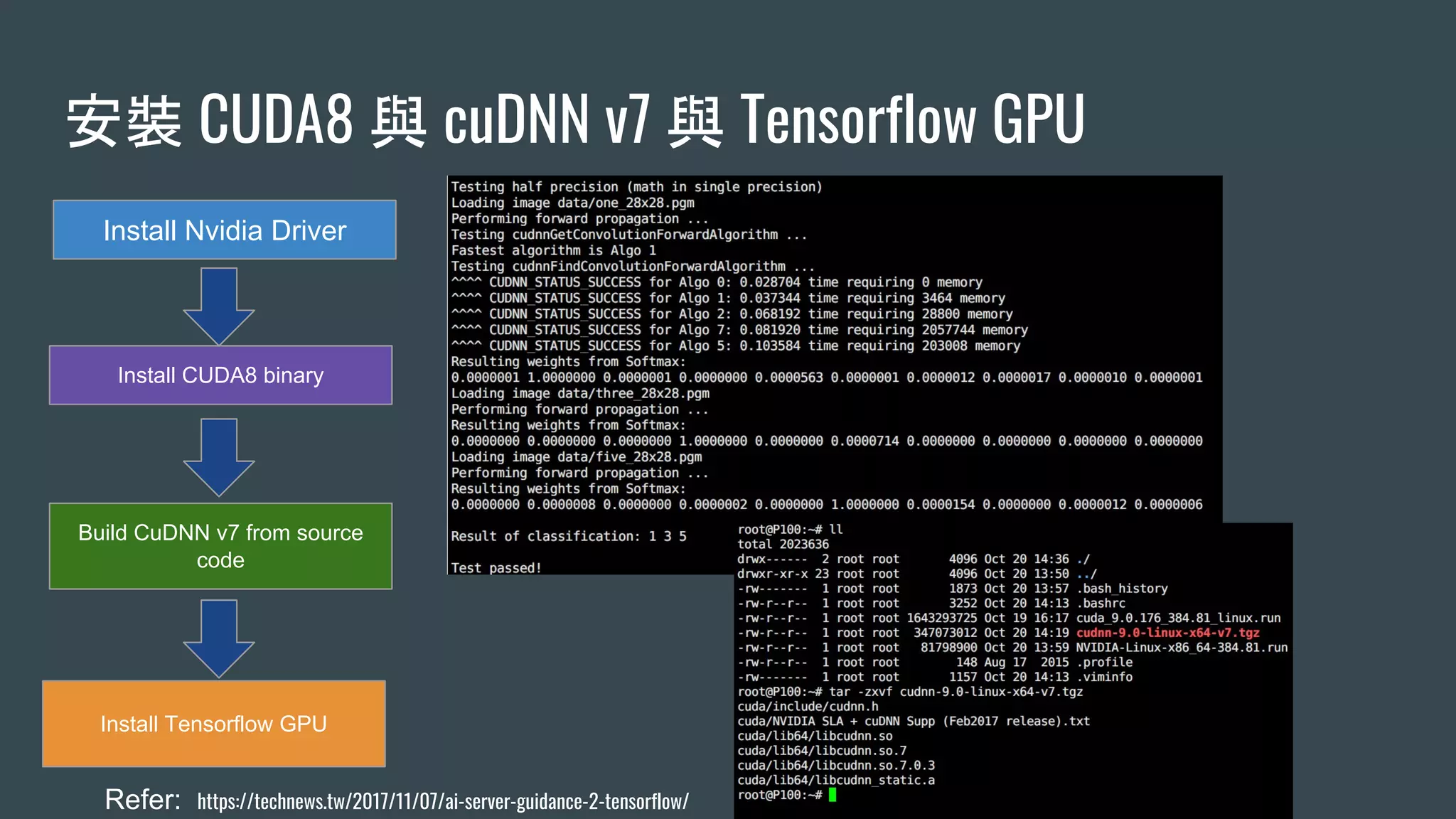
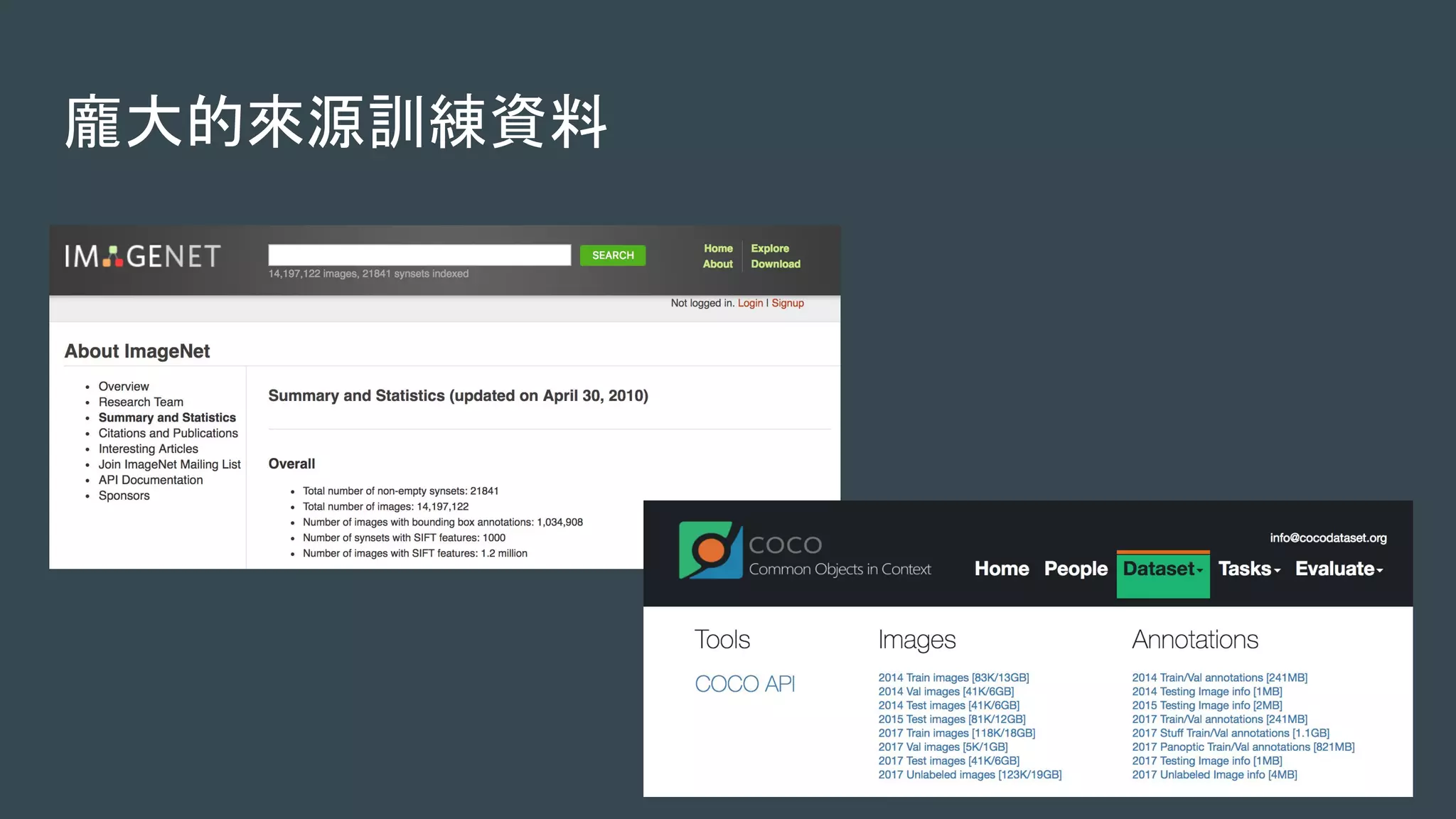
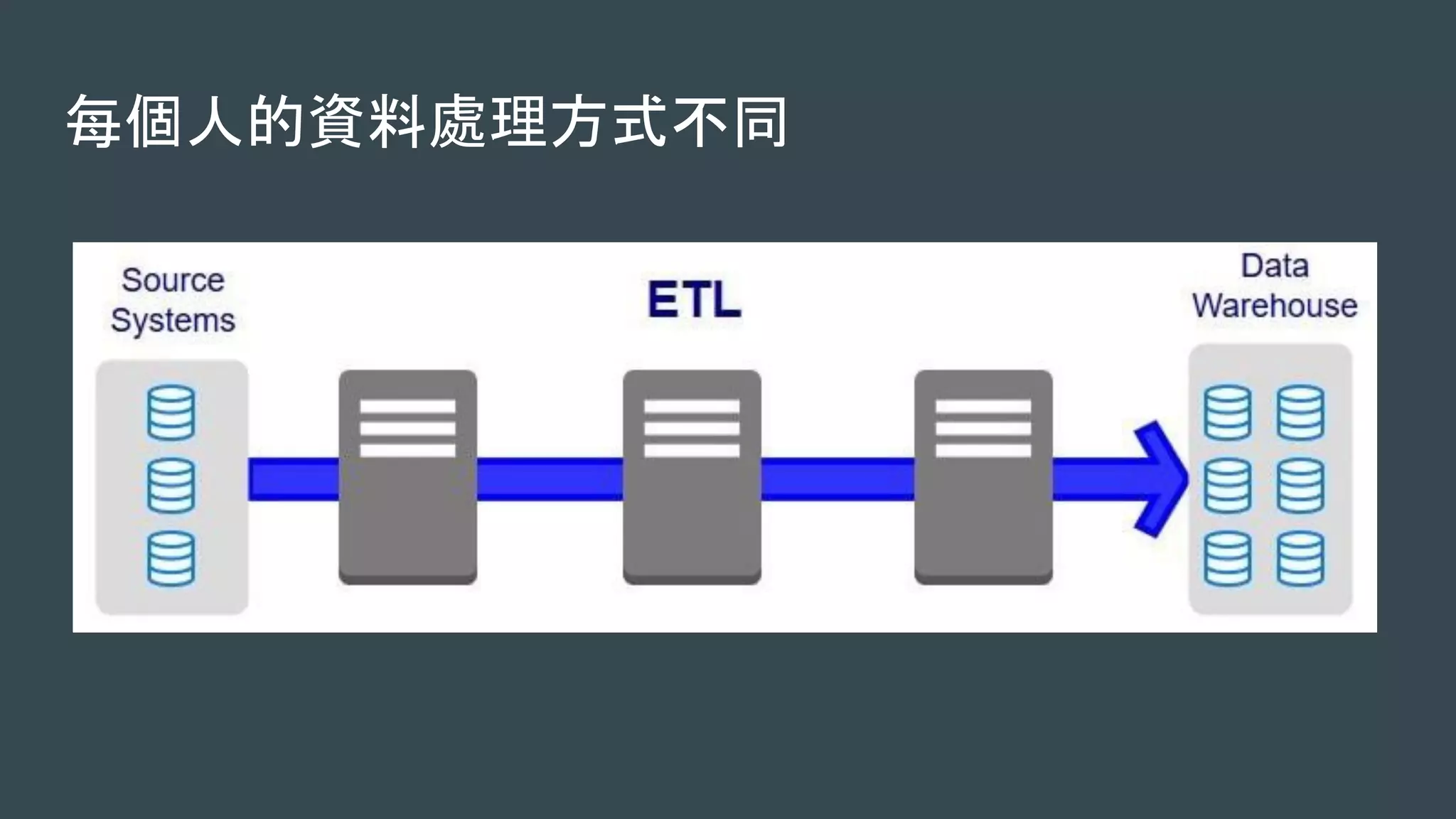
