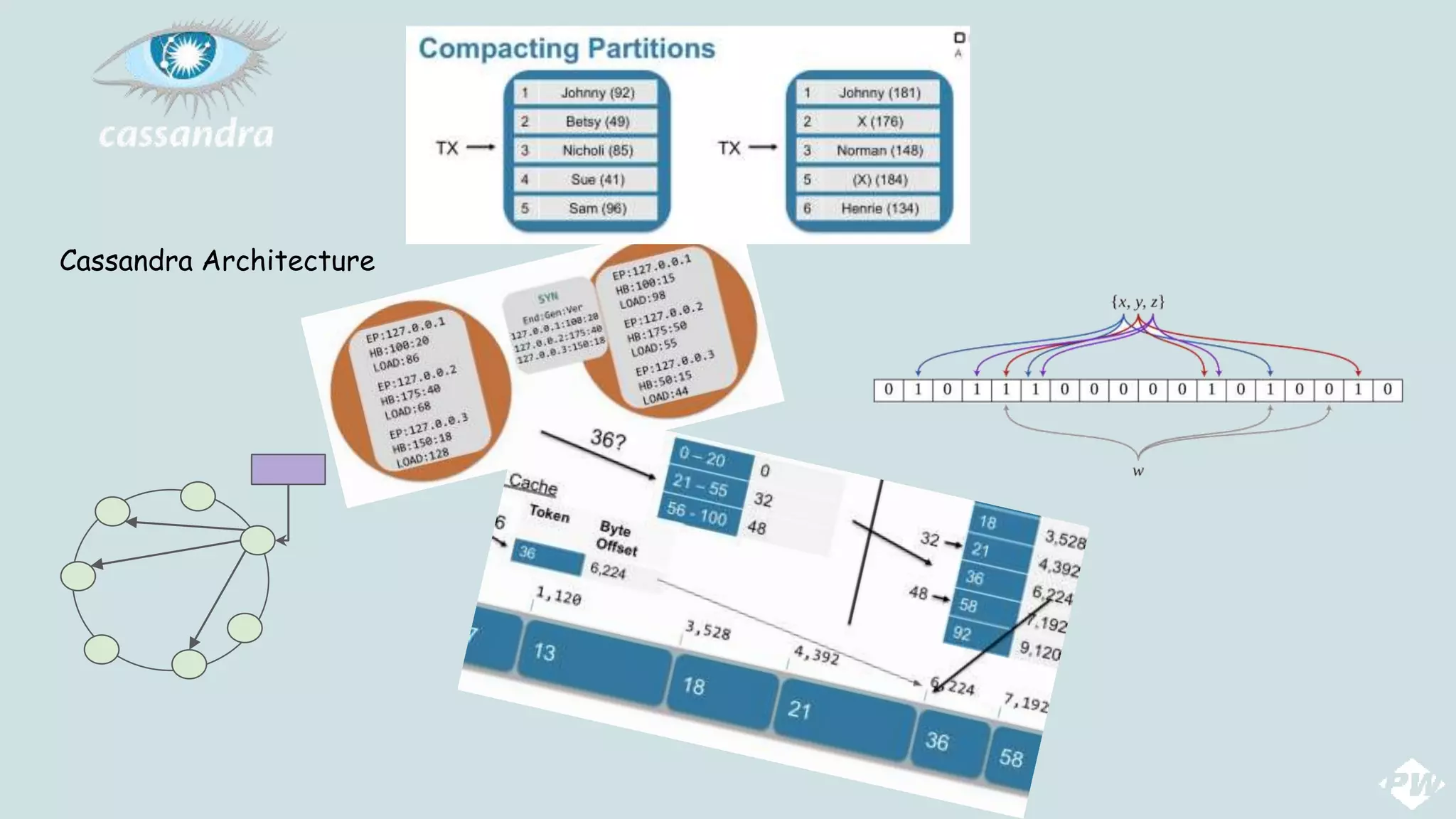
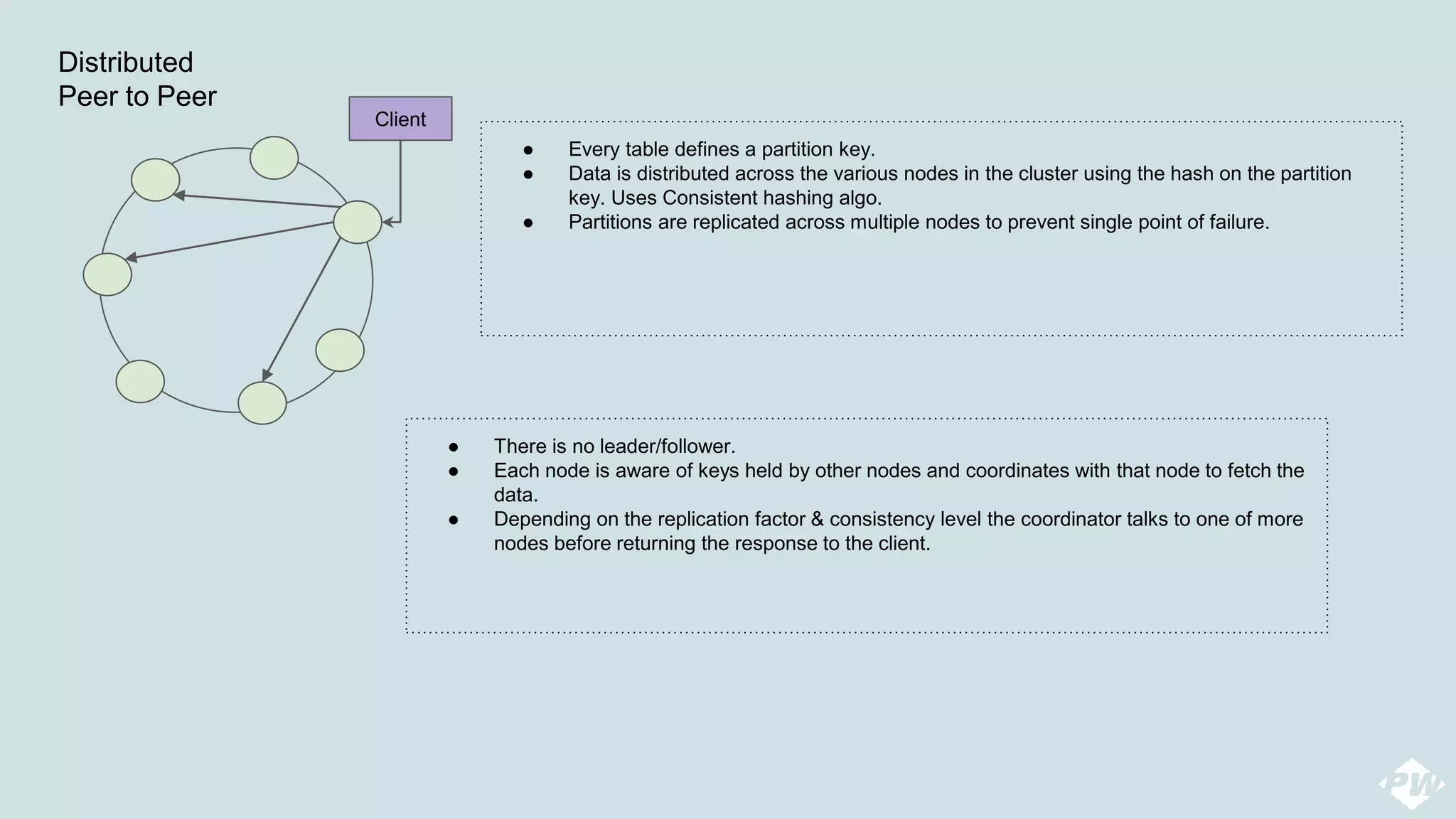
