Downloaded 60 times






![Jump Hashing implementation code
magic number
Ref: Consistent Hashing: Algorithmic Tradeoffs Google 提出的 Jump Consistent Hash
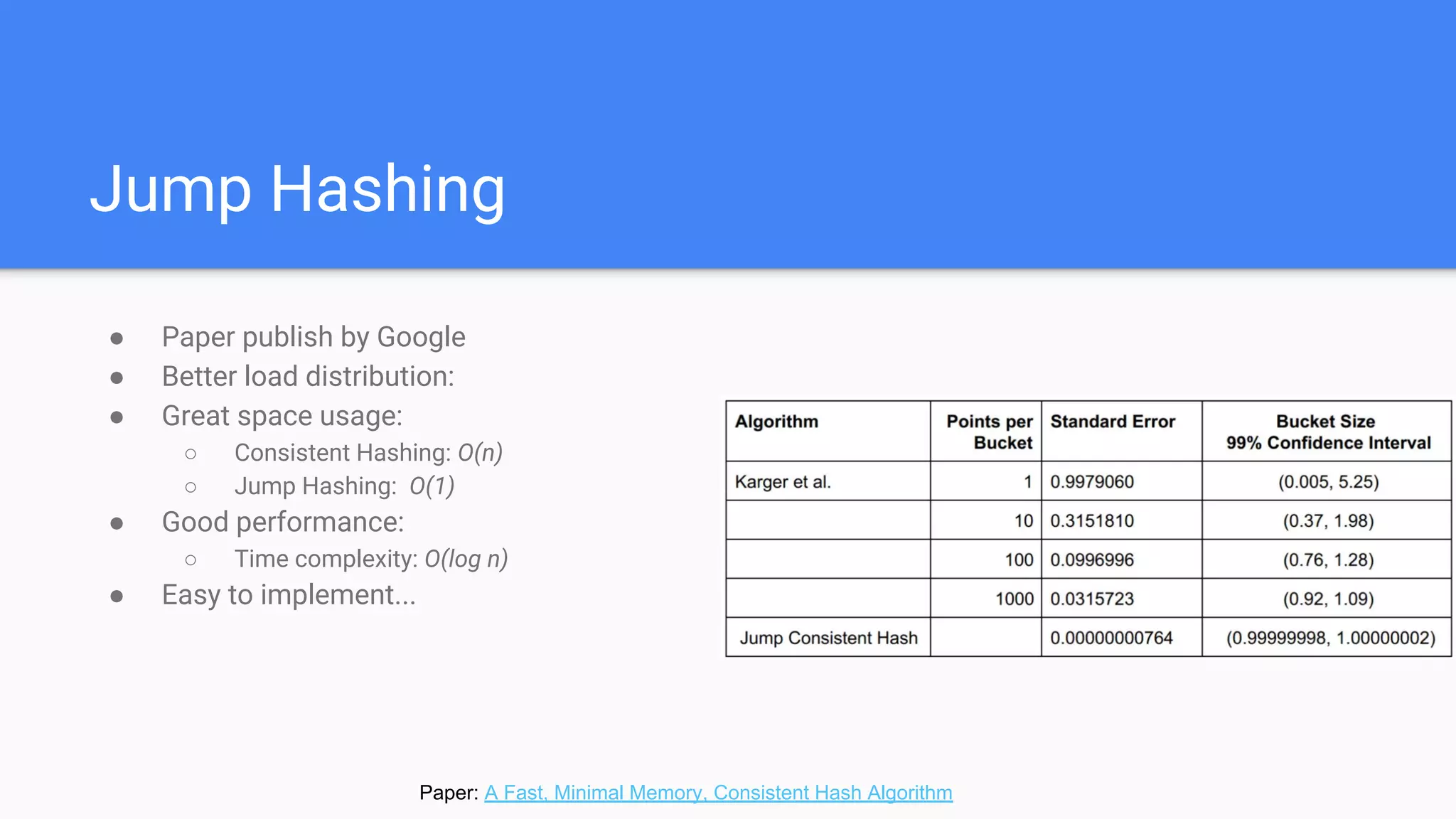
The time complexity of the algorithm is
determined by the number of iterations
of the while loop. [...] So the expected
number of iterations is less than ln(n) +
1.](https://image.slidesharecdn.com/consistenthashingalgorithmictradeoffs-180408123335/75/Consistent-hashing-algorithmic-tradeoffs-16-2048.jpg)









This document summarizes several consistent hashing algorithms: Mod-N hashing is simple but makes adding or removing servers difficult as it may require reconstructing the entire hashing table. Consistent hashing addresses this by using two hash functions - one for data and one for servers, placing them on a ring to distribute data. Jump hashing improves load distribution and reduces space usage to O(1) but does not support arbitrary node removal. Maglev hashing provides constant-time lookups but slow generation on node failure. Later algorithms aim to improve aspects like bounded load distribution and memory usage versus lookup speed. Overall, consistent hashing algorithms involve tradeoffs between these factors.
Introduction to consistent hashing and algorithmic tradeoffs. Agenda includes various hashing methods and their implications.
