Downloaded 189 times










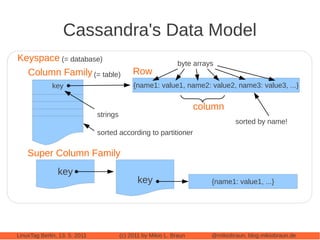
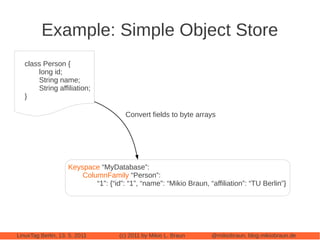
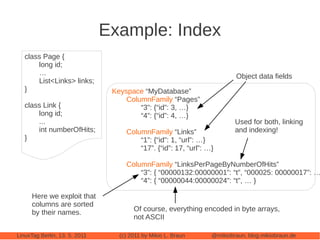

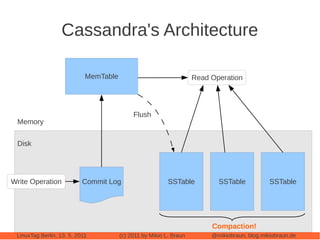

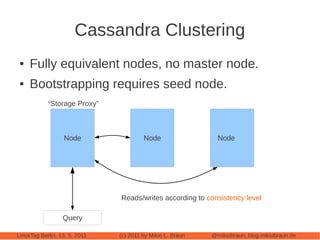




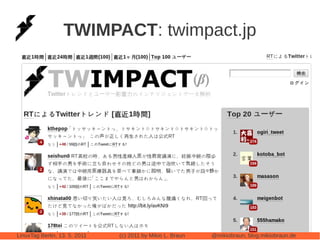


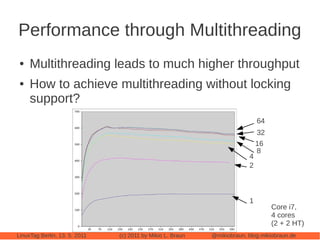
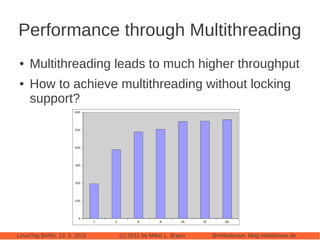

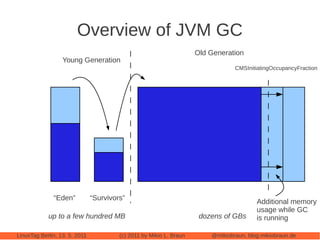
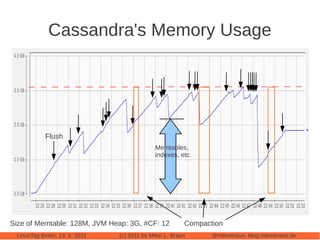

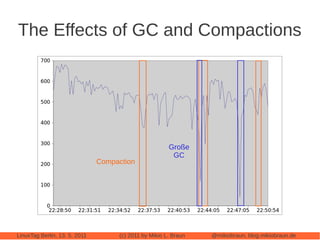





This document provides an introduction to Cassandra, a distributed database management system. It begins with an overview of Cassandra and how it compares to traditional databases. Key aspects discussed include that Cassandra uses a simple query language, scales out through clustering rather than up on larger servers, does not require a fixed database schema, and is eventually consistent. The document then covers Cassandra's data model, architecture, configuration, usage, performance considerations and tuning. Real-world experiences with Cassandra in a Twitter analytics application are also shared.





























