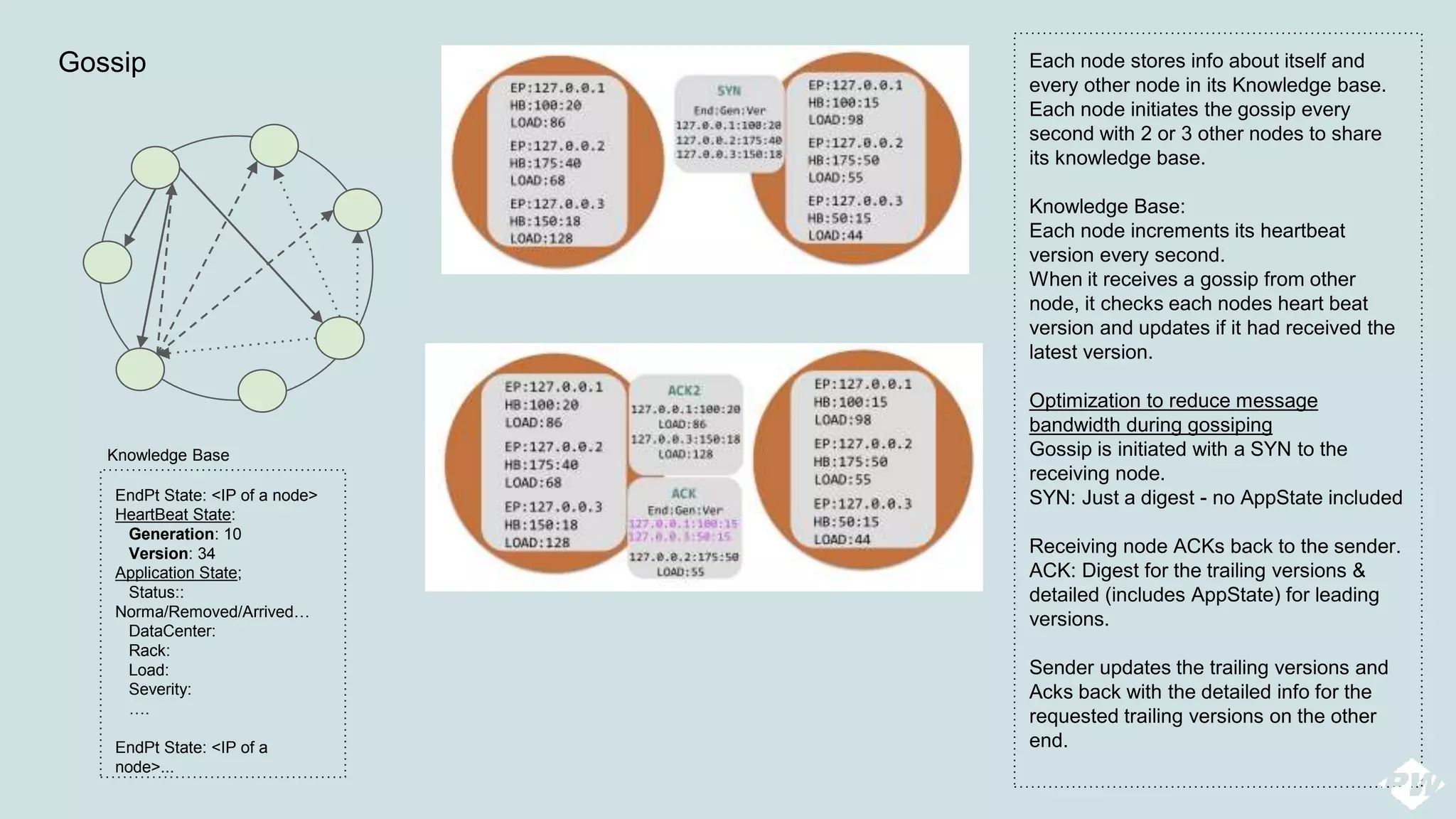
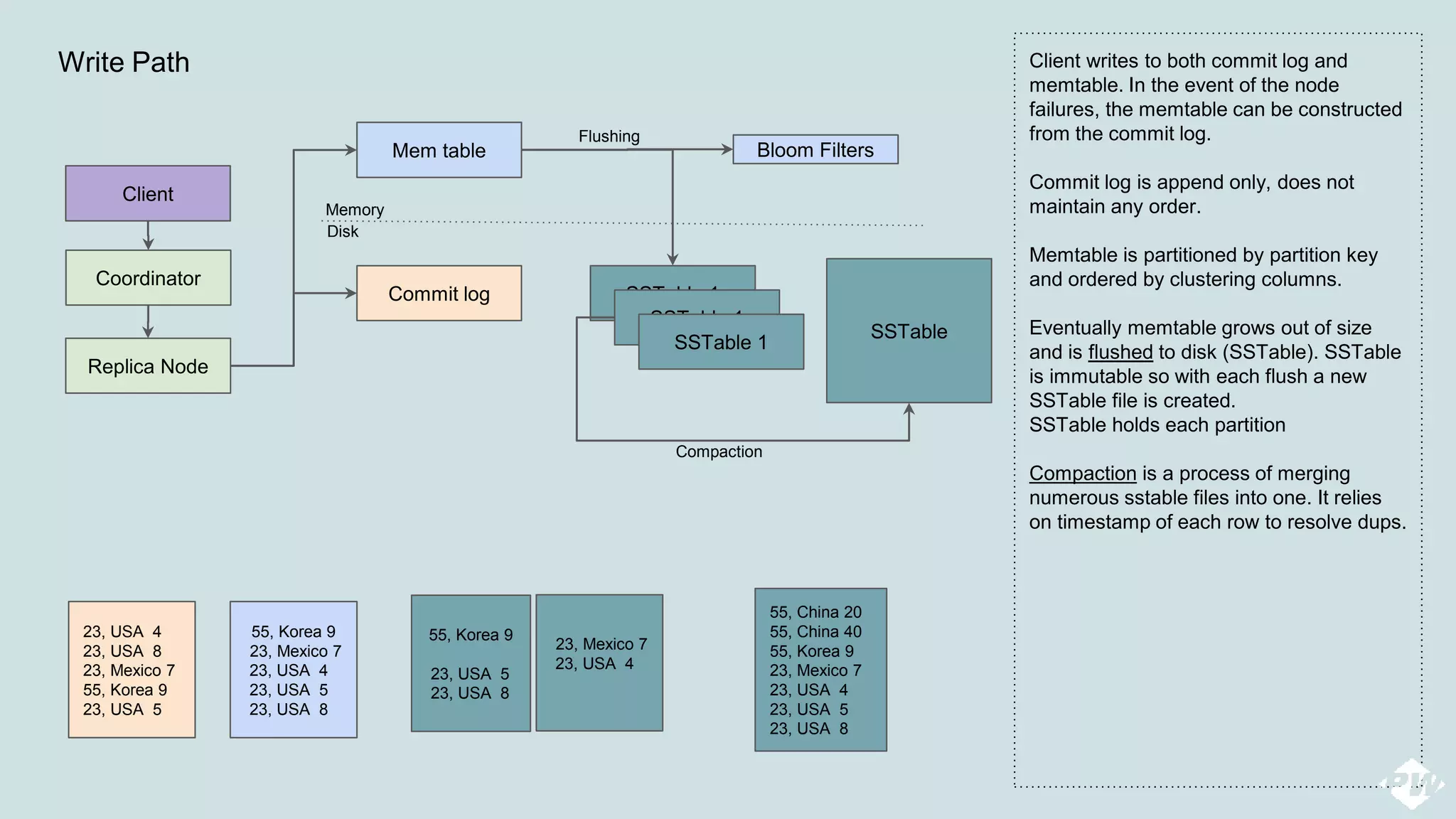
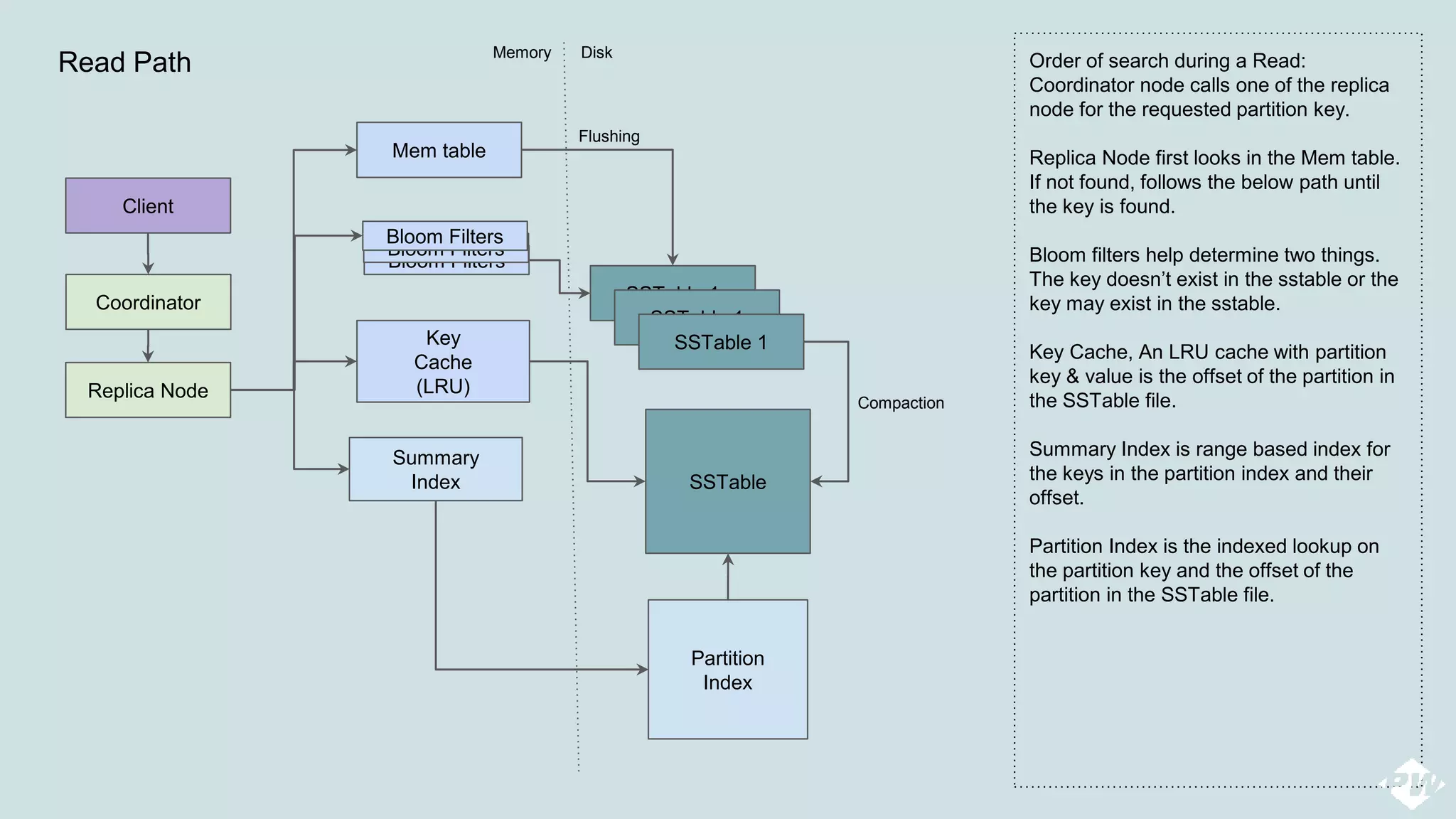