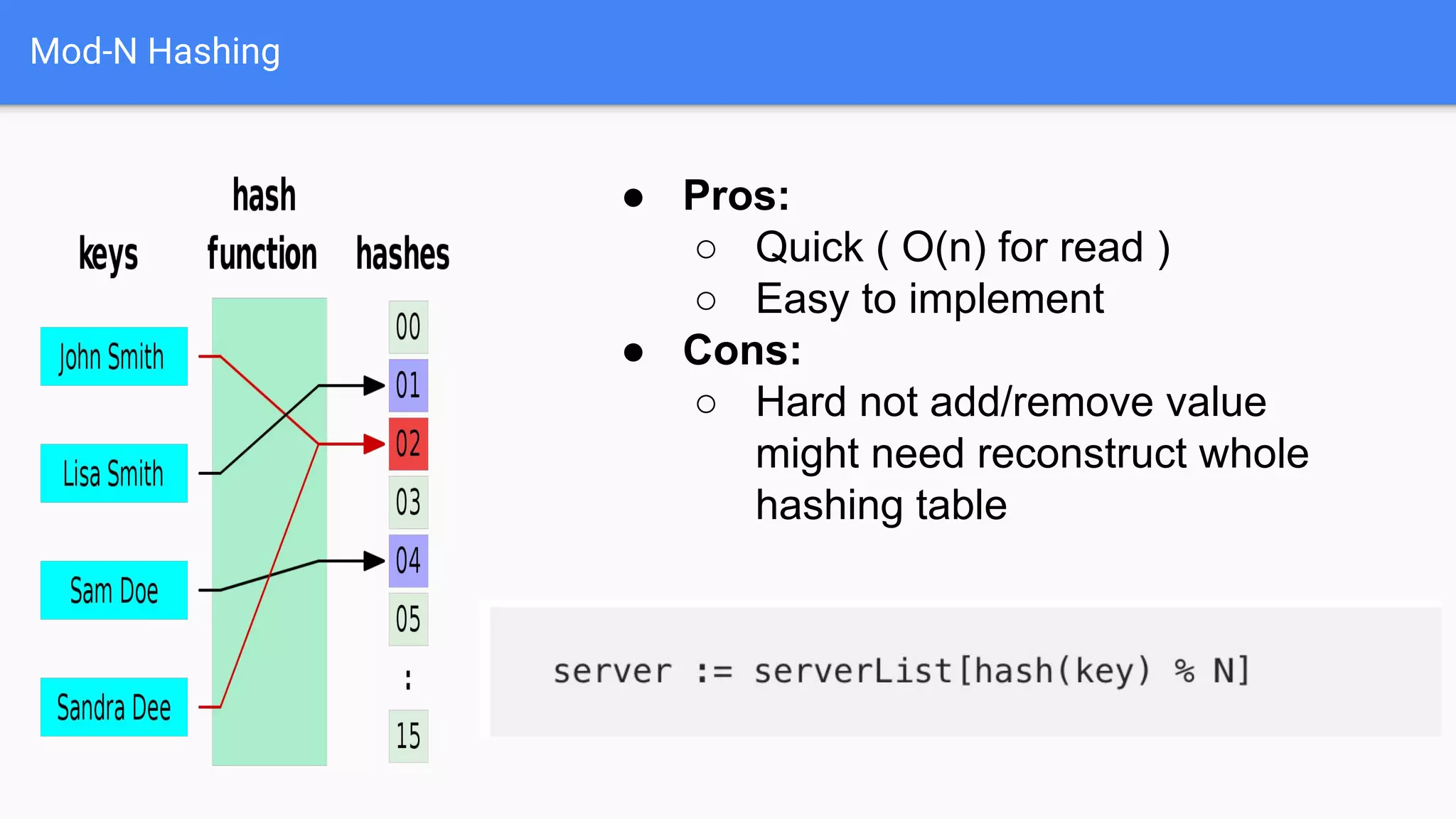
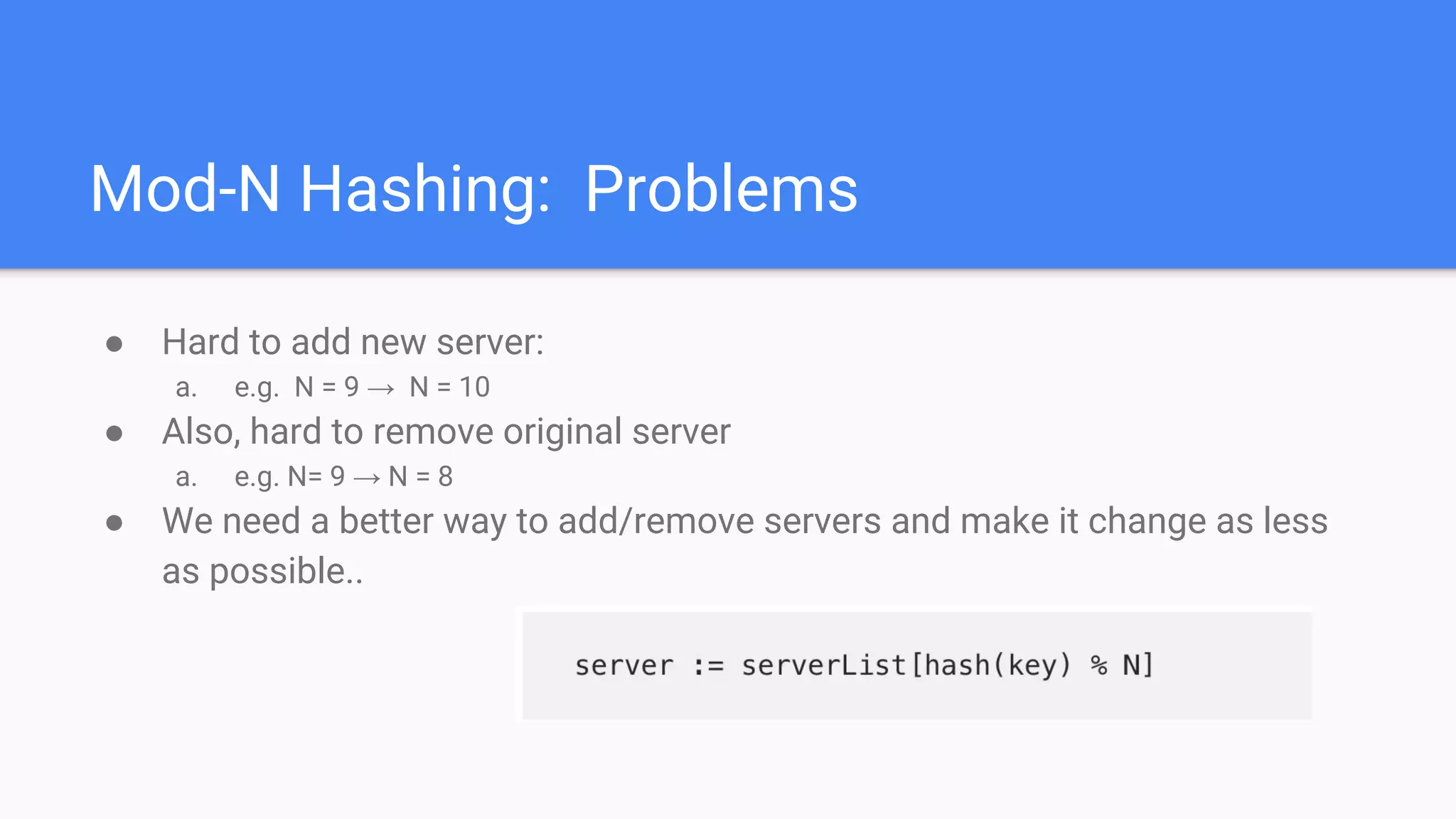
Identifies original problems with key-value storage and highlights challenges with Mod-N hashing, such as difficulties in adding/removing servers.
