Downloaded 46 times






![xperf –on base –stackwalk profile
SELECT p.EnglishProductName
,SUM([OrderQuantity])
,SUM([UnitPrice])
,SUM([ExtendedAmount])
,SUM([UnitPriceDiscountPct])
,SUM([DiscountAmount])
,SUM([ProductStandardCost])
,SUM([TotalProductCost])
,SUM([SalesAmount])
,SUM([TaxAmt])
,SUM([Freight])
FROM [dbo].[FactInternetSales] f
JOIN [dbo].[DimProduct] p
ON
f.ProductKey = p.ProductKey
GOUP BY p.EnglishProductName
xperfview stackwalk.etl
xperf –d stackwalk.etl](https://image.slidesharecdn.com/columnstoreindexesandbatchprocessingmodenxpowerlite-140208133232-phpapp01/85/Column-store-indexes-and-batch-processing-mode-nx-power-lite-11-320.jpg)

![SELECT p.EnglishProductName
,SUM([OrderQuantity])
,SUM([UnitPrice])
,SUM([ExtendedAmount])
,SUM([UnitPriceDiscountPct])
,SUM([DiscountAmount])
,SUM([ProductStandardCost])
,SUM([TotalProductCost])
,SUM([SalesAmount])
,SUM([TaxAmt])
,SUM([Freight])
FROM [dbo].[FactInternetSalesFio] f
JOIN [dbo].[DimProduct] p
ON
f.ProductKey = p.ProductKey
GROUP BY p.EnglishProductName
x12
Batch
at
DOP 2
Row mode
Batch
Row mode
0
100
200
300
400
500](https://image.slidesharecdn.com/columnstoreindexesandbatchprocessingmodenxpowerlite-140208133232-phpapp01/85/Column-store-indexes-and-batch-processing-mode-nx-power-lite-14-320.jpg)
![SELECT
[ProductKey]
,[OrderDateKey]
,[DueDateKey]
,[ShipDateKey]
,[CustomerKey]
,[PromotionKey]
,[CurrencyKey]
.
.
INTO
FactInternetSalesBig
FROM
[dbo].[FactInternetSales]
CROSS JOIN master..spt_values AS a
CROSS JOIN master..spt_values AS b
WHERE
a.type
= 'p'
AND
b.type
= 'p'
AND
a.number <= 80
AND
b.number <= 100
494,116,038 rows
Size
(Mb)
80,000
70,000
60,000
57 %
50,000
74 %
92 %
94 %
40,000
30,000
20,000
10,000
0
Heap
Row compression
Page compression
Clustered column Column store archive compression
store index](https://image.slidesharecdn.com/columnstoreindexesandbatchprocessingmodenxpowerlite-140208133232-phpapp01/85/Column-store-indexes-and-batch-processing-mode-nx-power-lite-19-320.jpg)


![Compression Type / Time (ms)
300000
Time (ms)
SELECT SUM([OrderQuantity])
,SUM([UnitPrice])
,SUM([ExtendedAmount])
,SUM([UnitPriceDiscountPct])
,SUM([DiscountAmount])
,SUM([ProductStandardCost])
,SUM([TotalProductCost])
,SUM([SalesAmount])
,SUM([TaxAmt])
,SUM([Freight])
FROM [dbo].[FactInternetSales]
250000
200000
150000
100000
2050Mb/s
85% CPU
50000
678Mb/s
98% CPU
256Mb/s
98% CPU
0
No compression
Row
compression
Page
No compression
Row
compression
compression
Page
compression](https://image.slidesharecdn.com/columnstoreindexesandbatchprocessingmodenxpowerlite-140208133232-phpapp01/85/Column-store-indexes-and-batch-processing-mode-nx-power-lite-24-320.jpg)

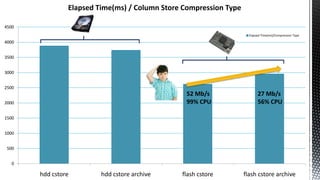
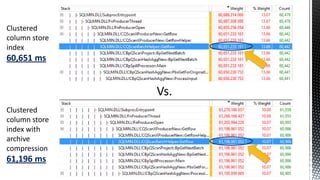
![We will look at the best we can
do without column store indexes:
Partitioned heap fact table with page
compression for spinning disk
Partitioned heap fact table without
any compression our flash storage
Non partitioned column store indexes
on both types of store with and without
archive compression.
SELECT p.EnglishProductName
,SUM([OrderQuantity])
,SUM([UnitPrice])
,SUM([ExtendedAmount])
,SUM([UnitPriceDiscountPct])
,SUM([DiscountAmount])
,SUM([ProductStandardCost])
,SUM([TotalProductCost])
,SUM([SalesAmount])
,SUM([TaxAmt])
,SUM([Freight])
FROM [dbo].[FactInternetSales] f
JOIN [dbo].[DimProduct] p
ON
f.ProductKey = p.ProductKey
GROUP BY p.EnglishProductName](https://image.slidesharecdn.com/columnstoreindexesandbatchprocessingmodenxpowerlite-140208133232-phpapp01/85/Column-store-indexes-and-batch-processing-mode-nx-power-lite-28-320.jpg)
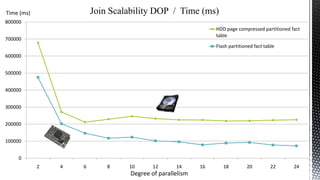
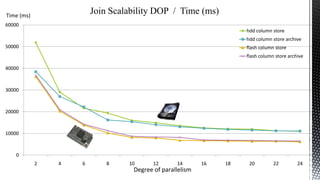


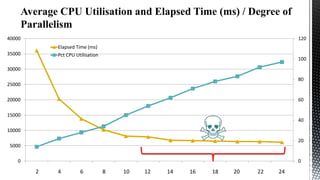
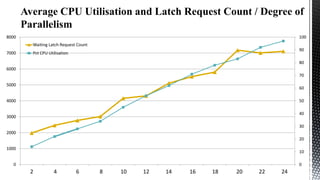
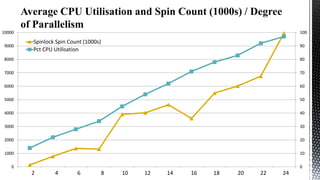








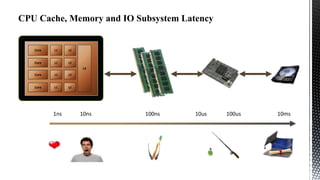
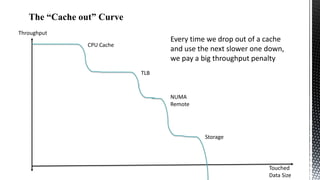
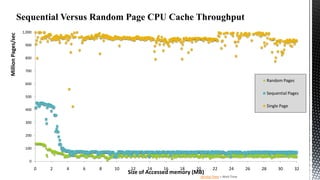
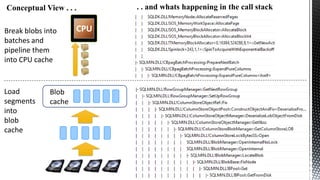
This document discusses SQL Server performance tuning with a focus on leveraging CPU caches through column store compression. It explains how column store compression can bridge the performance gap between IO subsystems and modern processors by breaking data through levels of compression to pipeline batches into CPU caches. Examples are provided showing significant performance improvements from column store compression and clustering over row-based storage and no compression.
























































