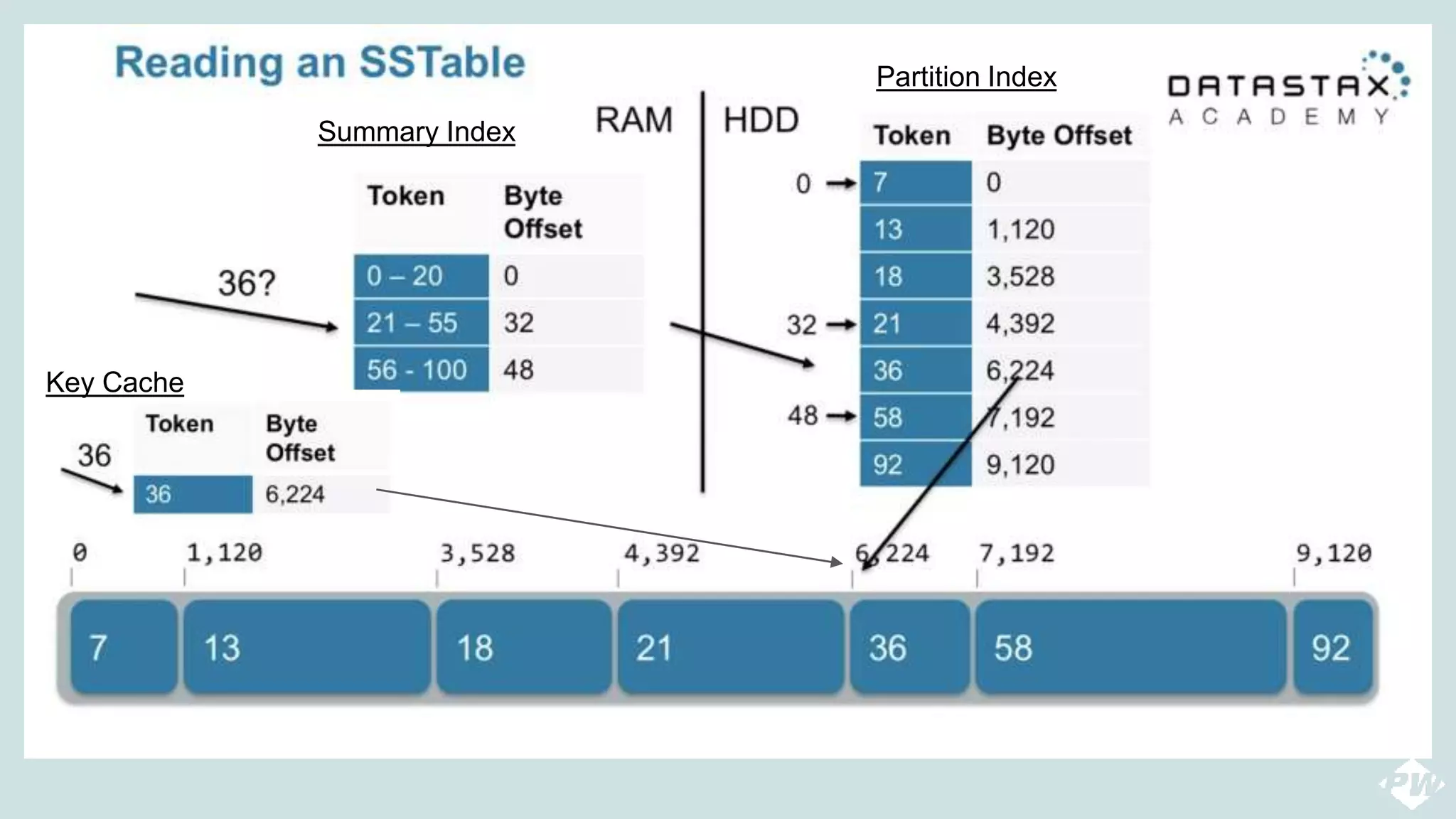
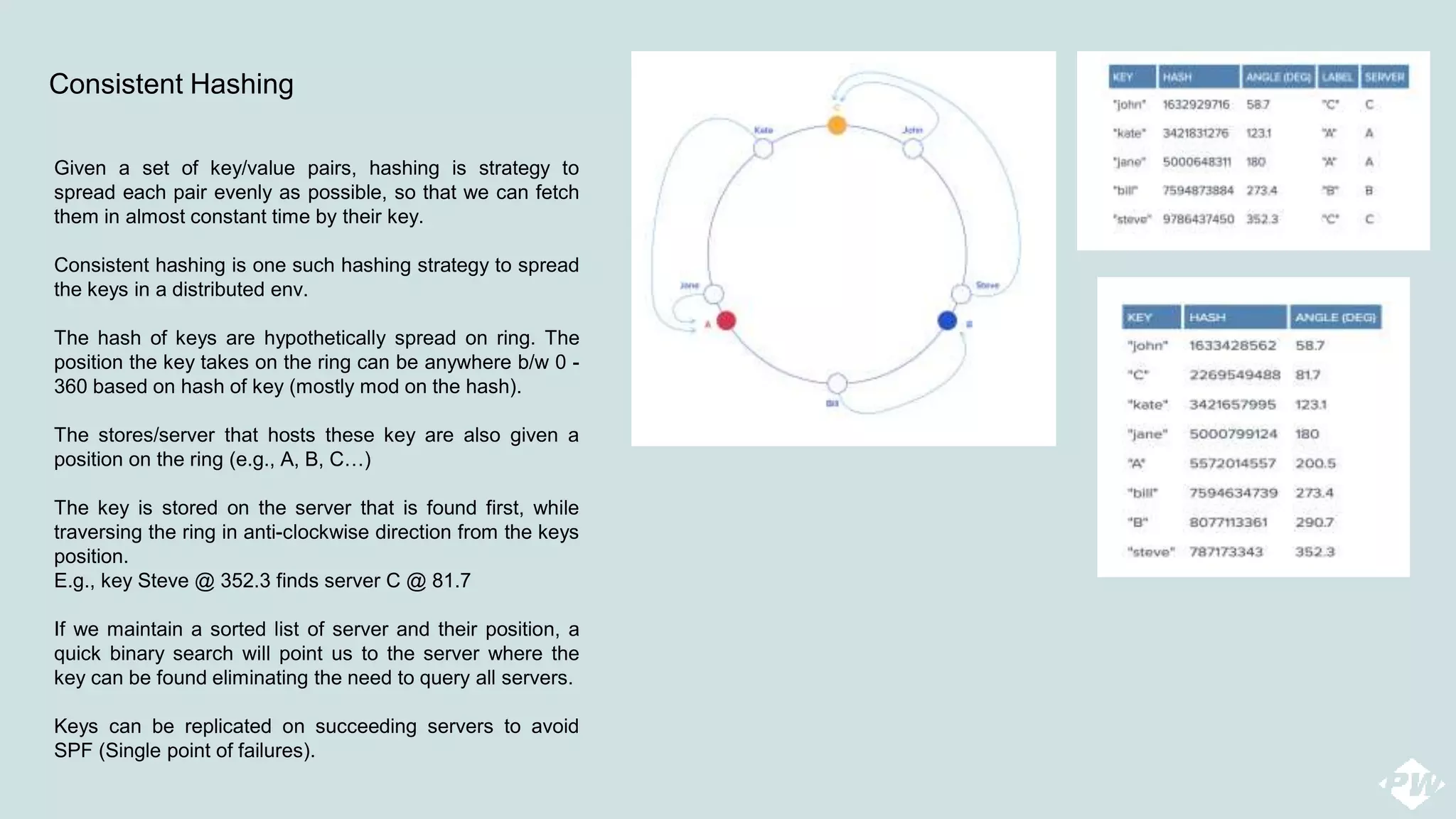