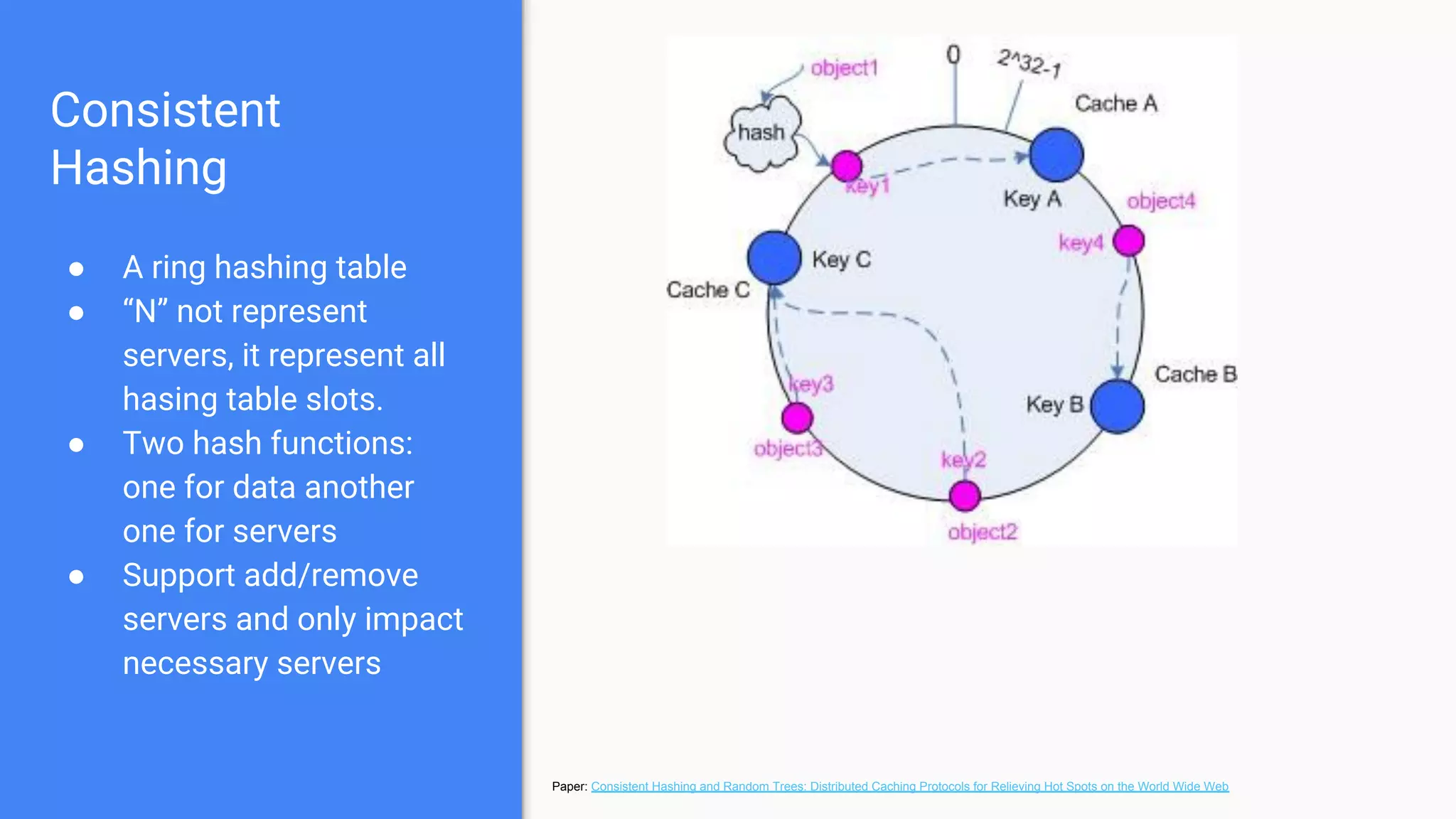
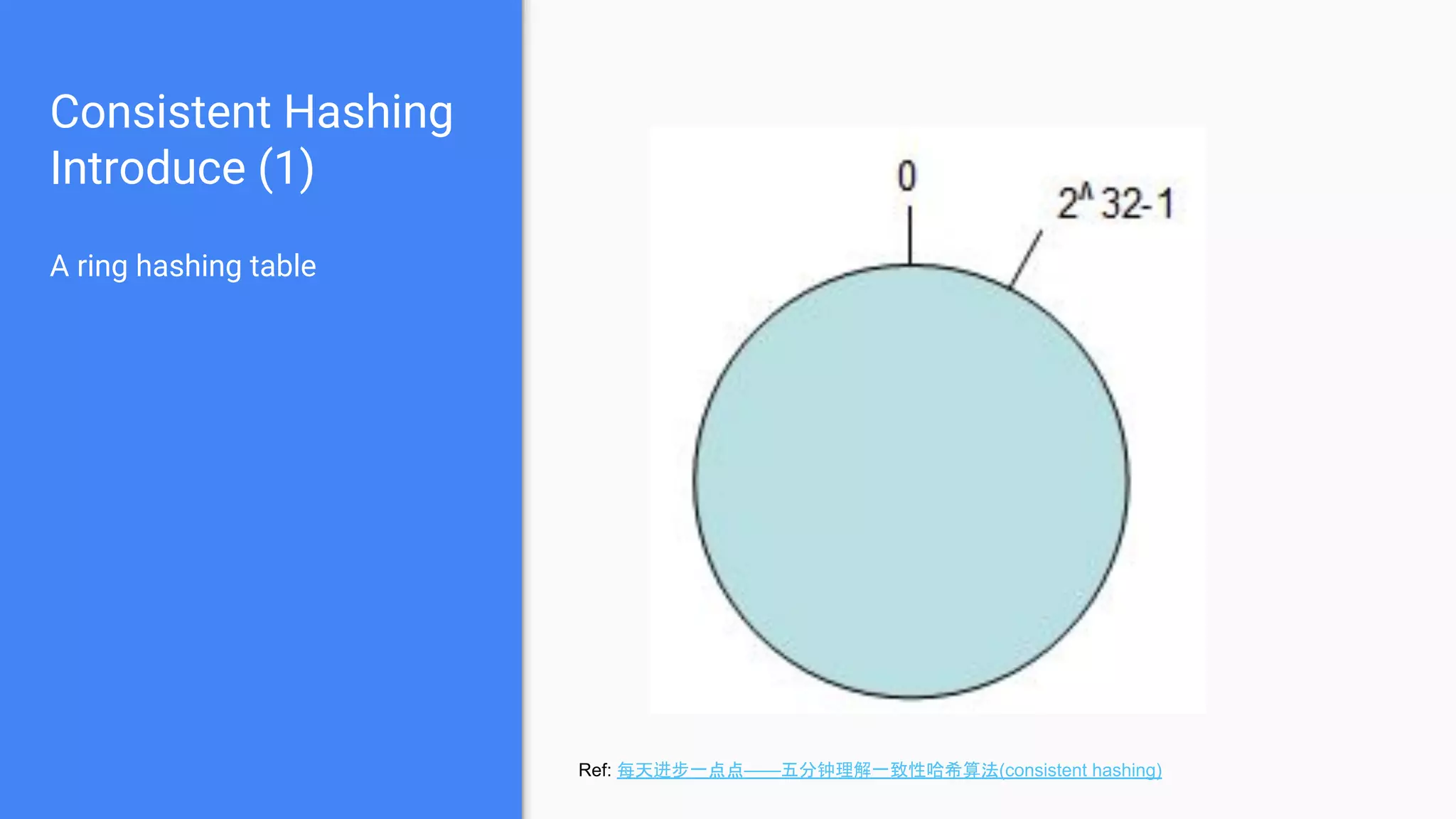
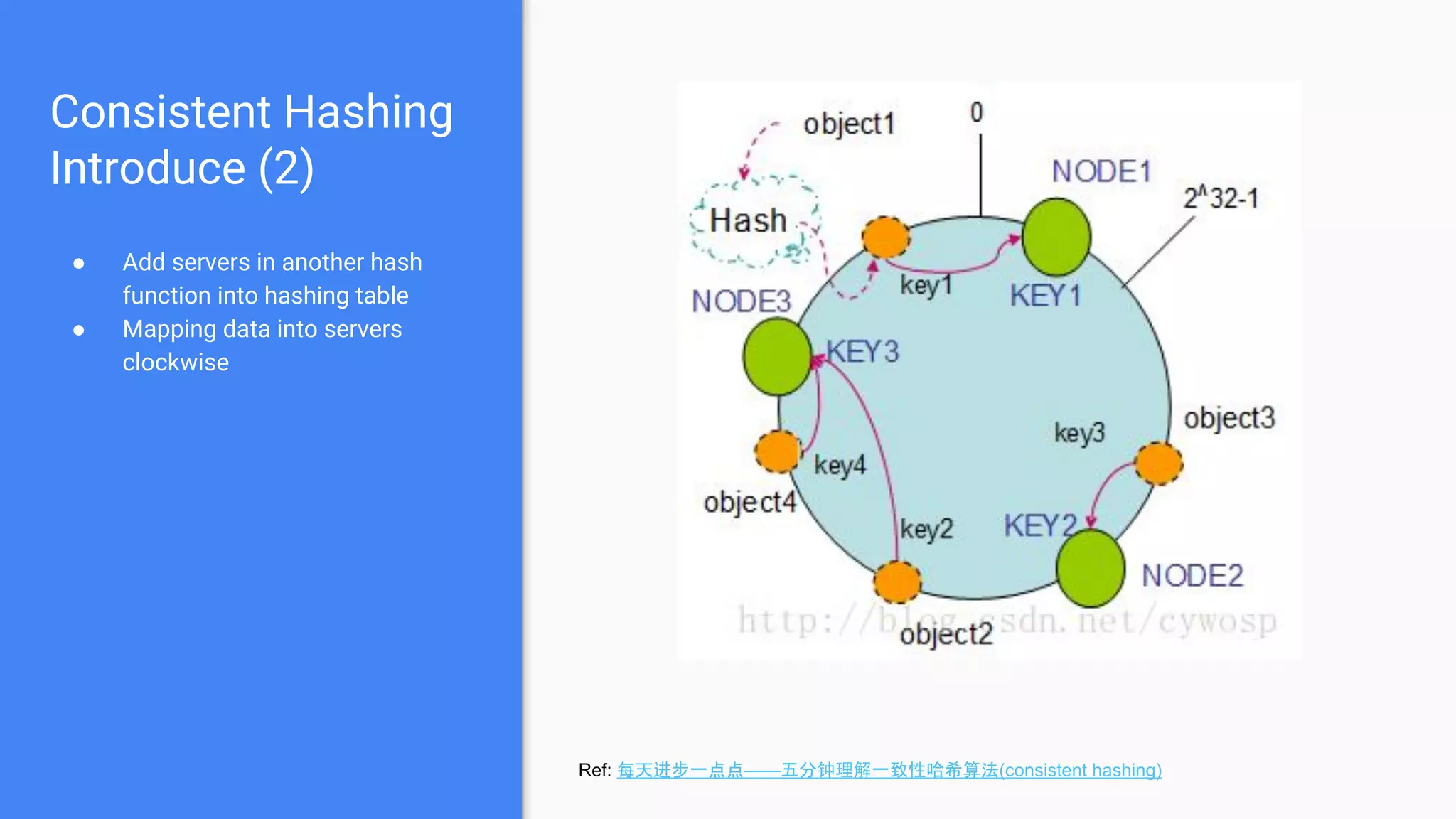
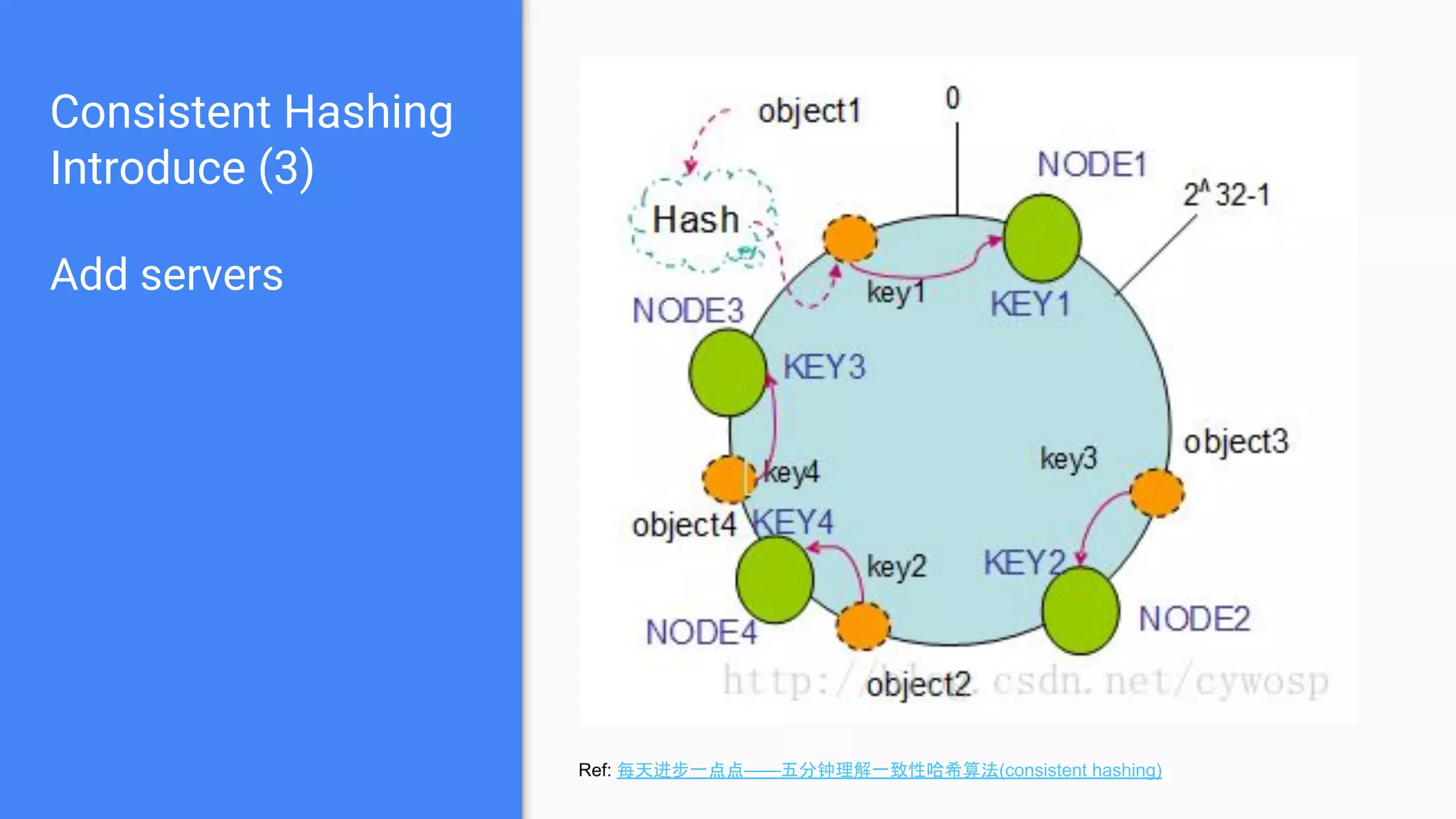
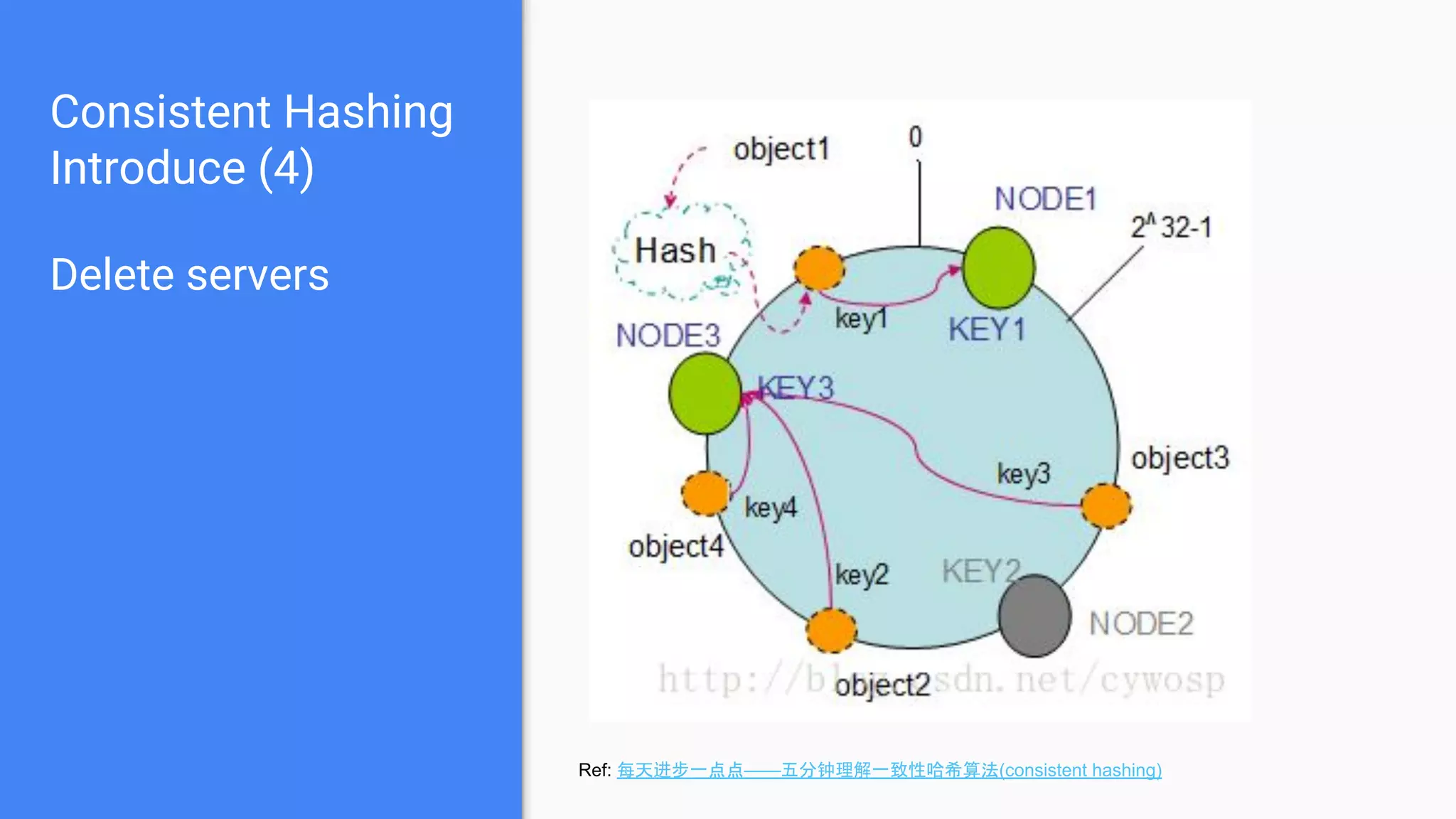
