Download to read offline

















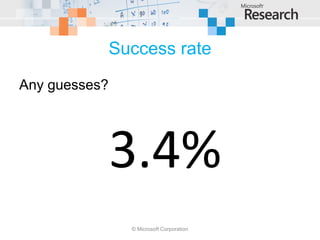
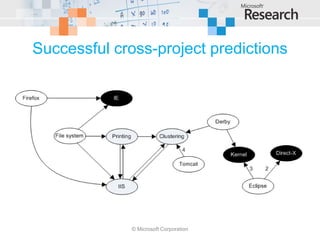












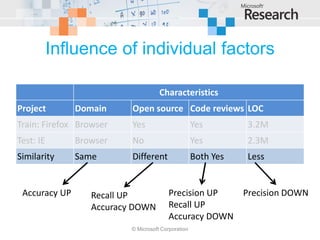
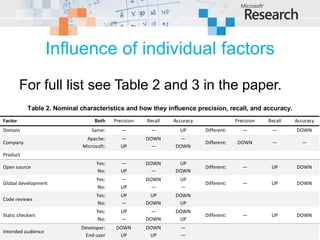
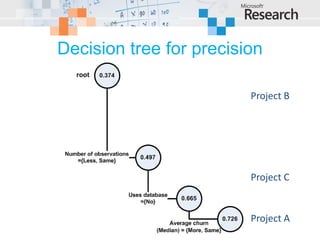



This document examines cross-project defect prediction, where a model trained on one project is used to predict defects in another project. In an experiment of 622 cross-project combinations across 12 systems, only 3.4% had successful predictions. However, certain project similarities like domain and characteristics like code reviews increased prediction precision and recall. Decision trees were created to help select project combinations where cross-project prediction is more likely to succeed based on characteristics like intended audience and pre-release bug metrics.























































































