서버에서 충돌처리를 하면좋은 점
• 위치,속도 Hack의 원천 봉쇄
• 서버측에서 능동적으로 이것저것 하기 좋음
• 정밀한 위치 추척 가능(30,60프레임 단위로 처리
가능)
• 클라이언트에서 플레이어 제어하듯 서버에서도
플레이어,NPC,몬스터의 이동을 프로그래밍 가능.
그래도 감당이 안되면(1)?
•CPU를 더 꽂는다.
• 일반 데스크탑 CPU는 멀티 CPU구성 불가
• 2개 이상 꽂을 수 있는 Xeon CPU를 사용한다.
참고)
프로젝트 엡실론에선 플레이어 4000명을 커버하기
위해 6core Xeon 2개를 사용했음.
9.
그래도 감당이 안되면(2)?
•4개 이상 꽂을 수 있는 Xeon CPU를 사용한다
• 여기서부턴 조립불가. 가격이 미친듯이 뛰기 시작함
• 10 Core Xeon을 8개 꽂으면 확실!
Intel® Xeon® Processor E7-8870
4616$ x 8 = 36928$(CPU만)
서버머신 가격은 더 비쌈.
GPGPU(General-Purpose computing onGPU
• GPU를 사용하여 CPU가 전통적으로 취급했던 응용
프로그램들의 계산을 수행하는 기술
• GPU 코어 1개의 효율은 CPU 코어 1개에 비해 많이
떨어지지만 코어의 개수가 엄청나게 많다.
• 많은 수의 코어를 사용하면 병렬 산술 연산의 성능은
CPU의 성능을 압도한다.
GPGPU의 특징
강점 약점
• 엄청난 수의 스레드를 사용할 • 흐름제어 기능 자체가
수 있다. 빈약하다.
• 부동소수점 연산이 엄청 • 프로그래밍 기법의
빠르다. 제약(재귀호출불가)
• 컨텍스트 스위칭이 엄청 • Core당 클럭이 CPU에 비해
빠르다. 많이 느리다(1/3 – 1/2수준)
• 그래서 충분히 병렬화된
산술처리에는 짱.
17.
CUDA (Compute UnifiedDevice
Architecture)
• C언어 등 산업 표준 언어를 사용하여 GPU에서
작동하는 병렬처리 코드를 작성할 수 있도록 하는
GPGPU기술
• nVidia가 개발,배포.그래서 nVidia GPU만 가능.
• 비슷한 기술로 OpenCL, Direct Compute Shader가
있음.
CUDA메모리
• Global Memory– 보통 말하는 Video Memory. 크다. 느리다.
• Register – CPU의 레지스터와 같다. 로컬변수, 인덱싱하지 않고
크기가 작은 로컬배열은 레지스터에 맵핑된다. 작다. 빠르다.
• Shared Memory – Block의 스레드들이 공유하는 메모리. 블럭당
48KB. 작다. 빠르다.
참고)
SM에 하나씩 존재하는 64KB의 캐쉬를 16KB L1캐쉬와 48KB
Shared Memory로 사용
27.
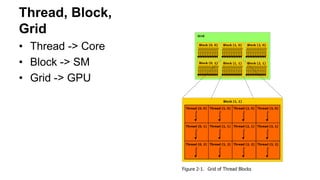
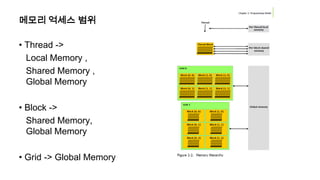
메모리 억세스 범위
•Thread ->
Local Memory ,
Shared Memory ,
Global Memory
• Block ->
Shared Memory,
Global Memory
• Grid -> Global Memory
성능 비교
2885x4102크기의 이미지에5x5 Gaussian
Blur를 3회 적용
1Threads - Intel i7 2600K @3.8GHz
-> 10054.3ms
8Threads - Intel Intel i7 2600K @3.7GHz
-> 2247.8ms
CUDA - GTX480 (15 SM x 32 Core = 480
Core)
->203.7ms
참고)
이미지 필터링 코드는 CUDA, CPU 완전
동일.
알고리즘상의 최적화는 없음.
병렬처리 효율의 비교를 위한 테스트임.
구현전략
• 싱글스레드 C코드로 작성한다
• 자료구조상으로 최적화한다.