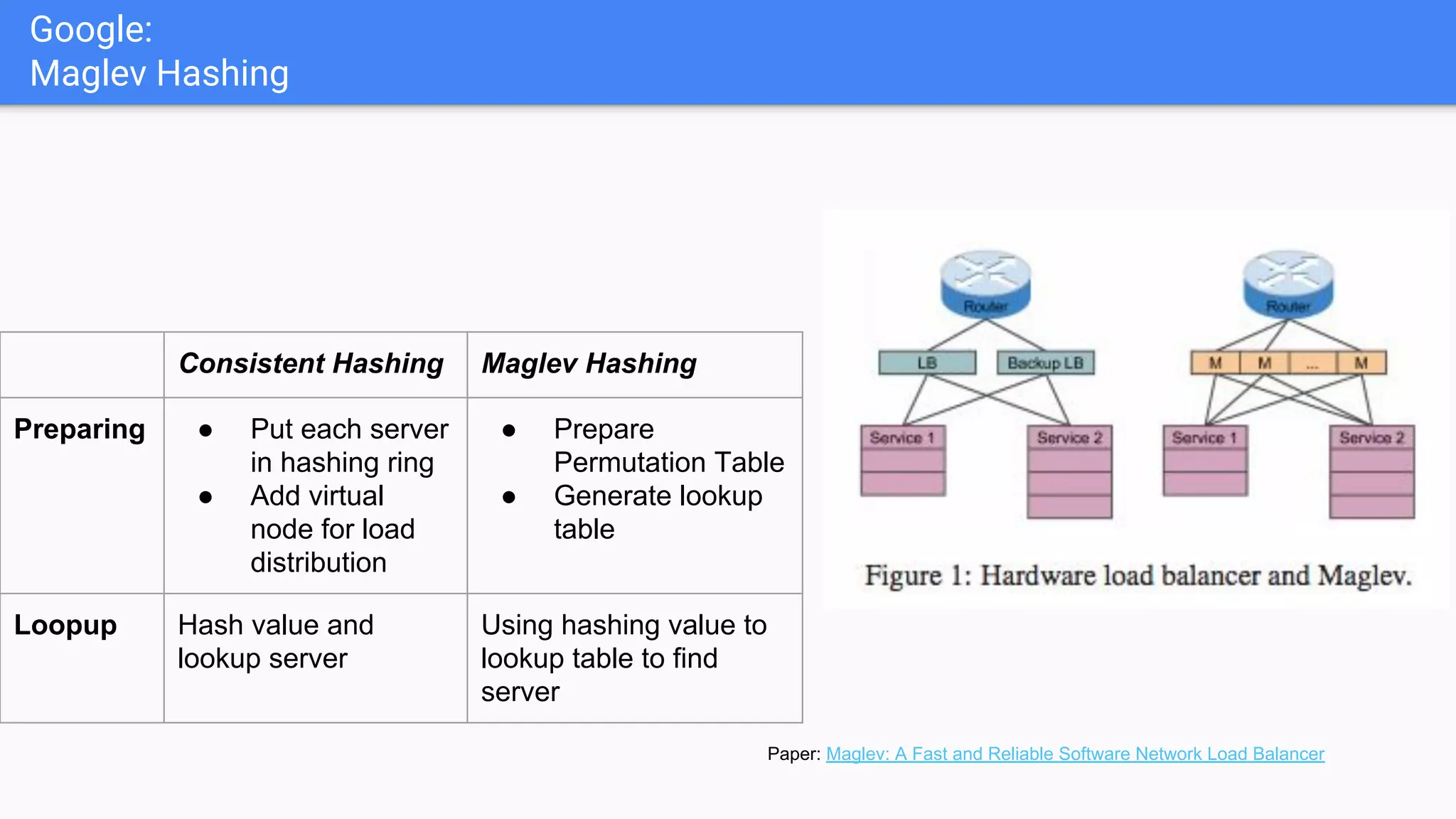
Discusses the concept of a ring hashing table, using two hash functions for data and servers, and the idea of virtual nodes to improve load balancing.
Examples of consistent hashing applications in systems like Apache Cassandra and Dynamo, and discusses load distribution metrics.
Introduction to Jump Hashing developed by Google, highlighting its space efficiency and limitations compared to consistent hashing.
Continued exploration into hashing methods including multiple-probe consistent hashing and Rendezvous hashing, discussing their efficiencies and tradeoffs.