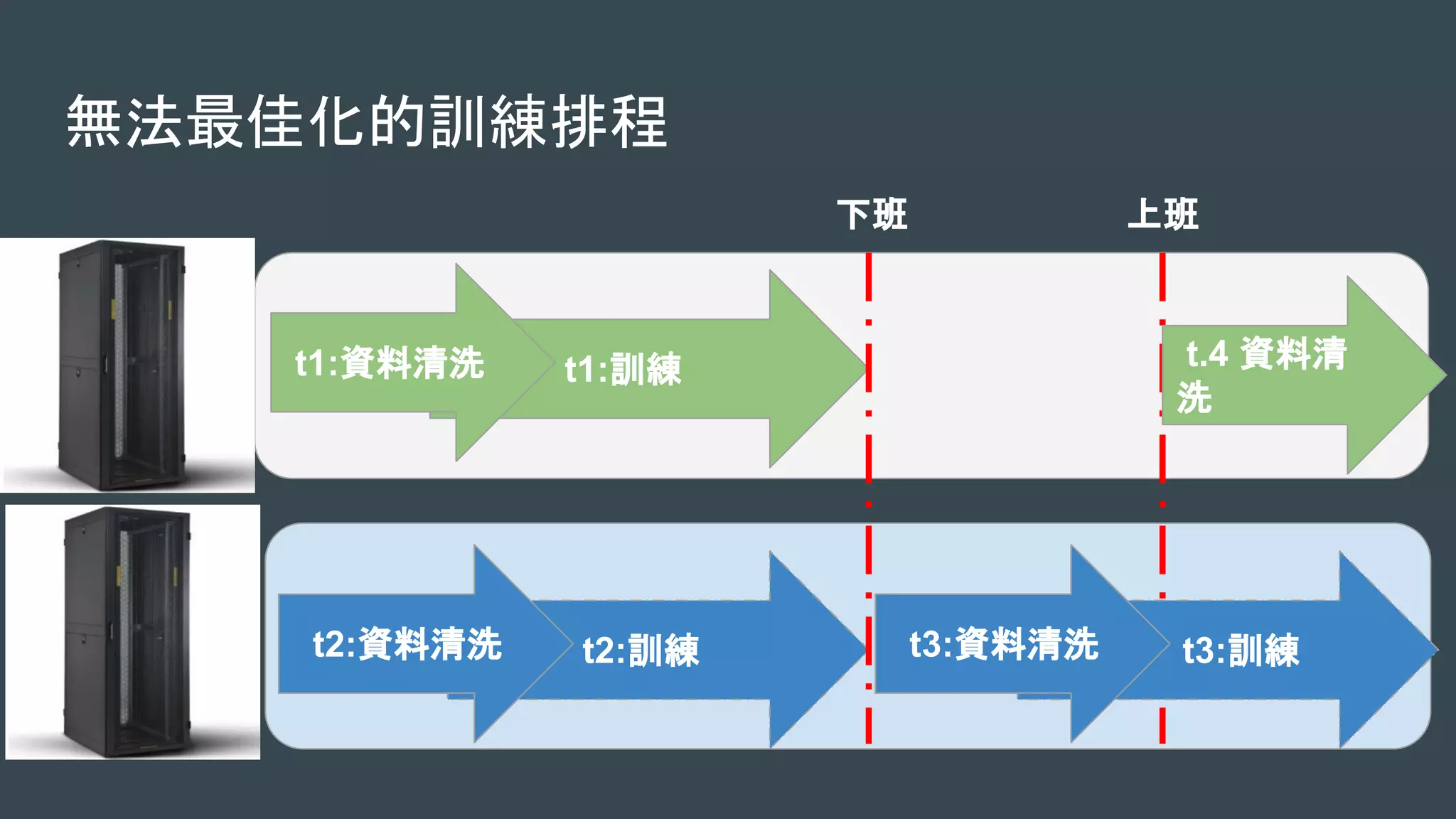
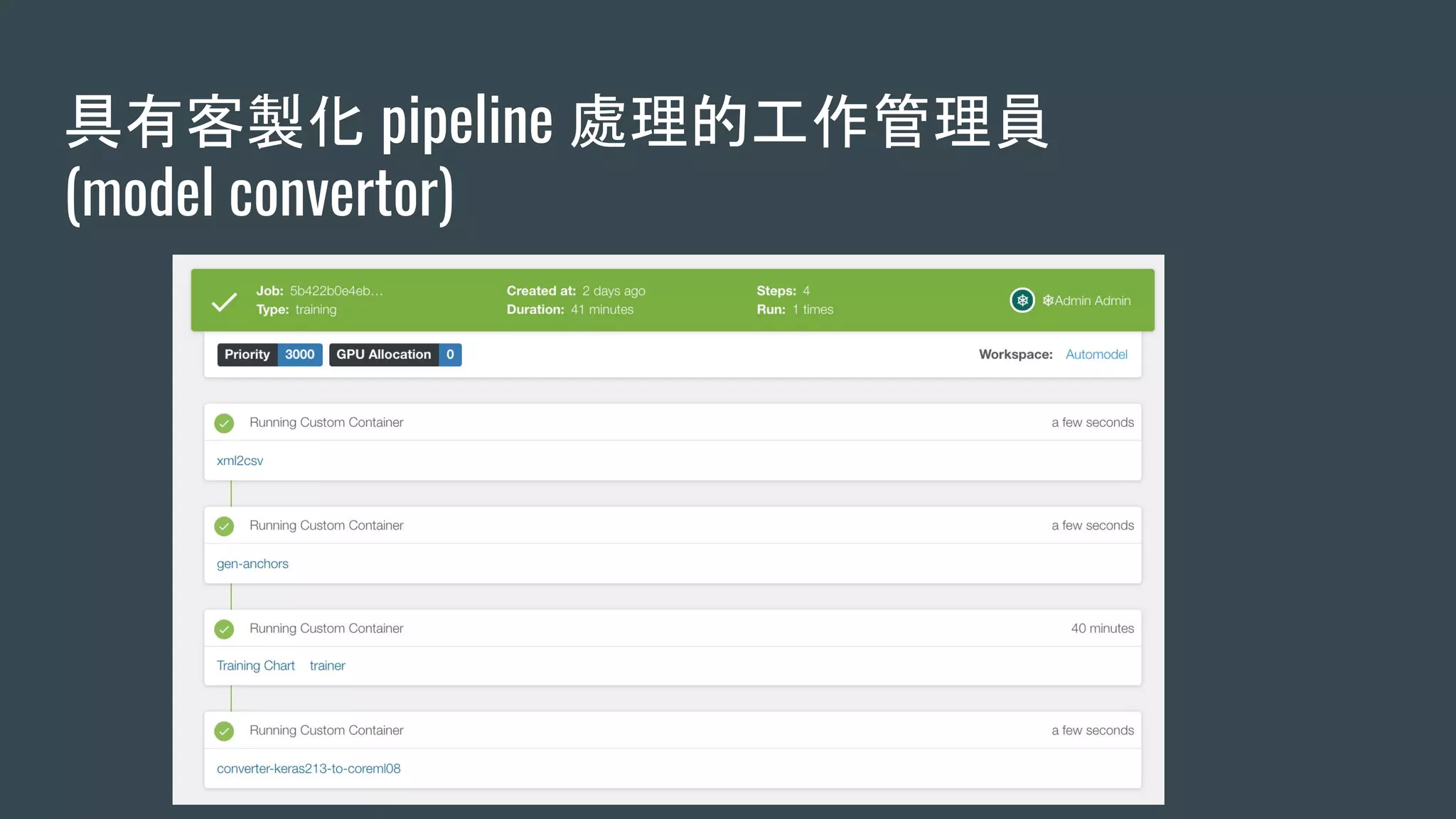
本文探讨了构建高效机器学习平台的重要性与挑战,包括环境安装、训练数据同步、训练调度优化及数据预处理等问题。使用Kubernetes可以简化资源管理与调度,从而提升整体性能。最后强调机器学习平台将成为下一个关键应用。






























































![[台灣人工智慧學校] 台北總校第三期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/opening1-180929011045-thumbnail.jpg?width=640&height=640&fit=bounds)






![[台灣人工智慧學校] 新竹分校第一期開學典禮](https://cdn.slidesharecdn.com/ss_thumbnails/aiahc-opening-180720120102-thumbnail.jpg?width=640&height=640&fit=bounds)





















