Download as PDF, PPTX


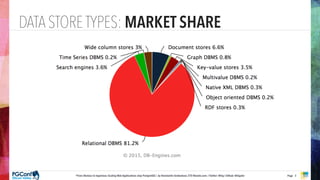
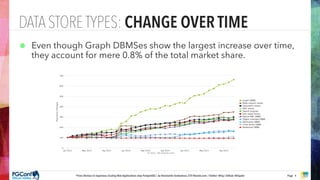

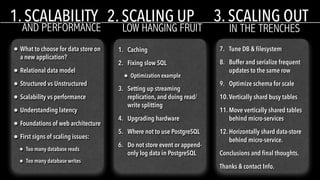






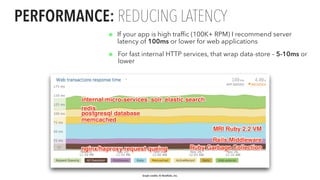
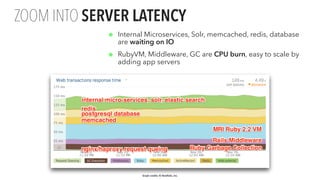






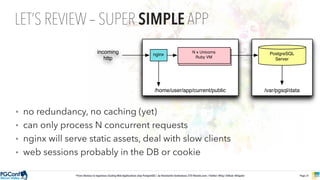
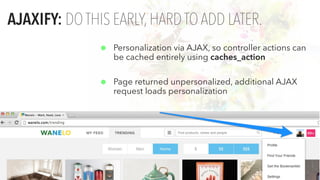

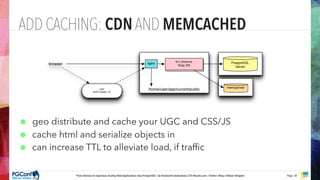


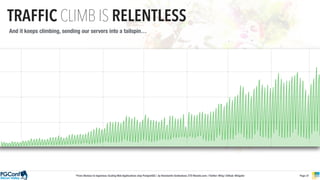


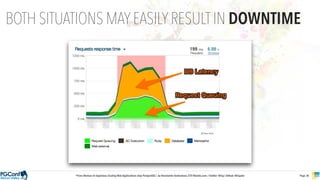














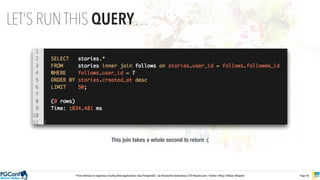






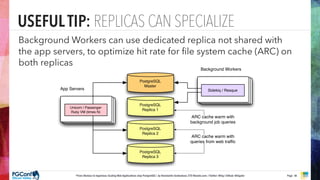
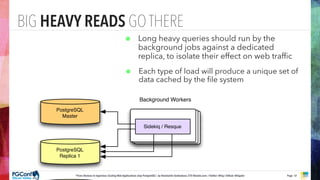





















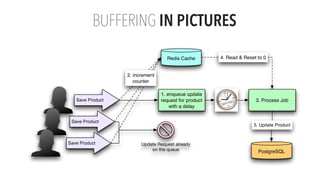





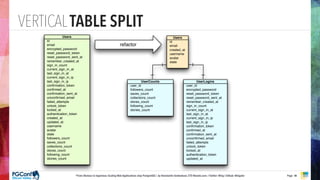



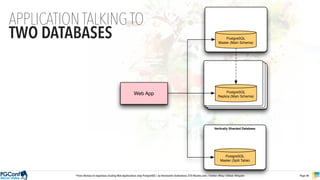
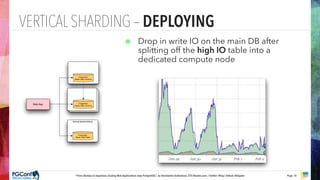


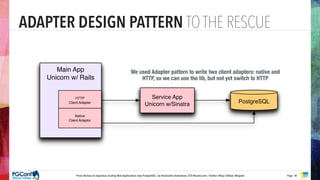


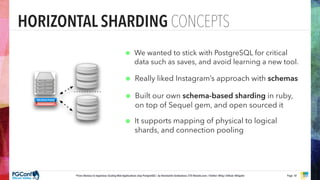



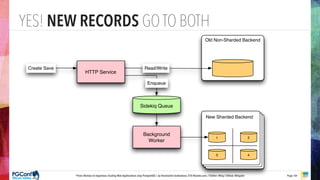
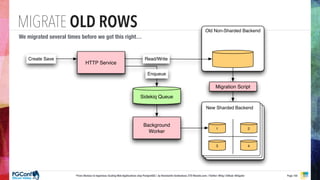
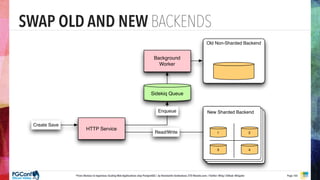

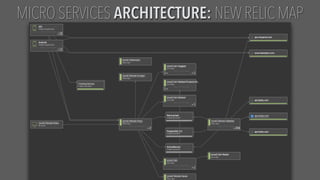






The document presents an updated version of Konstantin Gredeskoul's talk on scaling web applications using PostgreSQL, focusing on performance and scalability. It outlines different types of databases, the architecture necessary for handling high traffic, and specific strategies for optimizing PostgreSQL to deal with large amounts of concurrent users. Key recommendations include caching, tuning configurations, and various scaling approaches to maintain optimal database performance.