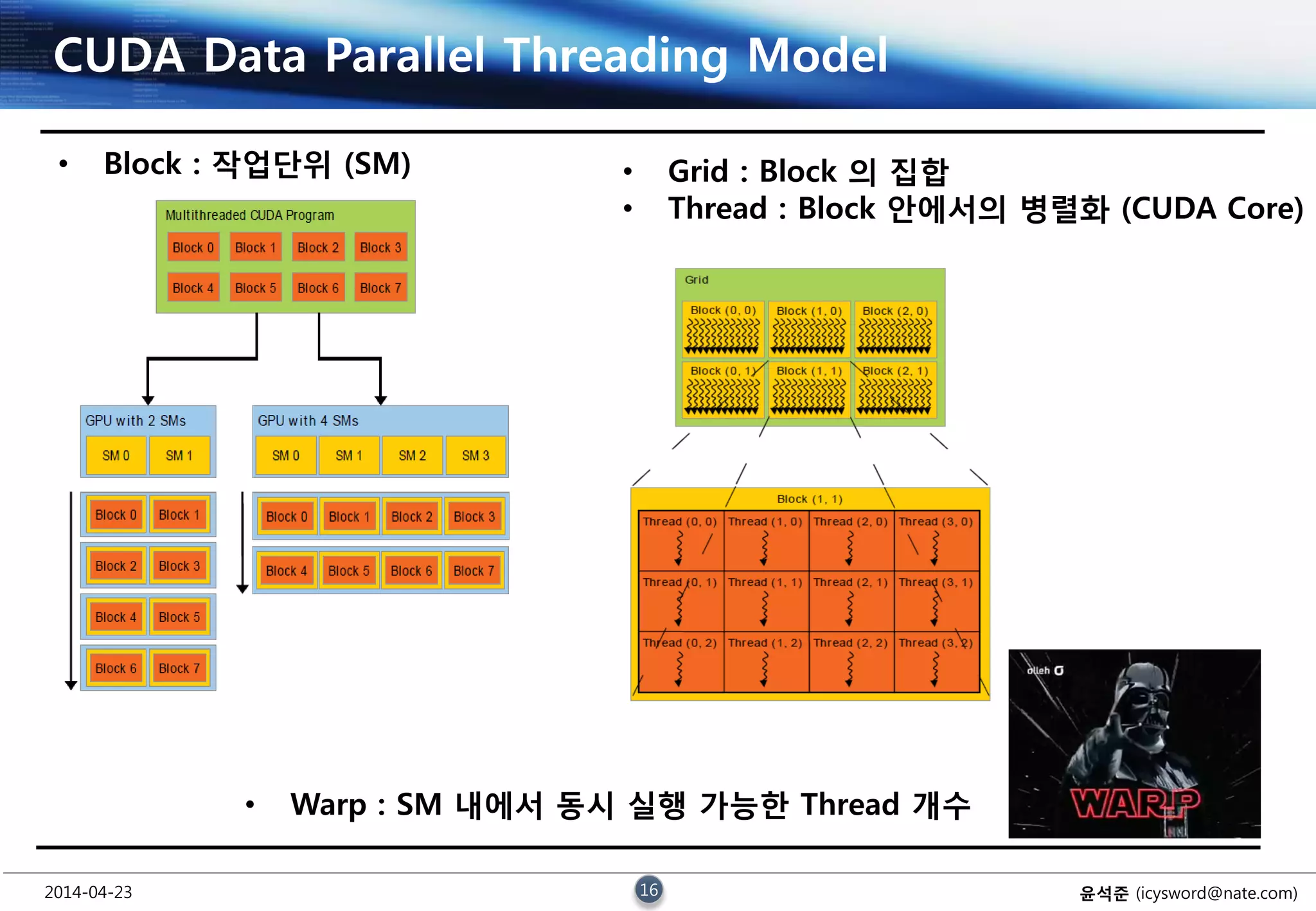
CUDA Data Parallel Threading Model
• Block : 작업단위 (SM)
• Warp : SM 내에서 동시 실행 가능한 Thread 개수
• Grid : Block 의 집합
• Thread : Block 안에서의 병렬화 (CUDA Core)
17.
