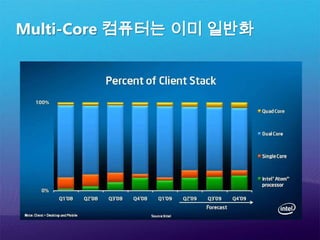
Visual Studio –2002년과 2010년Visual Studio.NET( 2002)Visual Studio 2010
33.
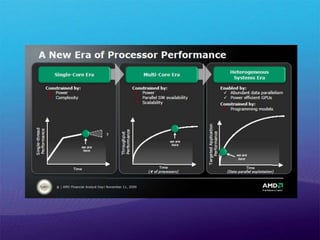
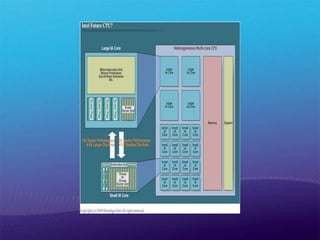
2008년 10월 Microsoft의최고 연구 전략 책임자를 맡은 Craig Mundie씨 Win32는 비동기 병렬 컴퓨팅에는 적합하지 않는 것을 인정. - Windows 7 및 Windows Server 2008 R2에서 문제 해결을 위해 첫발을 내딪음.- Windows는 지금이라도 2,3의 코어 머신을 처리할 수 있지만 8, 16 또는 32 이상의 코어 머신을 사용하도록 설계되어 있지 않다.
34.
Windows를 보다뛰어난 병렬/비동기프로세싱 플랫폼화 하기 위한 최초의 씨앗은 2009년부터 뿌려지기 시작.UMS - Cooperative SchedulingUserThread4UserThread3UserThread5UserThread6Core 2Core 2Core 1Core 1Thread4Thread5UserThread1Thread3Thread1Thread2Thread6UserThread2KernelThread1KernelThread2KernelThread4KernelThread3KernelThread5KernelThread6Non-running threadsThread Scheduling그림 출처 : PDC 09
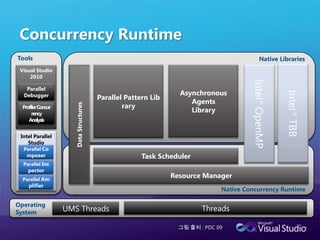
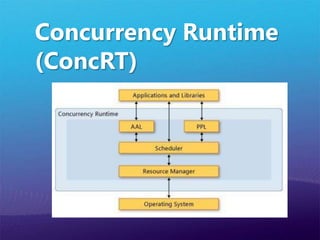
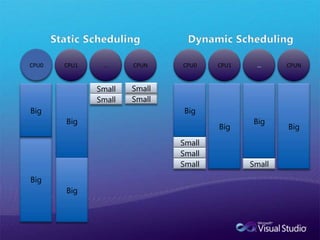
다른 병렬라이브러리의 병행 런타임과 컴퓨팅 리소스 관리를 통합 할 수 있다.DynamicSchedulingStatic SchedulingCPU0CPU1…CPUNCPU0CPU1…CPUNSmallSmallBigBigBigBigBigBigSmallSmallBigSmallSmallBigSmallSmall
Parallel containersand objects 3D 게임을 실행하면…Font 리소스 로딩Texture 리소스 로딩3D 모델링 리소스 로딩 등등…
64.
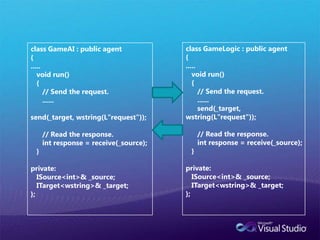
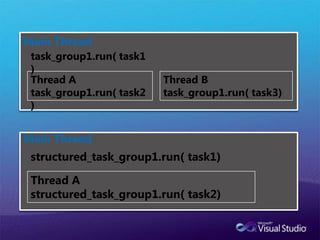
Task Parallelism실제적인 task의실행은 task_group에서 한다.unstructured_task_group(task_group) 와 structured_task_group로나누어진다.task_group : 스레드 세이프structured_task_group : 스레드 세이프 하지 않음.
65.
Main ThreadMain Threadtask_group1.run(task1)structured_task_group1.run( task1)Thread Atask_group1.run( task2)Thread Btask_group1.run( task3)Thread Astructured_task_group1.run( task2)
66.
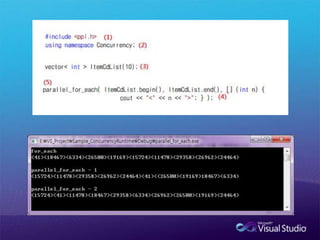
초 간단!!! task 사용 방법ppl.h파일을 포함합니다.#include <ppl.h>Concurrency Runtime의 네임 스페이를 선언합니다.using namespace Concurrency;태스크 그룹을 정의합니다.structured_task_groupstructured_tasks;태스크를 정의합니다.auto structured_task1 = make_task([&] { Plus(arraynum1, true); } );태스크를 태스크 그룹에 추가한 후 실행합니다. structured_tasks.run( structured_task1 );태스크 그룹에 있는 태스크가 완료될 때까지 기다립니다.structured_tasks.wait();
Parallel Algorithms데이터컬렉션을 대상으로쉽게 병렬 작업을 할 수 있게 해주는 알고리즘들.STL에서 제공하는 알고리즘과 비슷한 모양과 사용법.paeallel_for, parallel_for_each, parallel_invoke가 구현되어 있음.parallel_accumulate, parallel_partial_sum는 다음 버전?
71.
parallel_forfor 문을 병렬화.for문과 사용 방법이 흡사하여 쉽게 변환.step 값을 지정하는 버전과 지정하지 않는 버전 두 개가 있음(지정하지 않으면 1).index 조사는 ‘<‘만 지원.
72.
초 간단!!! parallel_for사용법ppl.h파일을 포함합니다.#include <ppl.h>Concurrency Runtime의 네임 스페이를 선언합니다.using namespace Concurrency;parallel_for에서 호출할 함수 정의parallel_for에서 사용할 data set 정의.parallel_for사용.
초 간단!!! parallel_for_each사용법ppl.h파일을 포함합니다.#include <ppl.h>Concurrency Runtime의 네임 스페이를 선언합니다.using namespace Concurrency;parallel_for_each에서 호출할 함수 정의parallel_for_each에서 사용할 data set 정의.parallel_for_each사용.















