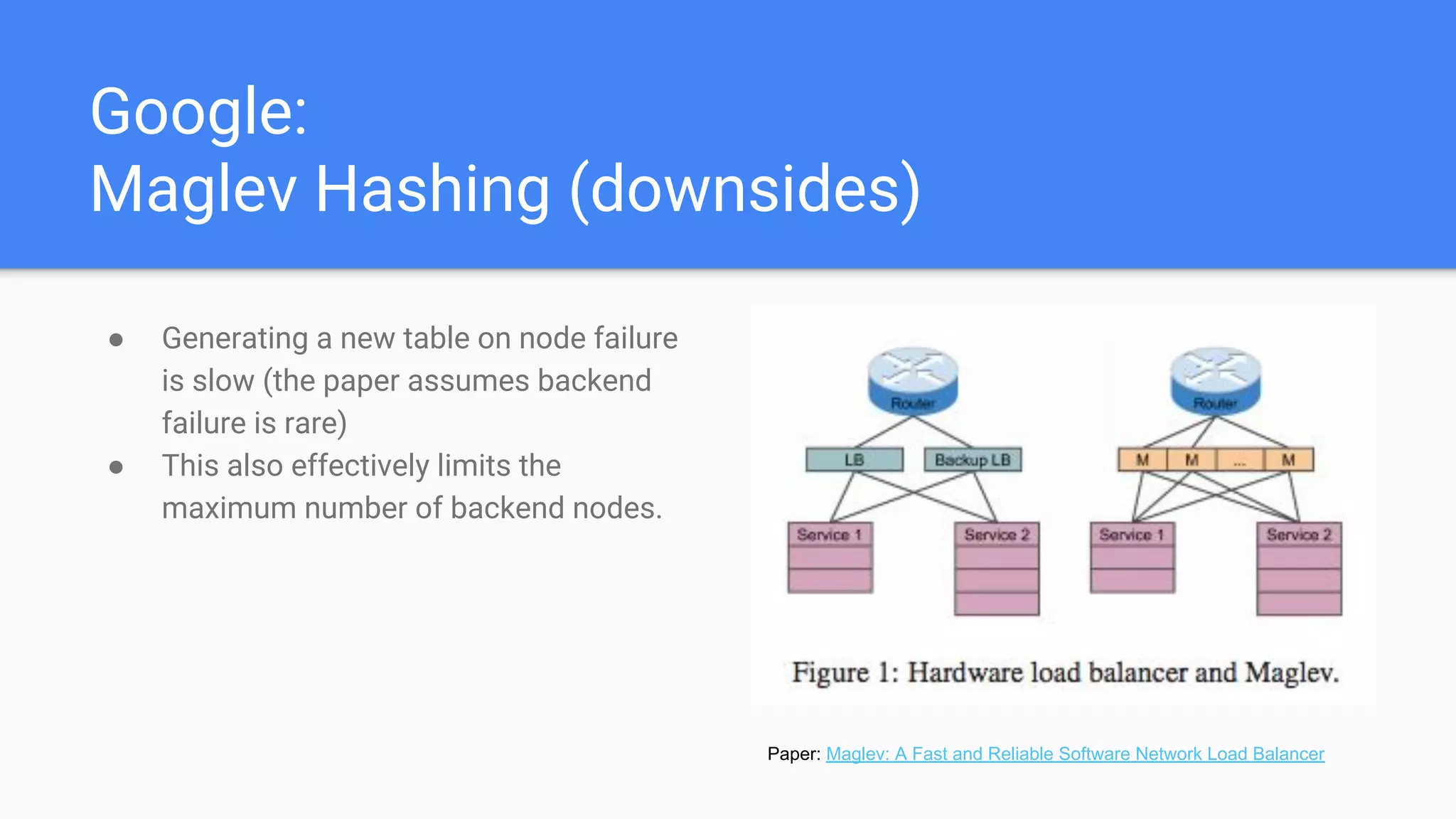
Overview of Maglev Hashing focusing on high lookup speed and low memory usage, but noting the challenges during node failures.
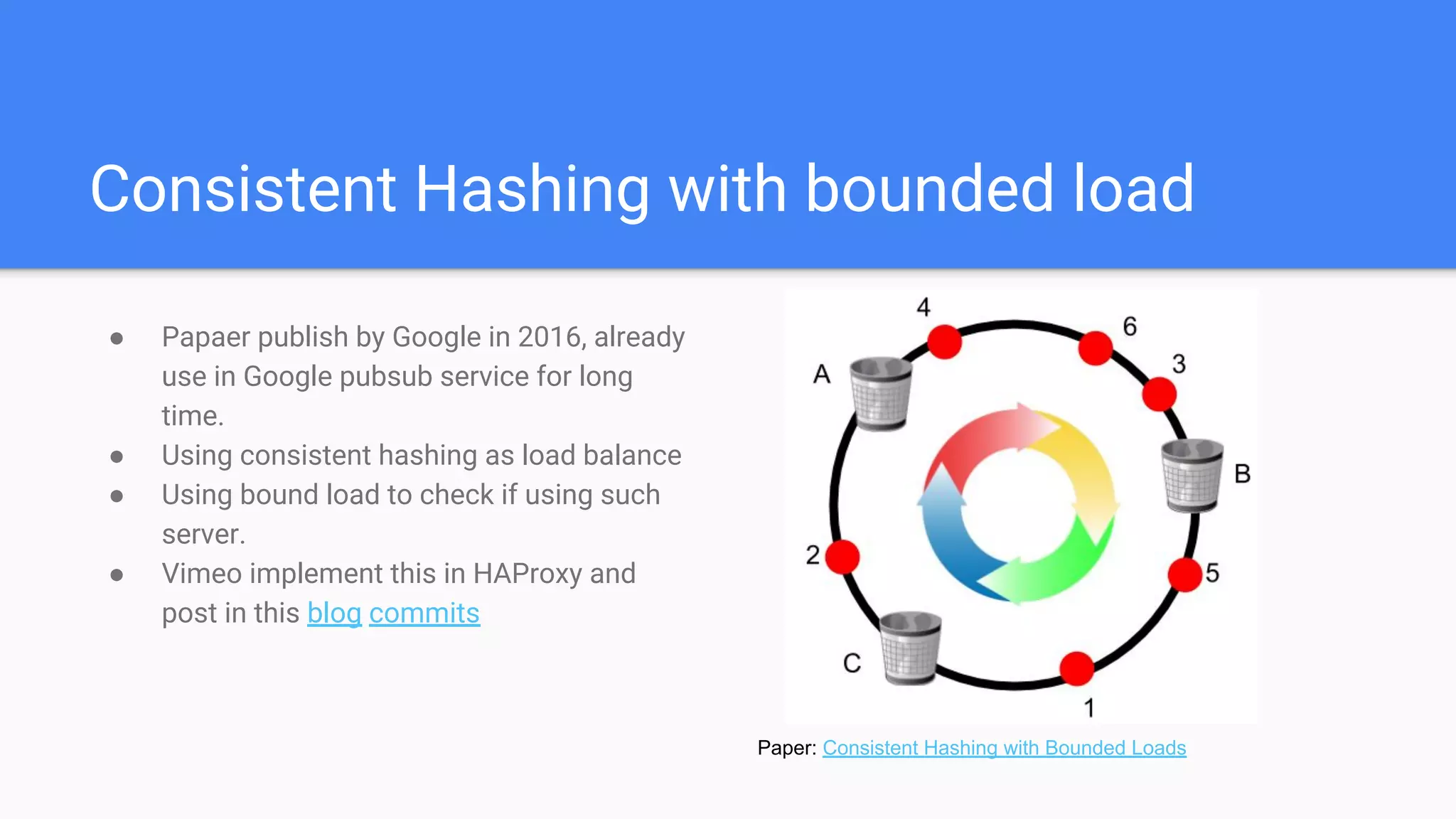
Step-by-step preparation and implementation of consistent hashing with bounded load, used in Google’s pubsub service and HAProxy.