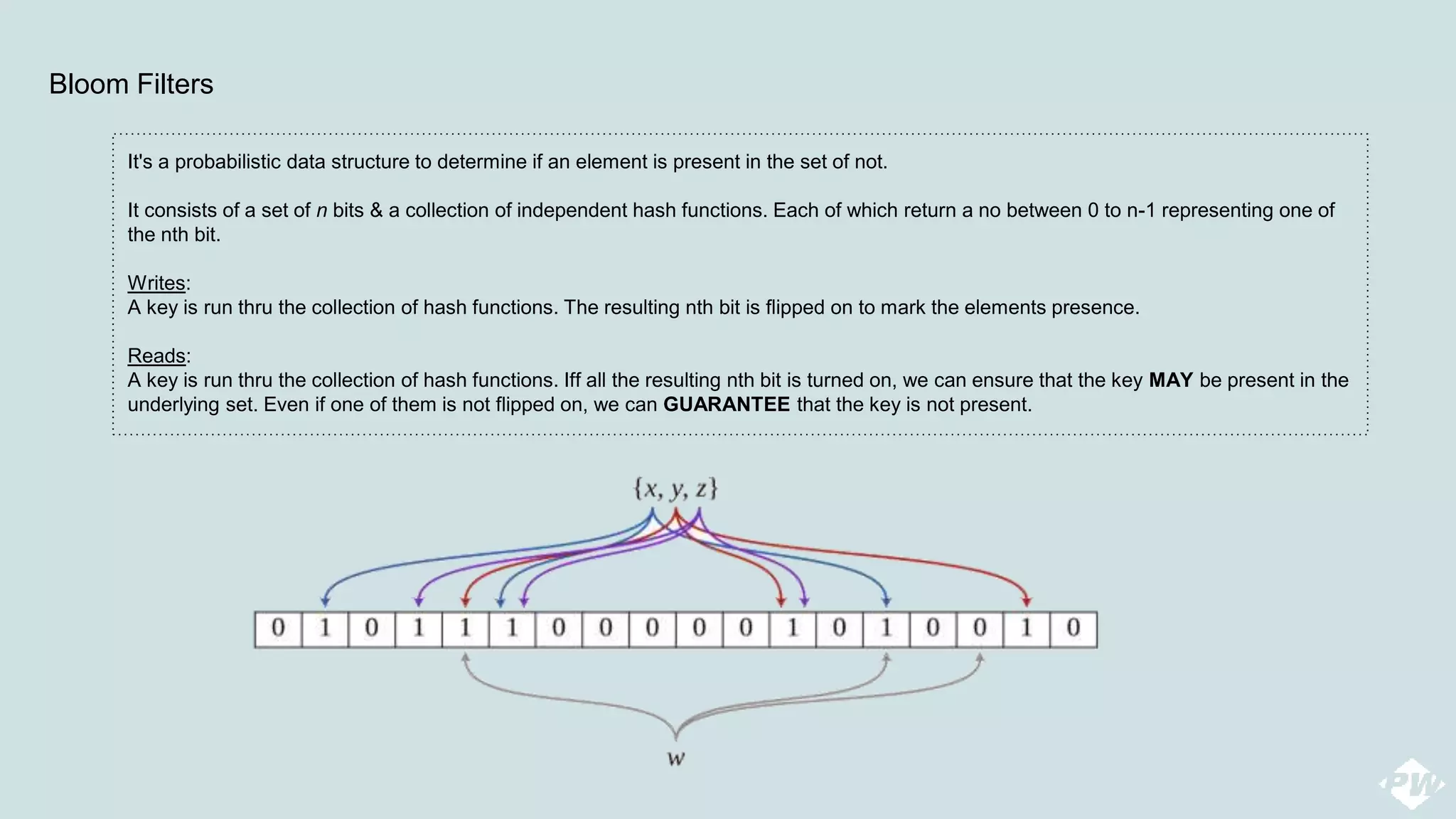
This document provides an overview of a distributed peer-to-peer database system, detailing its architecture, data storage, and retrieval mechanisms. It emphasizes key concepts such as consistent hashing, replication, and gossip protocols for node communication, as well as the importance of data consistency and availability. Additionally, it describes the inner workings of functions like read repairs, commit logs, memtables, and bloom filters for efficient data management.