2014-04-23 17 윤석준(icysword@nate.com)
Structure of CUDA Memory
• Registor
- On Chip Processor 에 있는 Memory
- 함수내의 Local 변수 (배열은 Global)
- 가장 빠른 메모리
• Shared Memory
- On Chip Processor 에 있는 Memory
- SM 내의 Thread 들이 공유
- L1 캐시급 속도
• Constant Memory
- 읽기전용 캐시
- Write (from DRAM) : 400 ~ 600 Cycles
- Read : Registor와 동급
• Global Memory
- Video Card에 장착된 DRAM
- Read/Write : 400 ~ 600 Cycles
• Texture Memory
- 캐시 읽기를 지원하는 Global Memory
- 설정 후 읽기전용
Register
Shared Memory
Constant Memory
Global Memory Texture Memory
18.
2014-04-23 18 윤석준(icysword@nate.com)
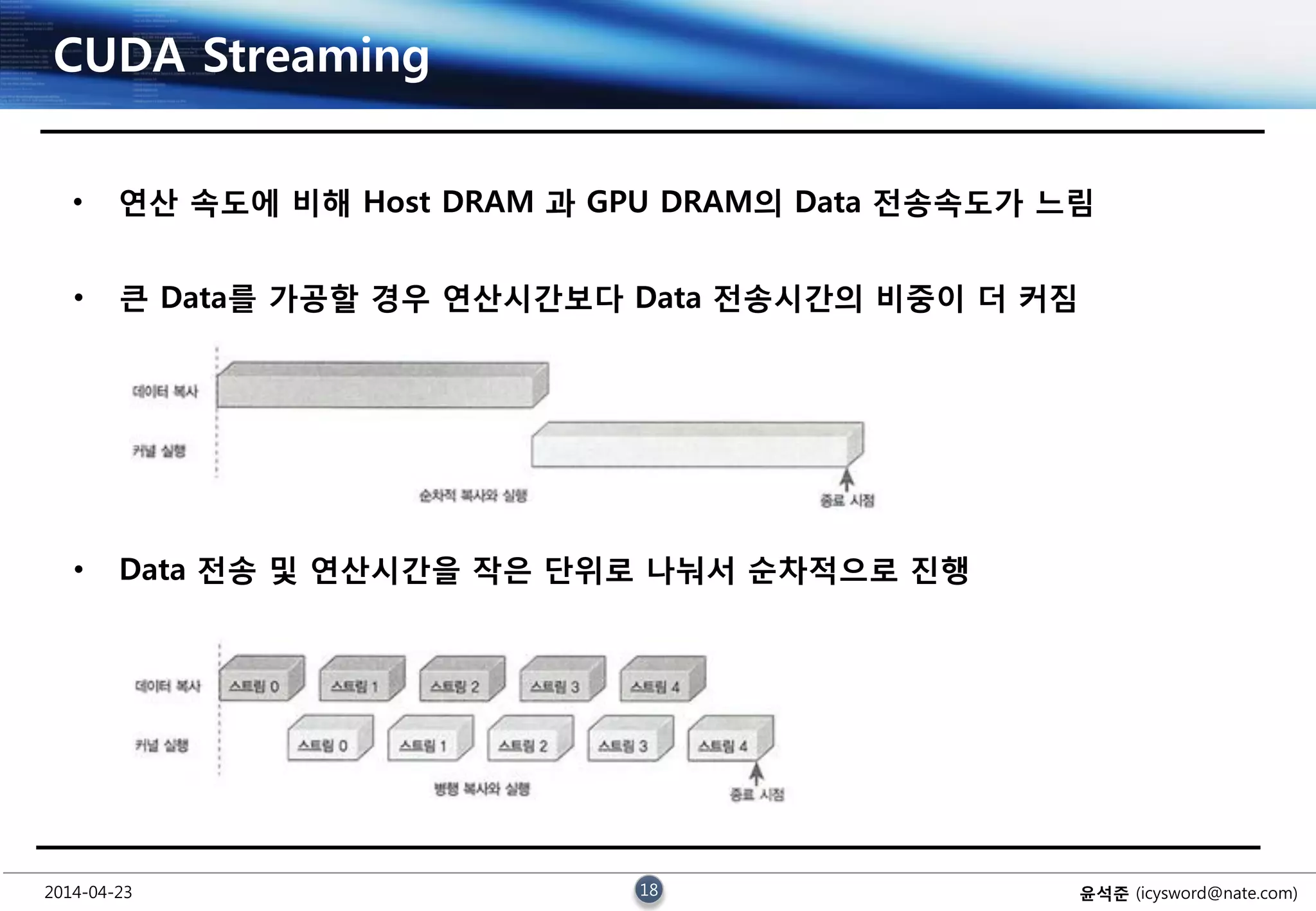
CUDA Streaming
• 연산 속도에 비해 Host DRAM 과 GPU DRAM의 Data 전송속도가 느림
• 큰 Data를 가공할 경우 연산시간보다 Data 전송시간의 비중이 더 커짐
• Data 전송 및 연산시간을 작은 단위로 나눠서 순차적으로 진행
19.
