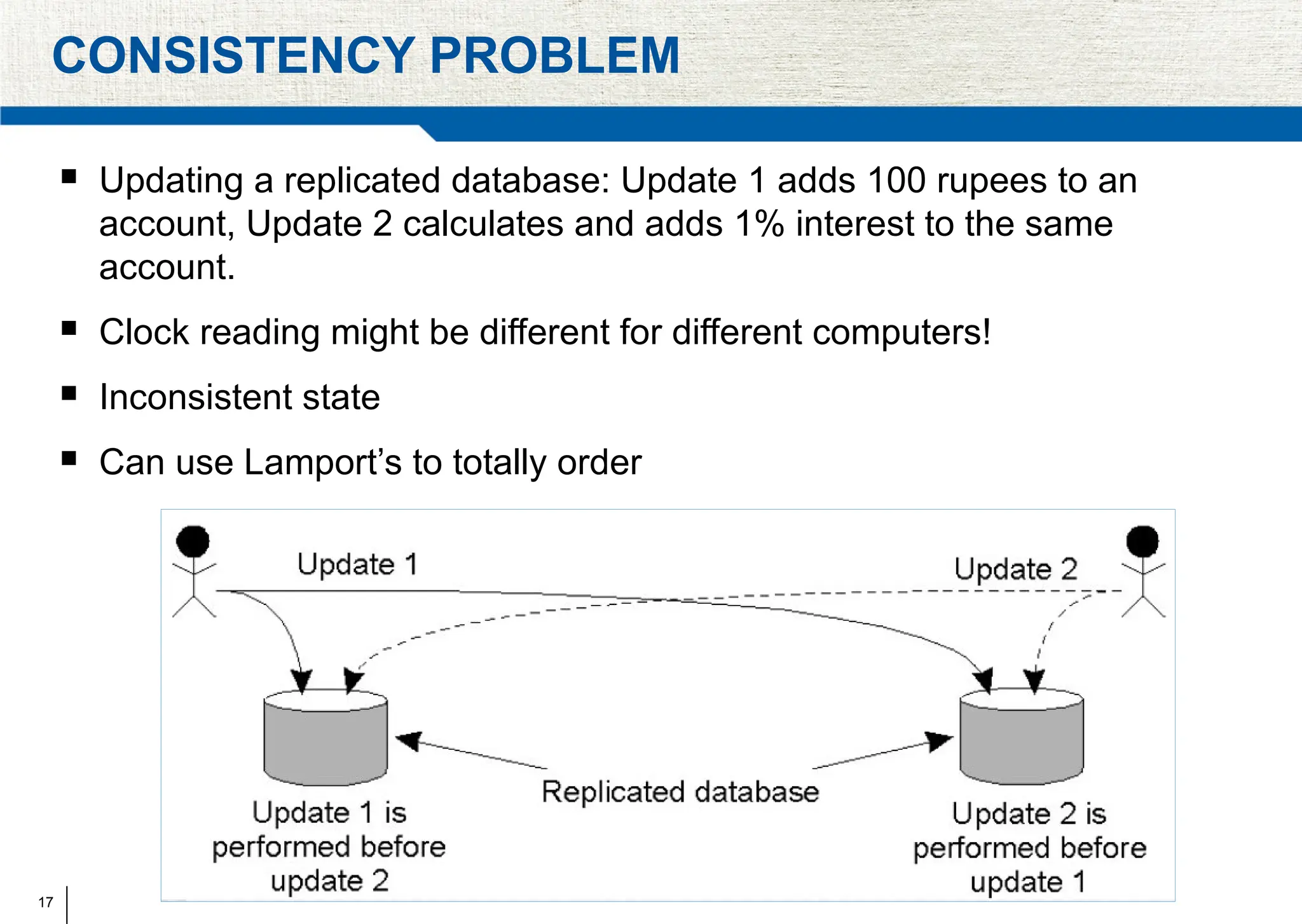
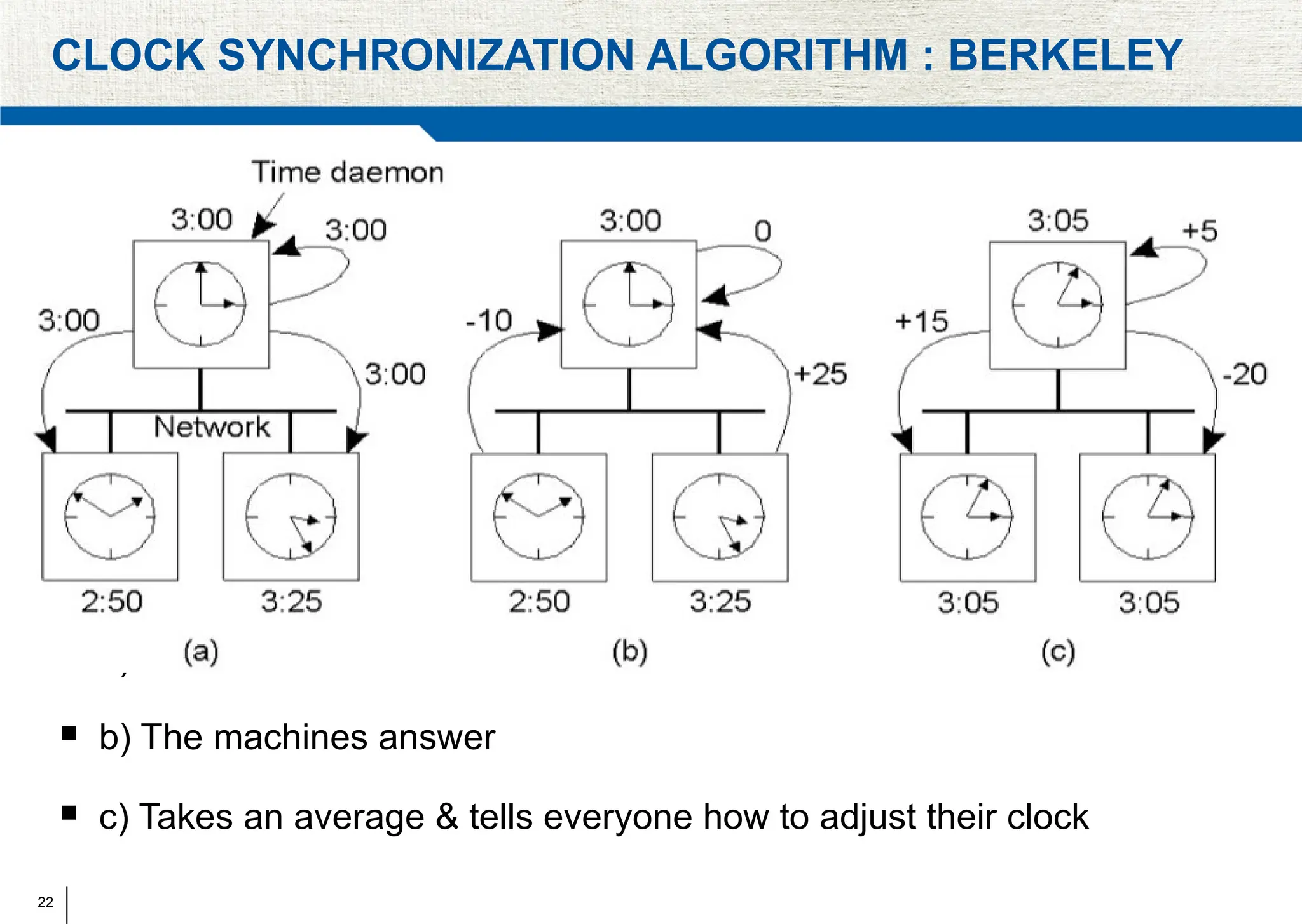
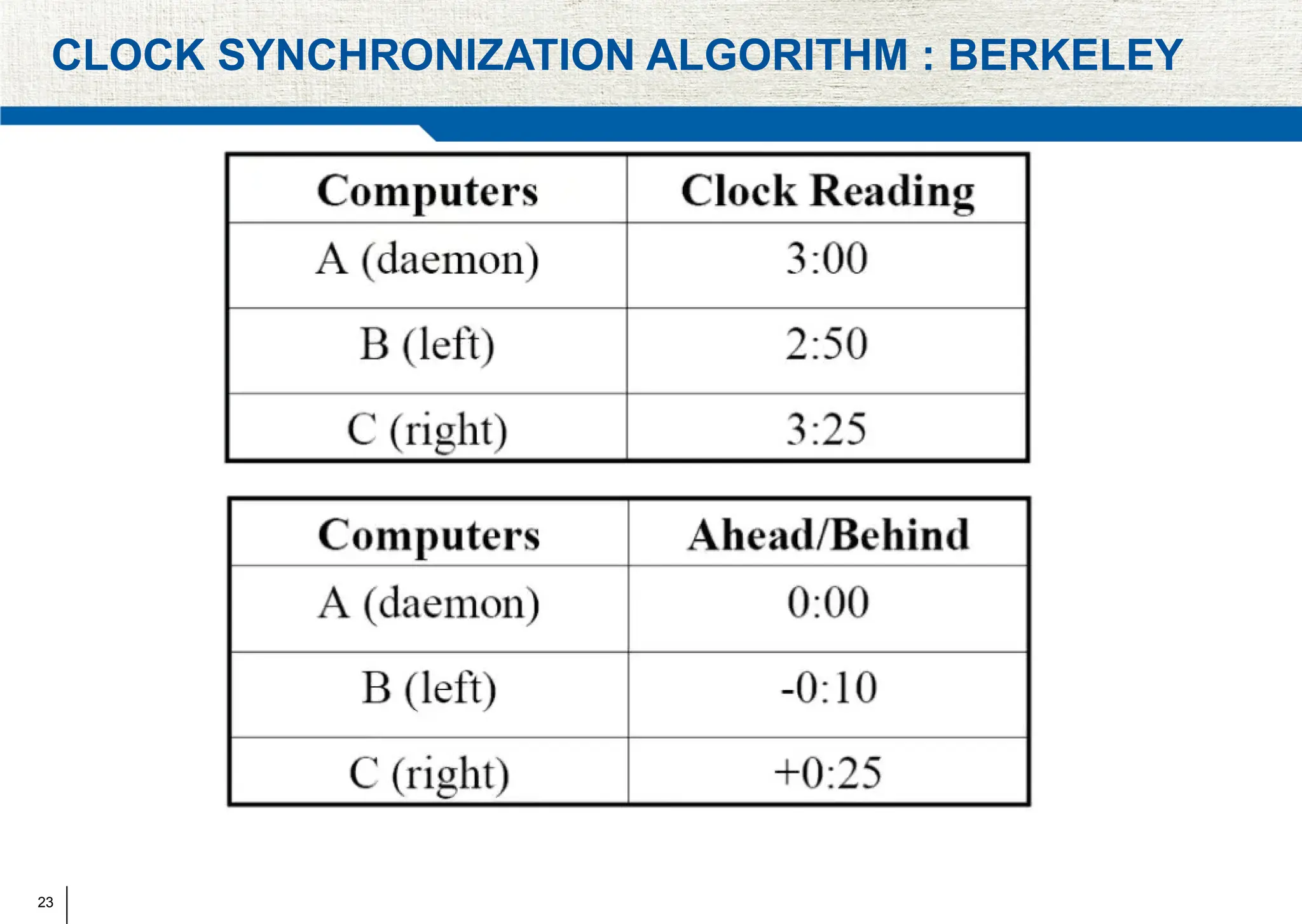
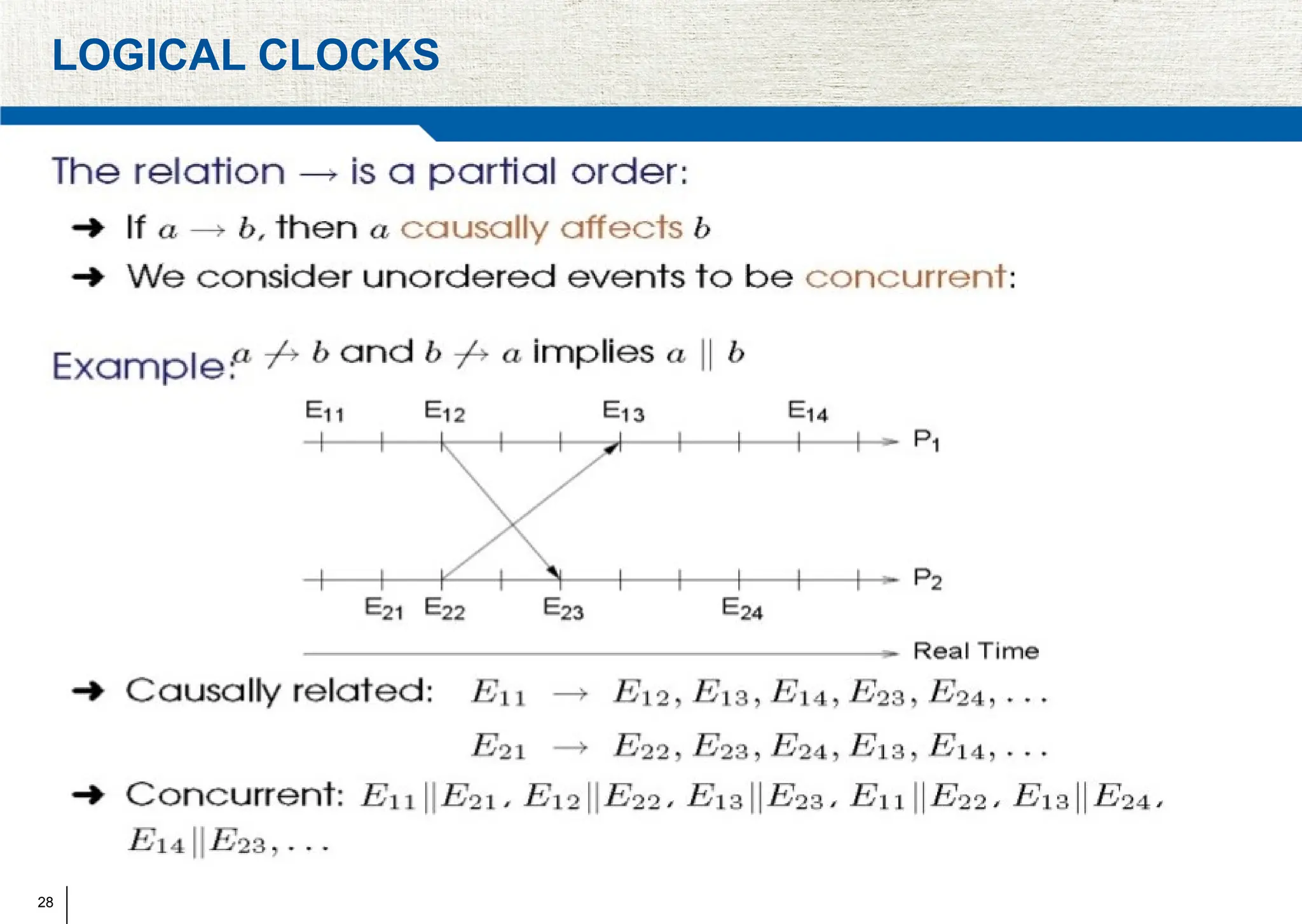