• 멀티스레드로 바꾼다.
• CUDA로 (단순) 포팅한다.
• 퍼포먼스를 측정한다.
• 절망한다.
• CUDA에 적합하도록 일부의 설계를 변경 한다.
• 최적화한다.
33.
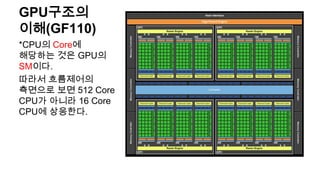
충돌처리코드개요
• 움직이는 타원체의궤적에 걸칠만한 삼각형과 다른
타원체를 수집
• 루프를 돌며 각각의 삼각형과 타원체에 충돌체크
• 가장 가까운 충돌점을 찾는다
• 반사, 또는 미끄러짐 벡터를 구한다.
• 충돌 후 벡터의 스칼라량이 0에 근접하면 탈출
• 그렇지 않으면 다시 1부터 반복
34.
CPU코드로 작성
• CUDA로포팅할 것을 염두해 두고
작성한다(재귀호출 사용불가)
• 주변 삼각형과 타원체를 골라내기 위해 공간분할이
중요하다. (BSP Tree, KD Tree, Grid등) BSPTree나
KDTree는 CUDA로 포팅하기도 어렵고 CUDA로
돌리려면 성능이 많이 떨어진다. GRID와 같이
단순한 자료구조를 권장.
35.
CPU코드로 작성
• 일단CPU상에서 멀쩡히 돌아가는게 가장 중요하다.
• SSE,AVX등 SIMD최적화는 나중에
생각하자.CUDA포팅에 걸림돌이 된다.
Multi-Thread코드 작성(Tip)
• 4000obj/ 8 thread = 500, 1 thread당 500개처리 ->
OK? ->NO!!!!
오브젝트마다 처리시간이 다르기 때문에 탱자탱자
노는 thread가 생긴다.
• Thread들이 경쟁적으로 큐에서 충돌처리할
오브젝트를 가져간다. -> OK!!!
거의 노는 thread 없이 CPU자원을 꽉 채워서 사용할
수 있다.
38.
CUDA코드로 포팅
• 표준적인문법만 사용했다면 별로 수정할게 없다.
• Multi-Thread코드와 유사하다. CPU Thread ->
CUDA Thread로 바로 맵핑하면 된다.
39.
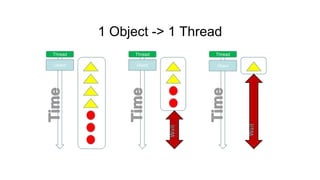
단순포팅
• 처리하고 하는 [원소 1개 > thread 1개] 직접 맵핑
• 1 pixel -> 1 thread, 1 오브젝트-> 1스레드
• C로 짠 코드는 거의 100% 그대로 돌릴 수 있다.
• 이미지 프로세싱 매트릭스 연산 등에선 충분히
효과가 있다.
40.
단순포팅의 결과
• 충돌처리에선CPU코드(멀티스레드)보다 느리게
작동한다!
• HW스펙만으로 동시 처리 가능한 오브젝트 수를
짐작해보면…
CPU(i7 2600) : 4Core x 2(HT) = 8 Thread,
CUDA(GF110) : 32Core x 16SM = 512 Thread
단순하게 생각하면 동시에 처리하는 오브젝트 수가 훨씬
많은데 왜 느릴까.
41.
SIMT(Single Instruction MultipleThreads)
• 동일 명령어를 여러개의 Thread가 동시 실행
• GPU는 기본적으로 SIMT로 작동
• N차원 벡터를 다루는 산술처리에선 적합
• Thread중 일부가 분기를 하거나 루프를 하면 나머지
Thread들은 대기 -> 병렬처리의 의미가 없어짐.
42.
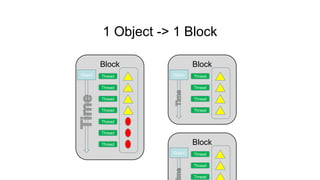
WARP의 이해
• Thread들을묶어서 스케쥴링하는 단위
• 현재까지는 모든 nVidia GPU의 1 Warp는 32
Thread. 즉 32 Thread는 늘 같은 같은 코드
어드레스를 지나감.
• 동시 수행 가능한 Warp 수는 SM의 Warp 스케쥴러
개수에 의존. SM당 2개의 Warp를 동시에
실행가능(GF100)
43.