2014-04-23 19 윤석준(icysword@nate.com)
CUDA Library
• cuRAND : 랜덤수 생성기
(CUDA Random Number Generation library)
• CUFFT : FFT 연산 Library
(CUDA Fast Fourier Transform library)
• CUBLAS : 선형대수학 연산 Library
(CUDA Basic Linear Algebra Subroutines library)
20.
2014-04-23 20 윤석준(icysword@nate.com)
CUDA Programming 예제
float fResult[1024][1000];
float fData[1024][1000];
for (int i = 0; i < 1024; i++)
{
for (int j = 0; j < 1000; j++)
{
for (int k = 0; k < 33; k++)
{
fResult[i][j] += Calc(fData[i][j], k);
}
}
}
int main()
{
…
float *dev_fResult, *dev_fData;
int iSizeData = 1024 * 1000 * sizeof(float);
cudaMalloc((void**)&dev_fResult, iSizeData);
cudaMemset(dev_fResult, 0, iSizeData);
cudaMalloc((void**)&dev_fData, iSizeData);
cudaMemcpy(dev_fData, fData, iSizeData, cudaMemcpyHostToDevice);
KernelFunc<<<1024, 1000>>>(dev_fResult, dev_fData);
float* fResult = new float[1024 * 1000];
cudaMemcpy(fResult, dev_fResult, iSizeData, cudaMemcpyDeviceToHost);
cudaFree(dev_fResult);
cudaFree(dev_fData);
…
}
// 커널함수 : CPU에 의해 호출되어
// GPU에서 실행
// Device 함수 : GPU에서 실행
// Host 함수 : CPU에서 실행
// Atomic 연산 : Mutal Exclusion
// Device 메모리 할당
// Kernel 함수 호출
// Host 메모리 할당
__global__ void KernelFunc(float* i_fResult, float* i_fData)
{
float fResult = 0.0f;
int index = blockIdx.x * gridDim + threadIdx.x;
float fData = i_fData[index];
for (int k = 0; k < 33; k++)
{
fResult += Calc(fData, k);
}
i_fResult[index] = fResult;
}
21.