![코어 증가와 Resource Management 4개의 Core를 가진 ConcRT를 사용한 프로세스가 두개 실행 중이라면, 하나의 ConcRT는 Core 0, Core 1에서, 두 번째 ConcRT는 Core 2, Core 3에서 실행ConRT Memory leak?#include "stdafx.h"#include <ppl.h>using namespace Concurrency;int main(){ _CrtSetDbgFlag( _CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF );parallel_invoke( [] { }, [] { } ); return 0;}위 코드는 디버그 모드에서 메모리 릭을 경고.](https://image.slidesharecdn.com/vs2010cpp-100822012201-phpapp01/85/Visual-C-10-58-320.jpg)
![이유는 Task Scheduler와 Resource Manage가 파괴되기 전에 프로그램이 종료 되기 때문.int main(){HANDLE hEvent = CreateEvent( NULL, TRUE, FALSE, NULL );CurrentScheduler::Create( SchedulerPolicy() );CurrentScheduler::RegisterShutdownEvent( hEvent ); _CrtSetDbgFlag( _CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF );parallel_invoke( [] {}, [] {} );CurrentScheduler::Detach();WaitForSingleObject( hEvent, INFINITE );CloseHandle( hEvent ); Sleep(500); return 0;}](https://image.slidesharecdn.com/vs2010cpp-100822012201-phpapp01/85/Visual-C-10-59-320.jpg)
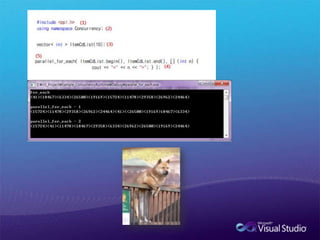





![초 간단!!! task 사용 방법ppl.h파일을 포함합니다.#include <ppl.h>Concurrency Runtime의 네임 스페이를 선언합니다.using namespace Concurrency;태스크 그룹을 정의합니다.structured_task_groupstructured_tasks;태스크를 정의합니다.auto structured_task1 = make_task([&] { Plus(arraynum1, true); } );태스크를 태스크 그룹에 추가한 후 실행합니다. structured_tasks.run( structured_task1 );태스크 그룹에 있는 태스크가 완료될 때까지 기다립니다.structured_tasks.wait();](https://image.slidesharecdn.com/vs2010cpp-100822012201-phpapp01/85/Visual-C-10-66-320.jpg)








![[2B7]시즌2 멀티쓰레드프로그래밍이 왜 이리 힘드나요](https://cdn.slidesharecdn.com/ss_thumbnails/2b72-140930004949-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2D7]레기온즈로 살펴보는 확장 가능한 게임서버의 구현](https://cdn.slidesharecdn.com/ss_thumbnails/2d7-140930023650-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[2D4]Python에서의 동시성_병렬성](https://cdn.slidesharecdn.com/ss_thumbnails/2d4pythondeview2014-140929211011-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[162] jpa와 모던 자바 데이터 저장 기술](https://cdn.slidesharecdn.com/ss_thumbnails/162jpa-150914054532-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)









![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)




![[ 하코사세미나] 의외로 쉬운 D3 그래프 퍼블리싱](https://cdn.slidesharecdn.com/ss_thumbnails/2015-12-05-d3-151208015226-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















![Go web framework 비교[번역 정리]](https://cdn.slidesharecdn.com/ss_thumbnails/gowebframework-170822135854-thumbnail.jpg?width=640&height=640&fit=bounds)

