WARP의 이해
• 32Thread중 1개의 Thread만이 분기해서 Loop를
돌고 있으면 31개의 Thread는 1개의 Thread가
Loop를 마치고 같은 코드 어드레스를 수행할 수 있을
때가지 대기.
• 각 Thread가 다른 루프, 다른 흐름을 타는 것은
엄청난 성능 저하를 부른다.
44.
Worst Case
DWORD ThreadIndexInBlock= threadIdx.y * blockDim.x + threadIdx.x;
DWORD UniqueThreadIndex = UniqueBlockIndex * ThreadNumPerBlock + ThreadIndexInBlock;
int CountList[32] = {0,1,2,3,...,31};
// 32개의 스레드가 동시에 루프를 돈다.
for (int i=0; i<CountList[UniqueThreadIndex]; i++)
{
...
}
// CountList[UniqueThreadIndex] == 0 인 스레드도 CountList[UniqueThreadIndex] == 31인 스레드를
대기
// 모든 스레드가 가장 오래 걸리는 스레드에 맞춰서 움직인다.즉
// 모든 스레드가 31번 루프를 도는 것과 같다.
45.
SIMT를 고려한 설계
•가장 시간을 많이 잡아먹는 코드는 어디인가?
• 병렬화 하기 좋은 코드는 어디인가?
• 가장 시간을 많이 잡아먹고 병렬화 가능한 코드를
병렬화한다.
46.
충돌처리 코드에서 SIMT를고려한 설계
• 충돌처리의 경우 Loop를 돌며 인접한 삼각형과
오브젝트(타원체)를 찾는 코드에서 가장 많은 시간을
잡아먹는다.
• WARP단위로 명령어를 실행하기 때문에 삼각형과
타원체를 찾는 루프에서 대부분의 코어가 논다.
• [1개의 Thread가 N번 Loop -> M개의 Thread가
N/M번의 Loop] 로 수정
루프개선
(단순화된 모델에서의 루프 개선)
• 충돌처리 코드에서 가장 병목이 걸리는 루프를
단순화 시켜보자.
A. 오브젝트 한 개당 N개의 타원체와 삼각형에 대해
충돌체크를 하고 가장 가까운 충돌점을 찾는다.
B. 오브젝트 한개당 N개의 숫자를 들고 있고 그 중
가장 작은 수, 혹은 가장 큰 수를 찾는다.
49.
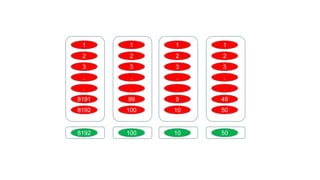
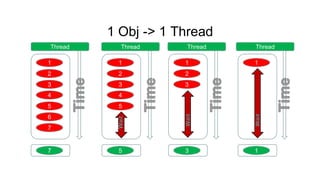
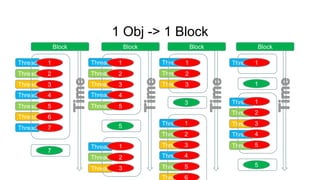
루프개선
(단순화된 모델에서의 루프 개선)
• 8192개의 CELL이 있다.
• 각 CELL은 랜덤하게 1 ~ 8192범위의 숫자를 1 ~
8192 개 가지고 있다.
• 각 CELL에 대해서 최대값을 구한다.
1) CPU Single Thread
2) CUDA , 1 Cell -> 1 Thread
3) CUDA , 1 Cell -> 1 Block
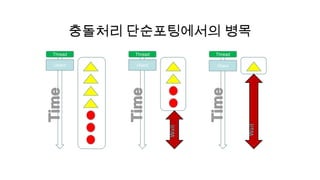
충돌처리 루프 수정후
• 빨라졌다!
• 그러나 생각보다는 많이 안빠르다.(CPU대비 2-3배
성능)
61.
Occupancy
• SM당 활성화Warp 수 / SM당 최대 Warp 수
• GPU의 처리능력을 얼마나 사용하는지 척도
• 대부분의 경우 Occupancy가 증가하면 효율(시간당
처리량)도 증가함
• Global Memory 억세스로 latency가 발생할때 유휴
Warp를 수행함.
• GPU 디바이스의 스펙에 상관없이 WARP를 많이
유지할 수 있으면 처리성능이 높아진다.