2014-04-23 21 윤석준(icysword@nate.com)
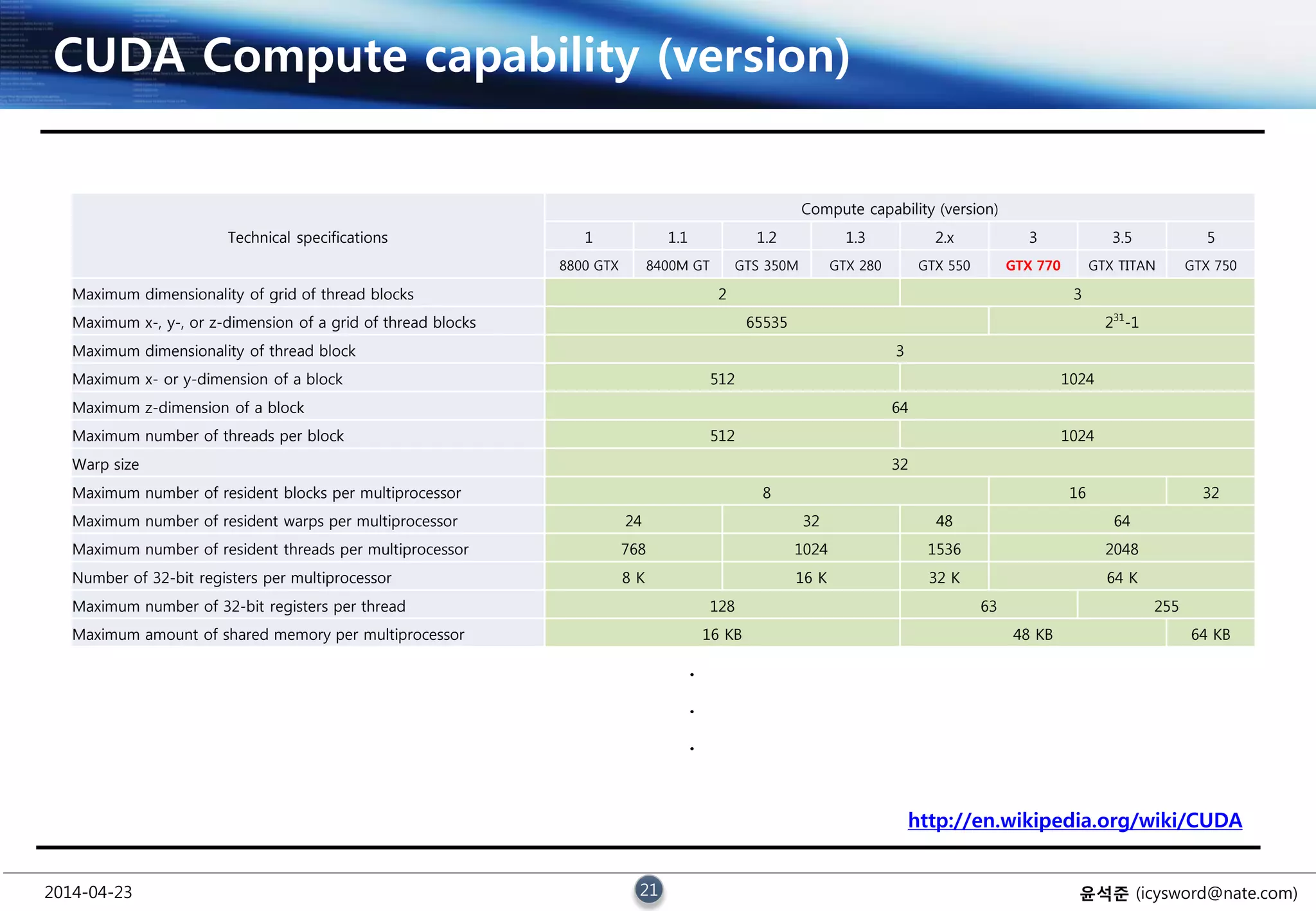
CUDA Compute capability (version)
http://en.wikipedia.org/wiki/CUDA
.
.
.
Technical specifications
Compute capability (version)
1 1.1 1.2 1.3 2.x 3 3.5 5
8800 GTX 8400M GT GTS 350M GTX 280 GTX 550 GTX 770 GTX TITAN GTX 750
Maximum dimensionality of grid of thread blocks 2 3
Maximum x-, y-, or z-dimension of a grid of thread blocks 65535 231
-1
Maximum dimensionality of thread block 3
Maximum x- or y-dimension of a block 512 1024
Maximum z-dimension of a block 64
Maximum number of threads per block 512 1024
Warp size 32
Maximum number of resident blocks per multiprocessor 8 16 32
Maximum number of resident warps per multiprocessor 24 32 48 64
Maximum number of resident threads per multiprocessor 768 1024 1536 2048
Number of 32-bit registers per multiprocessor 8 K 16 K 32 K 64 K
Maximum number of 32-bit registers per thread 128 63 255
Maximum amount of shared memory per multiprocessor 16 KB 48 KB 64 KB
22.