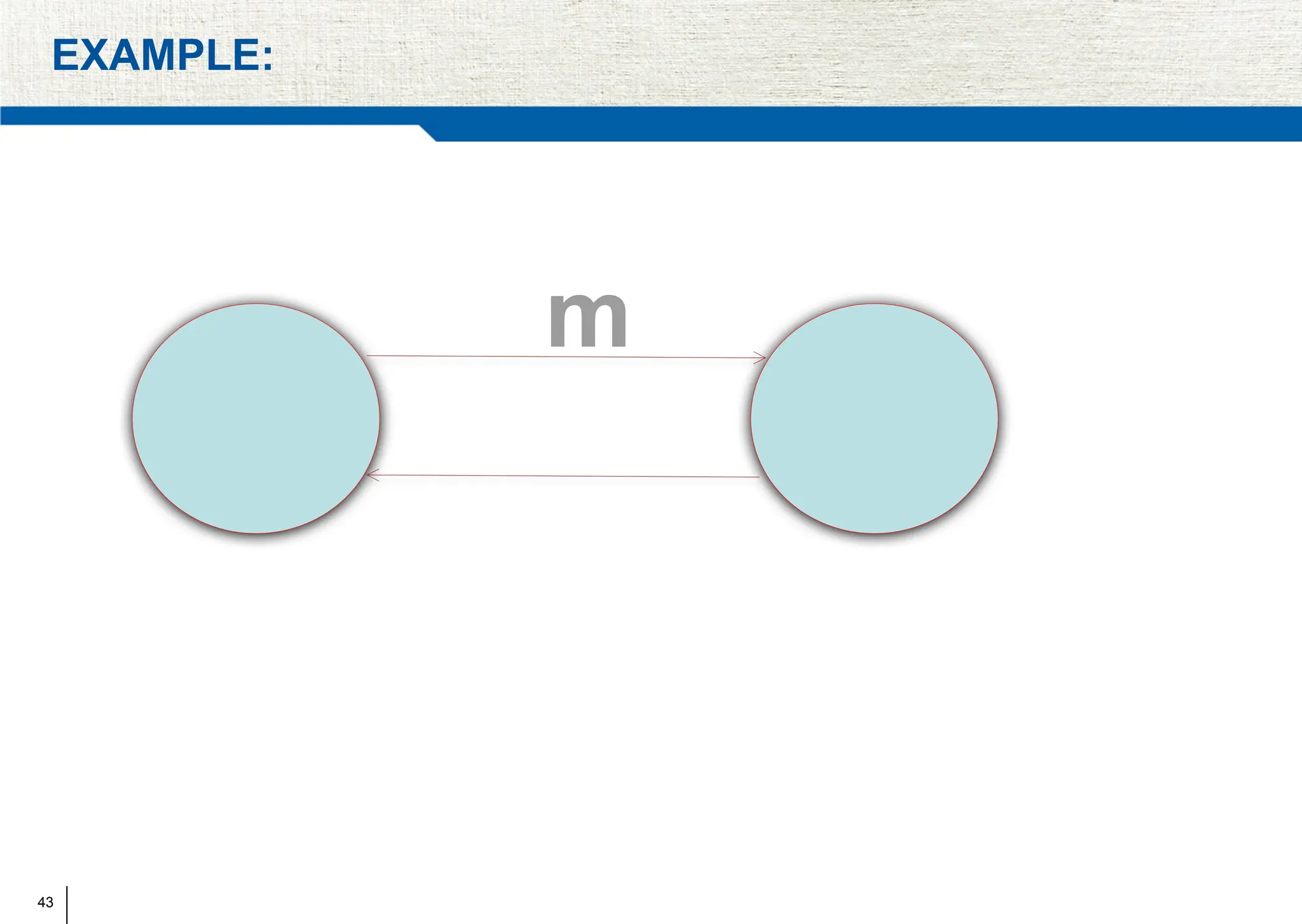
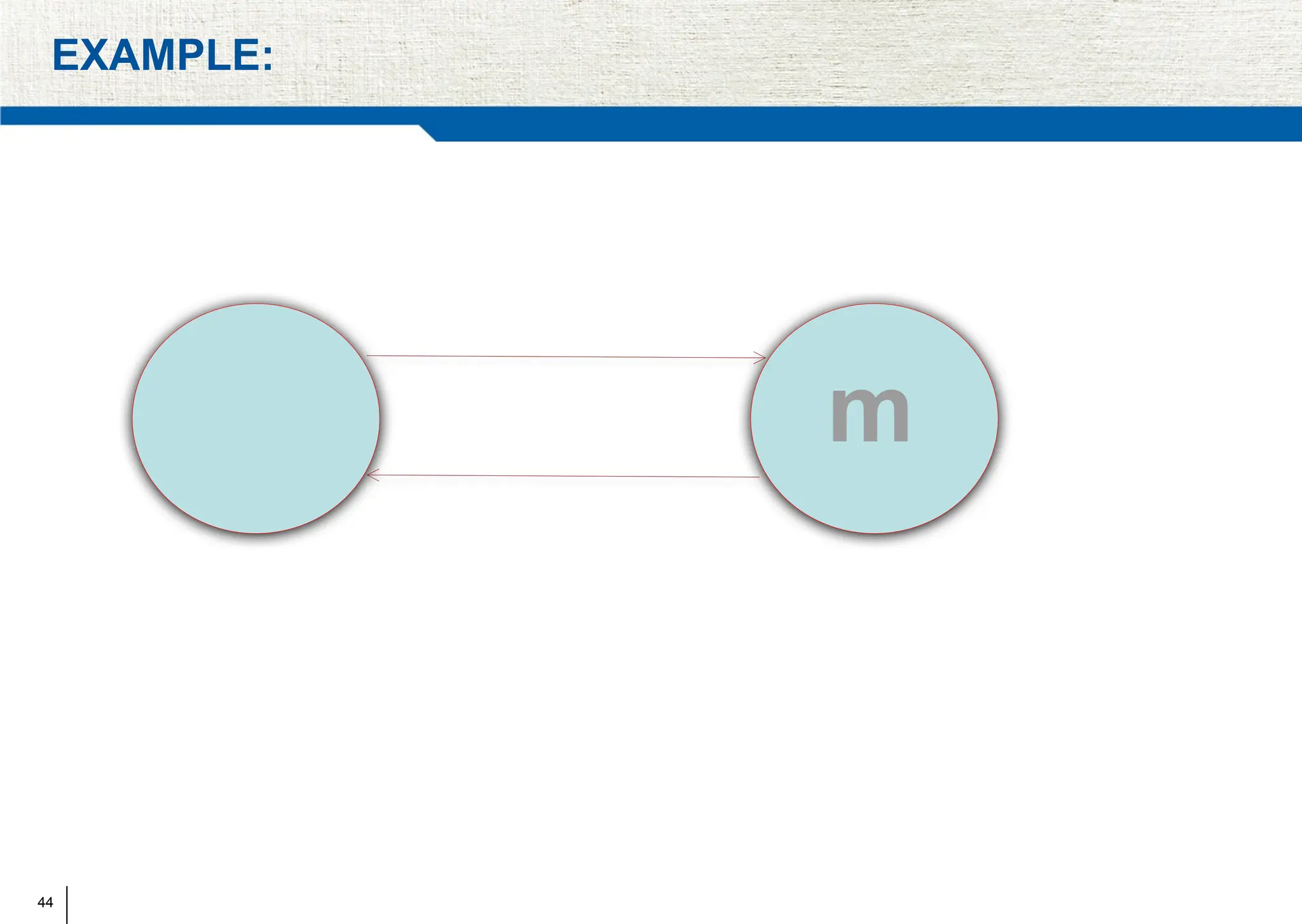
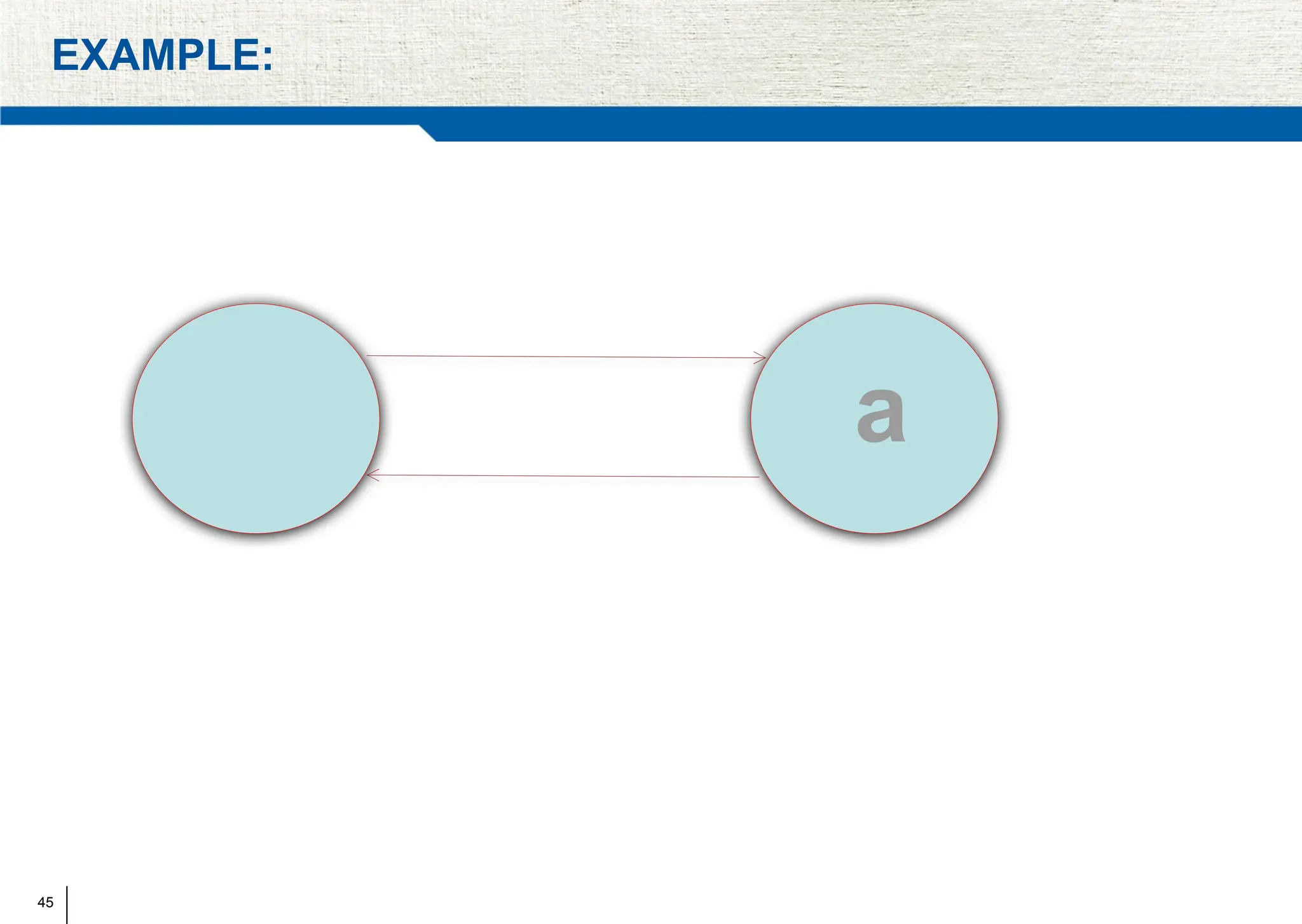