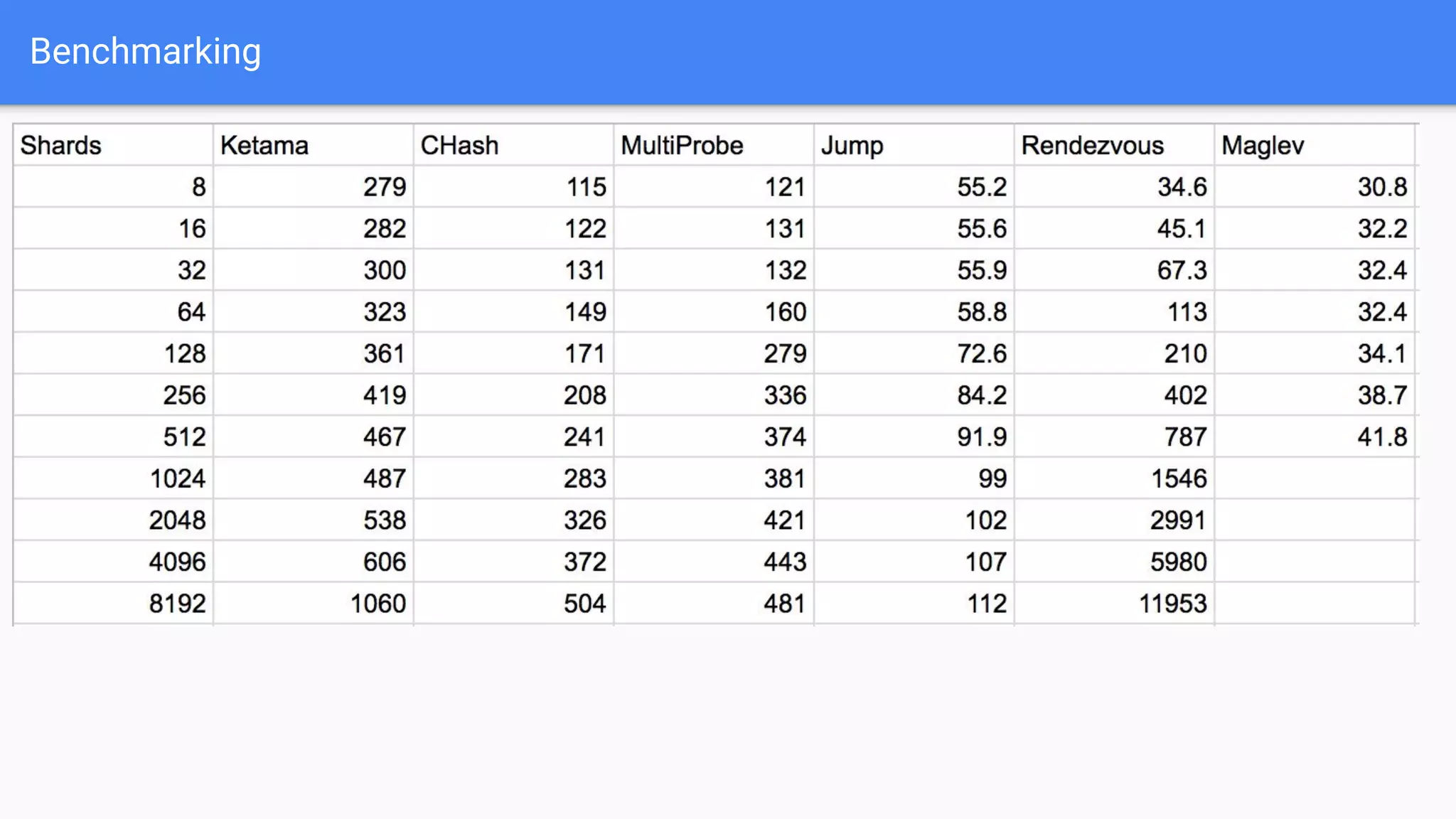
Discussion on benchmarking different hashing methods and the conclusion that no perfect consistent hashing algorithm exists with various tradeoffs.
Open forum for questions and answers regarding the presentation content and hashing techniques.




![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)



![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)





























































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)