2014-04-23 22 윤석준(icysword@nate.com)
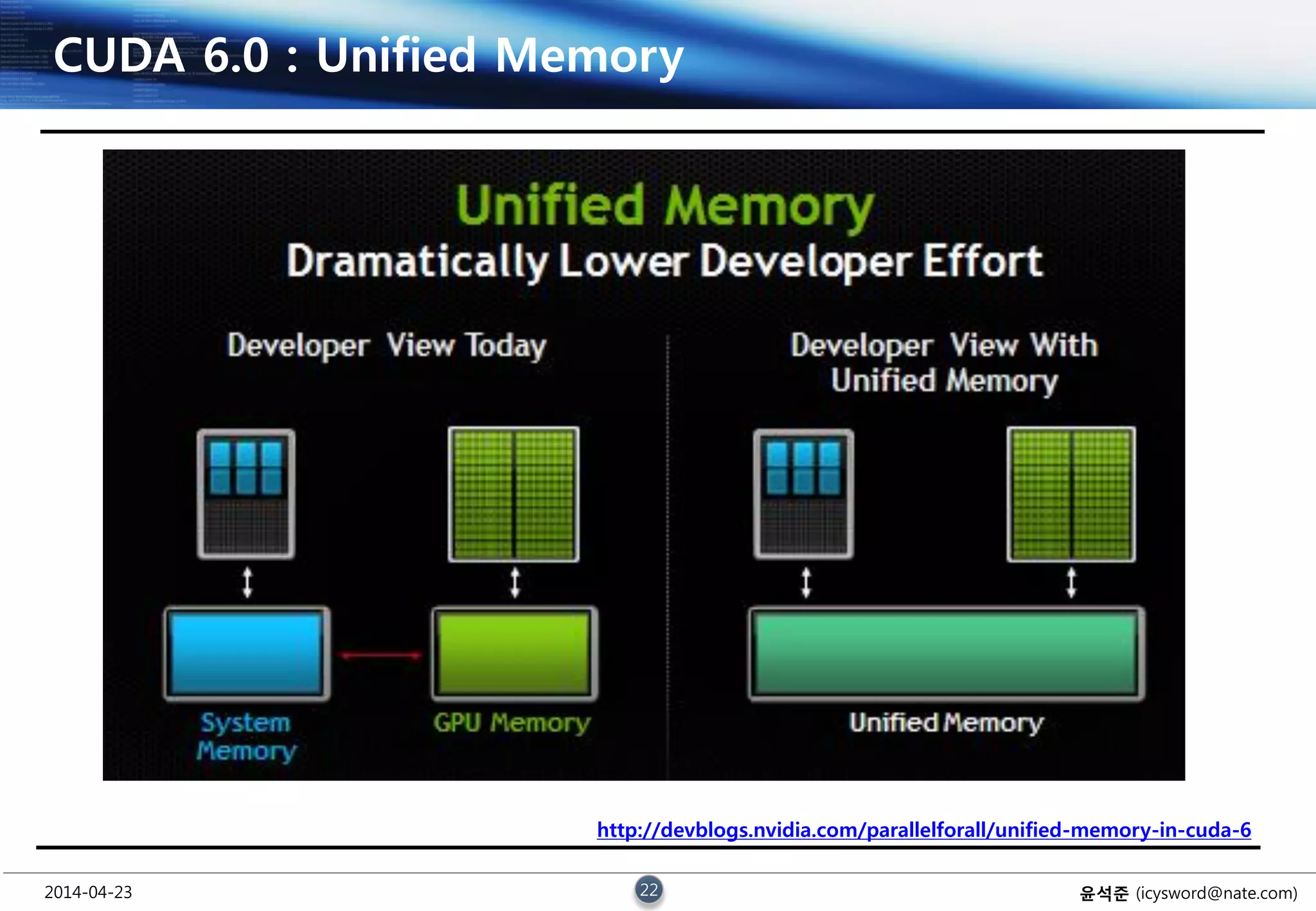
CUDA 6.0 : Unified Memory
http://devblogs.nvidia.com/parallelforall/unified-memory-in-cuda-6
23.