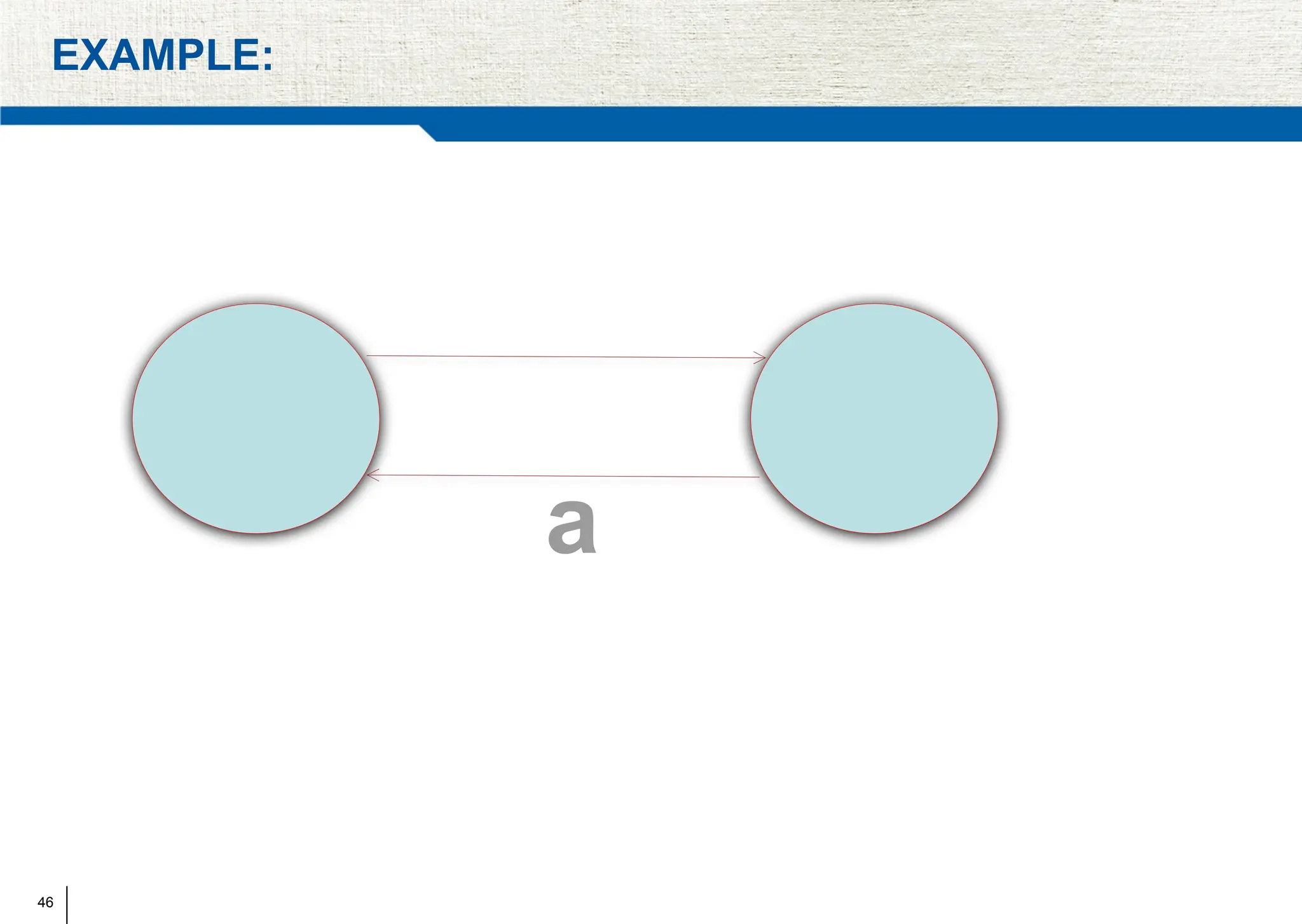
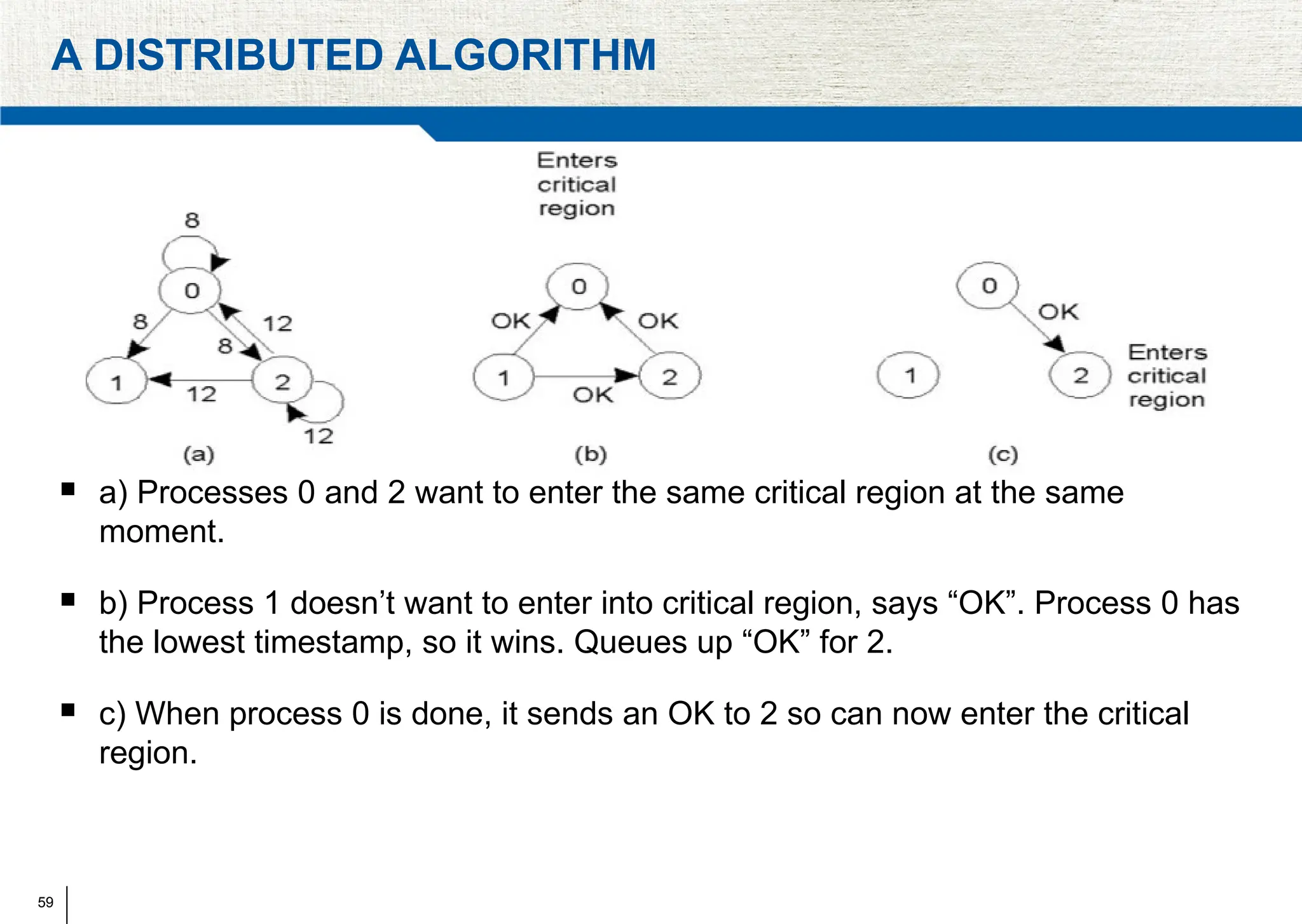
The document covers synchronization in distributed computing, outlining key topics such as distributed algorithms, coordination, time management, and concurrency control. It distinguishes between synchronous and asynchronous systems, discusses clock synchronization methods, and addresses challenges in determining global states within these systems. Additionally, it explores various mutual exclusion mechanisms and their comparative advantages, including centralized, token ring, and multicast approaches.














































































![Social network analysis [SNA] is the mapping and measuring of relationships a...](https://cdn.slidesharecdn.com/ss_thumbnails/representationandclassesofproerties-241121092336-8d88e173-thumbnail.jpg?width=640&height=640&fit=bounds)


























