Downloaded 15 times











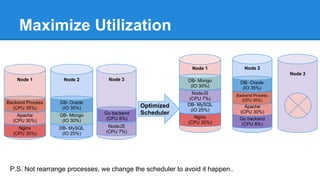
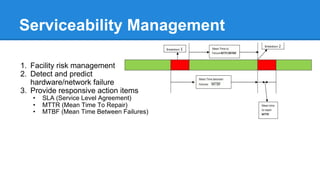
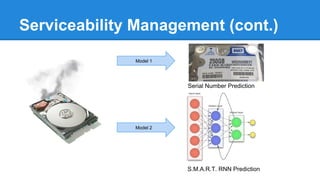

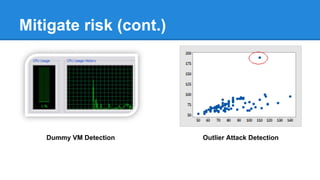

![Operation Optimization
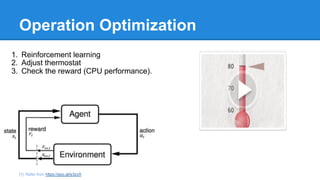
1. Reinforcement learning
2. Adjust thermostat
3. Check the reward (CPU performance).
[1]: Refer from https://goo.gl/ly3zyX](https://image.slidesharecdn.com/ithomecloudsummit2017-170621073755/85/iThome-Cloud-Summit-The-next-generation-of-data-center-Machine-Intelligent-Cluster-26-320.jpg)
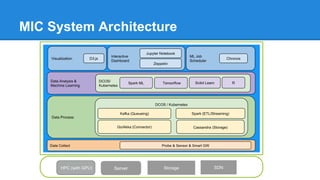
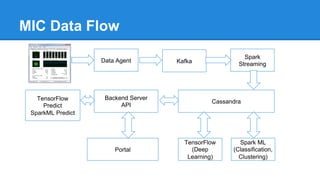
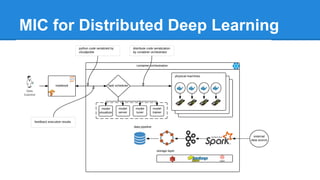




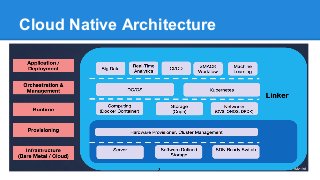
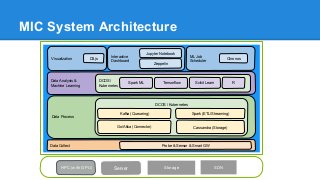
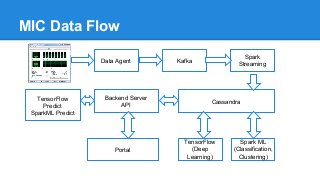
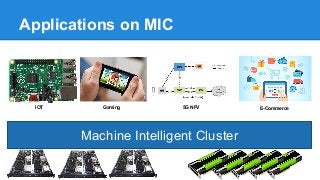




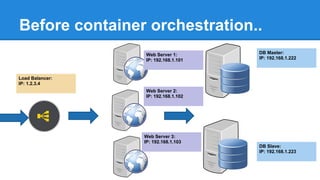
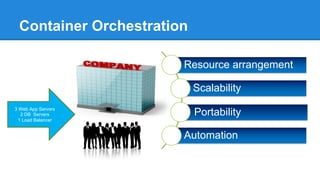
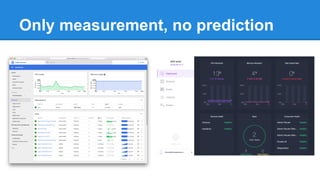
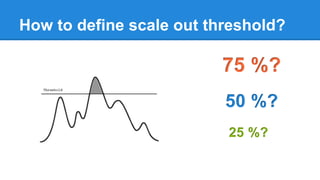
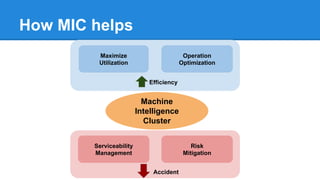
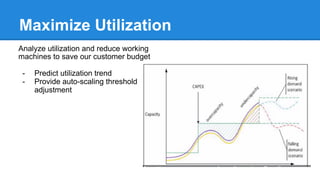
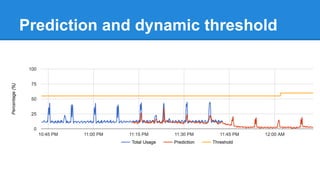
The document discusses the concept of a Machine Intelligent Cluster in data centers, focusing on leveraging machine learning to optimize power consumption, resource management, and operation efficiency. It explains the architecture and functionalities such as self-optimization, self-learning, and self-recovery. The applications include IoT, gaming, and e-commerce, highlighting the need for predictive capabilities in modern data environments.










































