2014-04-23 23 윤석준(icysword@nate.com)
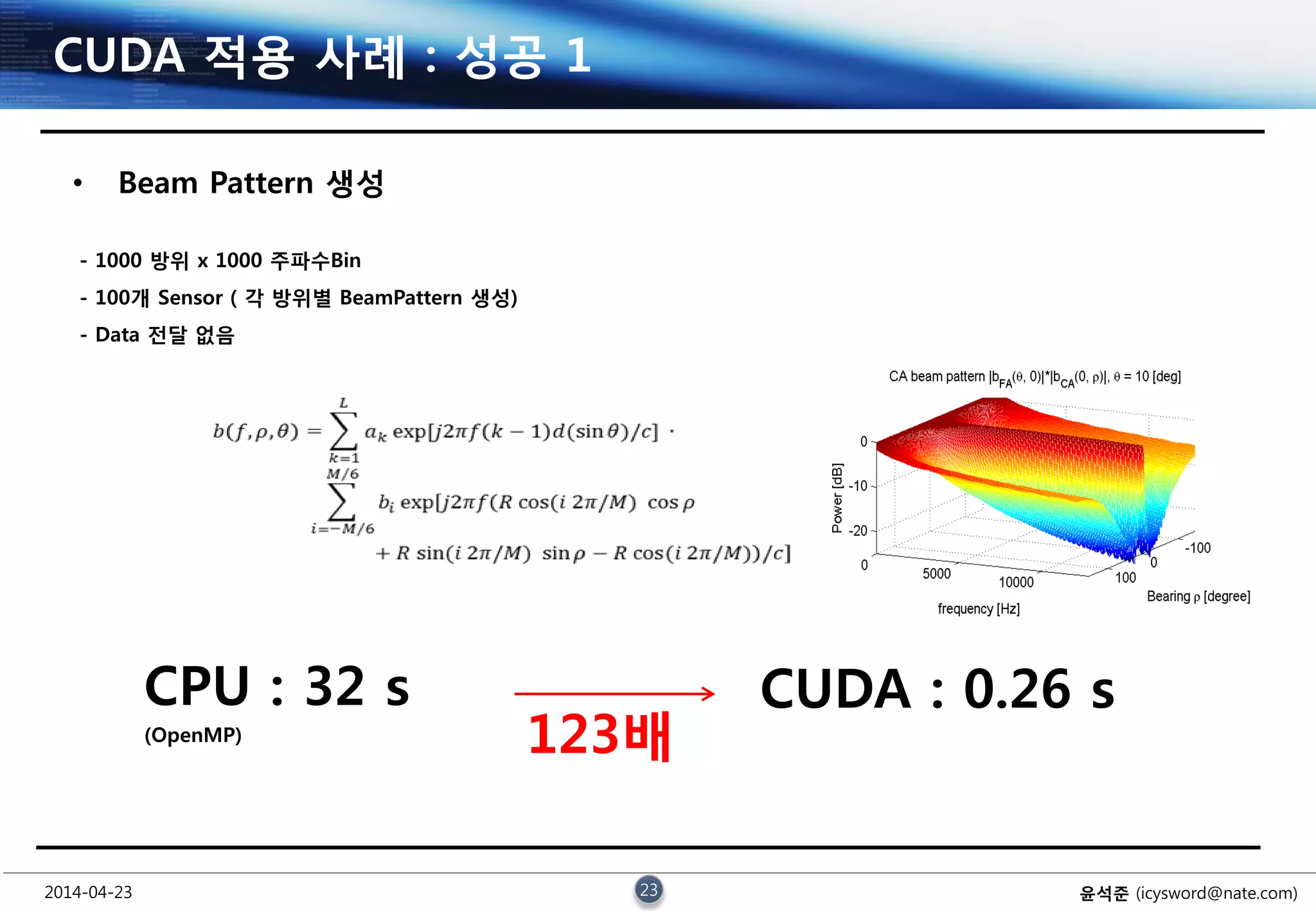
CUDA 적용 사례 : 성공 1
• Beam Pattern 생성
- 1000 방위 x 1000 주파수Bin
- 100개 Sensor ( 각 방위별 BeamPattern 생성)
- Data 전달 없음
CPU : 32 s
(OpenMP)
CUDA : 0.26 s
123배
24.
