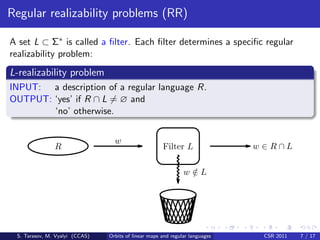
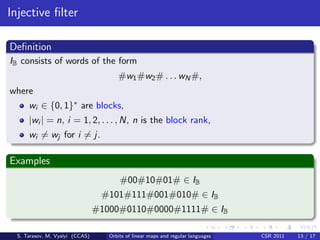
This document discusses the relationships between orbits of linear maps and regular languages. It shows that the chamber hitting problem (CHP) and permutation filter realizability problem are Turing equivalent. It also shows that the injective filter and surjective filter realizability problems are decidable by reducing them to problems about orbits. However, the regular realizability problem for the track product of the periodic and permutation filters is undecidable, as it can reduce the undecidable zero in the upper right corner problem.