Downloaded 23 times







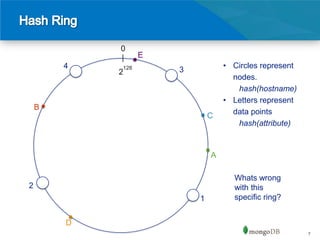
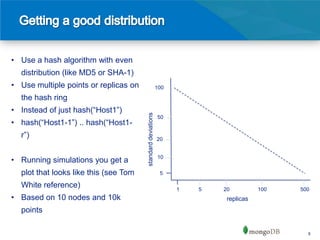
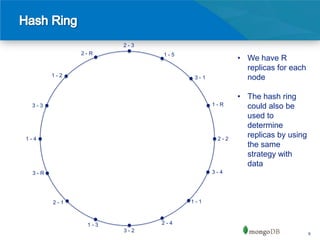


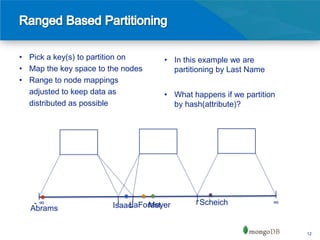



The document discusses data distribution theories for high-performance databases, focusing on techniques for distributing data across machines in a reliable network. It highlights the limitations of traditional relational databases for distributed computing and introduces methods such as consistent hashing and sharding as effective ways to distribute data while balancing load and improving read/write efficiency. Key considerations include choosing appropriate shard keys and understanding the implications of data locality and load balancing.







































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