2014-04-23 24 윤석준(icysword@nate.com)
CUDA 적용 사례 : 성공 2
• 타겟 신호 에 Beam Pattern 적용
- 192 방위 x 1000 주파수Bin
- 16타겟
- Data Read/Write : 192 x 1000 x floatComplex x 2 (LOFAR/DEMON)
CPU : 900 ms
(OpenMP)
CUDA : 14 ms
64배
25.
2014-04-23 25 윤석준(icysword@nate.com)
CUDA 적용 사례 : 실패
• Cubic Spline Interoplation
CPU 연산에 비하여 성능 향상이 없음
… Xi(14) Xi(15) Xi(16) …
Xo(n) Xo(n+1)
- 입력 된 각각의 점들에 대하여 사용될 각종 변수들 계산 : Sequential Operation
- 출력값 연산 : 병렬화 가능은 하나 해당 위치를 찾을 시 Sequential에 비해 검색 시간이 느림









![2014-04-23 20 윤석준 (icysword@nate.com)
CUDA Programming 예제
float fResult[1024][1000];
float fData[1024][1000];
for (int i = 0; i < 1024; i++)
{
for (int j = 0; j < 1000; j++)
{
for (int k = 0; k < 33; k++)
{
fResult[i][j] += Calc(fData[i][j], k);
}
}
}
int main()
{
…
float *dev_fResult, *dev_fData;
int iSizeData = 1024 * 1000 * sizeof(float);
cudaMalloc((void**)&dev_fResult, iSizeData);
cudaMemset(dev_fResult, 0, iSizeData);
cudaMalloc((void**)&dev_fData, iSizeData);
cudaMemcpy(dev_fData, fData, iSizeData, cudaMemcpyHostToDevice);
KernelFunc<<<1024, 1000>>>(dev_fResult, dev_fData);
float* fResult = new float[1024 * 1000];
cudaMemcpy(fResult, dev_fResult, iSizeData, cudaMemcpyDeviceToHost);
cudaFree(dev_fResult);
cudaFree(dev_fData);
…
}
// 커널함수 : CPU에 의해 호출되어
// GPU에서 실행
// Device 함수 : GPU에서 실행
// Host 함수 : CPU에서 실행
// Atomic 연산 : Mutal Exclusion
// Device 메모리 할당
// Kernel 함수 호출
// Host 메모리 할당
__global__ void KernelFunc(float* i_fResult, float* i_fData)
{
float fResult = 0.0f;
int index = blockIdx.x * gridDim + threadIdx.x;
float fData = i_fData[index];
for (int k = 0; k < 33; k++)
{
fResult += Calc(fData, k);
}
i_fResult[index] = fResult;
}](https://image.slidesharecdn.com/cuda-140423010541-phpapp01/75/Cuda-20-2048.jpg)

























![[2019] 게임 서버 대규모 부하 테스트와 모니터링 이렇게 해보자](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201924-200122092752-thumbnail.jpg?width=640&height=640&fit=bounds)






![[부스트캠프 Tech Talk] 신원지_Wandb Visualization](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkshinwonji-211210113635-thumbnail.jpg?width=640&height=640&fit=bounds)









![[2B2]기계 친화성을 중심으로 접근한 최적화 기법](https://cdn.slidesharecdn.com/ss_thumbnails/2b2-140929202533-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









![[조진현]Kgc2012 c++amp](https://cdn.slidesharecdn.com/ss_thumbnails/kgc2012camp-121019195944-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015-07-10-윤석준] Oracle 성능 관리 & v$sysstat](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-10-oraclevsysstat-150709064246-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




![[2015-07-20-윤석준] Oracle 성능 관리 2](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-20-oracle2-150727235547-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)











