Download to read offline


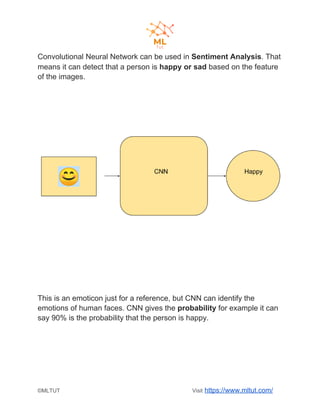













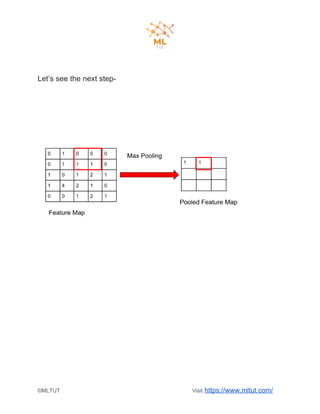




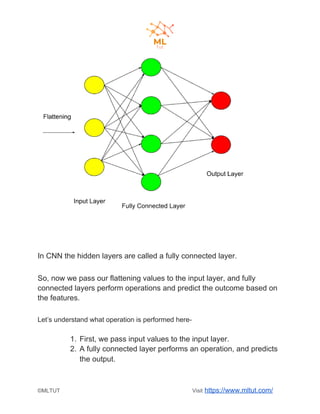


Convolutional neural networks (CNNs) are a type of deep learning algorithm used for image recognition and natural language processing. CNNs take an image as input and identify features to predict and classify the image. The key steps in a CNN include convolution, ReLU activation, pooling, flattening, and fully connected layers. Convolution extracts features using filters, pooling reduces dimensionality while preserving important information, and fully connected layers integrate the CNN with traditional neural networks for classification. Yann LeCun is credited as the father of CNNs, which are now widely used for applications like computer vision, facial recognition and sentiment analysis.































![[Revised] Intro to CNN](https://cdn.slidesharecdn.com/ss_thumbnails/googletechsprinttalkcnnintro-200730141604-thumbnail.jpg?width=640&height=640&fit=bounds)




