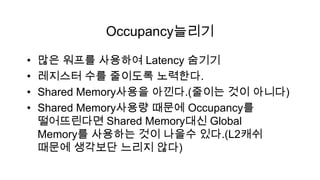
Occupancy늘리기
• 많은 워프를 사용하여 Latency 숨기기
• 레지스터 수를 줄이도록 노력한다.
• Shared Memory사용을 아낀다.(줄이는 것이 아니다)
• Shared Memory사용량 때문에 Occupancy를
떨어뜨린다면 Shared Memory대신 Global
Memory를 사용하는 것이 나을수 있다.(L2캐쉬
때문에 생각보단 느리지 않다)
64.
Shared Memory아껴쓰기
• 자주억세스할 경우 Shared Memory에 올려놓으면
빠르다.
• 무작정 마구 쓰면 SM에 맵핑할 수 있는 블럭 수가
크게 떨어진다.
• Shared Memory절약 ->Active Block수 증가 ->
성능향상
65.
Register 사용량 줄이기
•사실 뾰족한 방법이 있는건 아니다.
• 알고리즘 수준에서의 최적화 -> 결과적으로 작은
코드.
• 레지스터 개수를 컴파일 타임에 제한할 수는
있다(경험상 별로 안빨라짐).
Unrolling
• 루프를 풀면컨트롤 명령어 수를 줄일 수 있다. 산술
명령어를 더 실행할 수 있다.
• Occupancy증가만큼은 아니지만 꽤 효과가 있다.
• 아직까지는 nvcc가 능동적으로 Unrolling을 해주지는
못하는 것 같다. 수동으로 해주면 효과가 있다.
68.
PCI-E버스 병목 줄이기
•한번에 몰아서 전송한다.
• 퍼포먼스를 떨어뜨리지 않는 선에 압축할 수 있으면
압축한다. 이 경우 커널 호출을 여러번 해야한다.
• 처리량의 향상에는 큰 도움을 주지 않지만 응답성
면에선 차이가 크다(게임에선 처리량보다 응답성이
중요).
69.
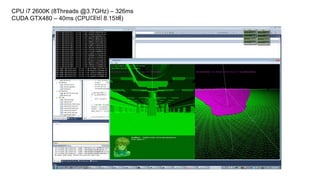
충돌처리 성능 테스트
•테스트 조건
타원체 7657개(최대 8192개)
삼각형 77760개
타원체 VS 타원체, 타원체 VS 삼각형
유휴시간 없이 최대프레임으로 충돌처리를 수행.
한번 충돌처리에 걸리는 시간 측정.
70.
CPU i7 2600K(8Threads @3.7GHz) – 326ms
CUDA GTX480 – 40ms (CPU대비 8.15배)
71.
게임 클라이언트에서 사용
•하나의 GPU로 렌더링과 CUDA처리를 겸하게 되면
퍼포먼스 하락.
• PCI-E버스 병목도 원인.
• GPU가 두개 꽂힌 시스템이라면 게임
클라이언트에서도 프레임향상에 도움이 된다.
• 두번째 GPU로 충돌처리를 하면 응답시간이 더
빠르다. (캐릭터 100마리일 때 약 3~4배 차이)
72.
CUDA적용의 장점
• 가격대비 성능이 매우 뛰어나다.
• CPU자원의 여유를 확보할 수 있다..
• 같은 기능의 코드를 CPU와 GPU 양쪽에서 동시
처리해도 좋다. 성능 2x이상 향상.
• 확장성에는 큰 도움이 된다.
• 새로운 GPU가 나올때마다 성능이 크게 향상된다.
• 기술 덕후의 호기심을 충족시킨다.
73.
CUDA적용의 단점or걸림돌
• 단순포팅은 의미가 없으므로 코드를 상당 부분
수정해야한다.
• GPU에 맞춰서 최적화 하고나면 코드가
아스트랄해진다. 유지보수가 어렵다.
• 디버깅이 지랄같다.
(희소식! Parallel Nsight 2.2에서 드디어 싱글 GPU
디버깅이 가능해졌다!!!)
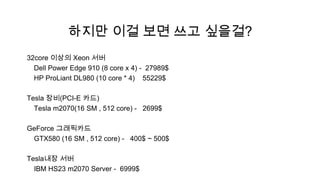
하지만 이걸 보면쓰고 싶을걸?
32core 이상의 Xeon 서버
Dell Power Edge 910 (8 core x 4) - 27989$
HP ProLiant DL980 (10 core * 4) 55229$
Tesla 장비(PCI-E 카드)
Tesla m2070(16 SM , 512 core) - 2699$
GeForce 그래픽카드
GTX580 (16 SM , 512 core) - 400$ ~ 500$
Tesla내장 서버
IBM HS23 m2070 Server - 6999$





































![단순포팅
• 처리하고 하는 [원소 1개 > thread 1개] 직접 맵핑
• 1 pixel -> 1 thread, 1 오브젝트-> 1스레드
• C로 짠 코드는 거의 100% 그대로 돌릴 수 있다.
• 이미지 프로세싱 매트릭스 연산 등에선 충분히
효과가 있다.](https://image.slidesharecdn.com/gpgpummog-120424105409-phpapp01/85/GPGPU-CUDA-MMOG-39-320.jpg)




![Worst Case
DWORD ThreadIndexInBlock = threadIdx.y * blockDim.x + threadIdx.x;
DWORD UniqueThreadIndex = UniqueBlockIndex * ThreadNumPerBlock + ThreadIndexInBlock;
int CountList[32] = {0,1,2,3,...,31};
// 32개의 스레드가 동시에 루프를 돈다.
for (int i=0; i<CountList[UniqueThreadIndex]; i++)
{
...
}
// CountList[UniqueThreadIndex] == 0 인 스레드도 CountList[UniqueThreadIndex] == 31인 스레드를
대기
// 모든 스레드가 가장 오래 걸리는 스레드에 맞춰서 움직인다.즉
// 모든 스레드가 31번 루프를 도는 것과 같다.](https://image.slidesharecdn.com/gpgpummog-120424105409-phpapp01/85/GPGPU-CUDA-MMOG-44-320.jpg)

![충돌처리 코드에서 SIMT를 고려한 설계
• 충돌처리의 경우 Loop를 돌며 인접한 삼각형과
오브젝트(타원체)를 찾는 코드에서 가장 많은 시간을
잡아먹는다.
• WARP단위로 명령어를 실행하기 때문에 삼각형과
타원체를 찾는 루프에서 대부분의 코어가 논다.
• [1개의 Thread가 N번 Loop -> M개의 Thread가
N/M번의 Loop] 로 수정](https://image.slidesharecdn.com/gpgpummog-120424105409-phpapp01/85/GPGPU-CUDA-MMOG-46-320.jpg)



























![[NDC2016] TERA 서버의 Modern C++ 활용기](https://cdn.slidesharecdn.com/ss_thumbnails/v09teramodernc20160425-160427044156-thumbnail.jpg?width=640&height=640&fit=bounds)
![[0903 구경원] recast 네비메쉬](https://cdn.slidesharecdn.com/ss_thumbnails/0903recast-111221053315-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[야생의 땅: 듀랑고] 서버 아키텍처 Vol. 2 (자막)](https://cdn.slidesharecdn.com/ss_thumbnails/vol2-160427160825-thumbnail.jpg?width=640&height=640&fit=bounds)





![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[NDC 2018] 신입 개발자가 알아야 할 윈도우 메모리릭 디버깅](https://cdn.slidesharecdn.com/ss_thumbnails/v7-180427162920-thumbnail.jpg?width=640&height=640&fit=bounds)




![[0122 구경원]게임에서의 충돌처리](https://cdn.slidesharecdn.com/ss_thumbnails/random-110127021824-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Ndc11 박민근] deferred shading](https://cdn.slidesharecdn.com/ss_thumbnails/ndc11deferredshading-110602220043-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[조진현]Kgc2012 c++amp](https://cdn.slidesharecdn.com/ss_thumbnails/kgc2012camp-121019195944-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[조진현] [Kgc2011]direct x11 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/kgc2011directx11-111111212853-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[2B2]기계 친화성을 중심으로 접근한 최적화 기법](https://cdn.slidesharecdn.com/ss_thumbnails/2b2-140929202533-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























