This document discusses several performance improvements made in PostgreSQL versions 9.5 and beyond. Some key improvements discussed include:
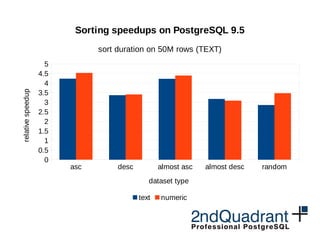
- Faster sorting through allowing sorting by inlined functions, abbreviated keys for VARCHAR/TEXT/NUMERIC, and Sort Support benefits.
- Improved hash joins through reduced palloc overhead, smaller NTUP_PER_BUCKET, and dynamically resizing the hash table.
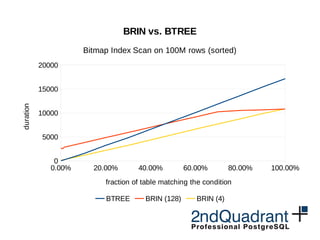
- Index improvements like avoiding index tuple copying, GiST and bitmap index scan optimizations, and block range tracking in BRIN indexes.
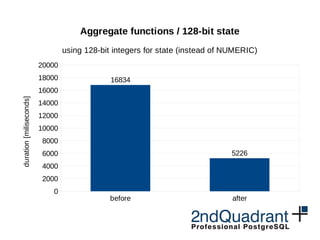
- Aggregate functions see speedups through using 128-bit integers for internal state instead of NUMERIC in some cases.
- Other optimizations affect PL/pgSQL performance,








![asc desc almost asc almost desc random
0
50
100
150
200
250
300
350
400
450
500
Sorting improvements in PostgreSQL 9.5
sort duration on 50M rows (TEXT)
PostgreSQL 9.4 PostgreSQL 9.5
dataset type
duration[seconds]](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-8-320.jpg)
![asc desc almost asc almost desc random
0
50
100
150
200
250
300
350
Sorting improvements in PostgreSQL 9.5
sort duration on 50M rows (TEXT)
PostgreSQL 9.4 PostgreSQL 9.5
dataset type
duration[seconds]](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-9-320.jpg)


![0 500000 1000000 1500000 2000000
0
10000
20000
30000
40000
50000
PostgreSQL 9.5 Hash Join Improvements
join duration - 50M rows (outer), different NTUP_PER_BUCKET
NTUP_PER_BUCKET=10 NTUP_PER_BUCKET=1
hash size (number of tuples)
duration[miliseconds]](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-13-320.jpg)
![0 500000 1000000 1500000 2000000
0
10000
20000
30000
40000
50000
PostgreSQL 9.5 Hash Join Improvements
join duration - 50M rows (outer), different NTUP_PER_BUCKET
NTUP_PER_BUCKET=10 NTUP_PER_BUCKET=1
PostgreSQL 9.5
hash size (number of inner tuples)
duration[miliseconds]](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-14-320.jpg)

![query 1 query 2
0
500
1000
1500
2000
2500
3000
Bitmap build speedup
cache last page in tbm_add_tuples()
before after
duration[miliseconds]](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-17-320.jpg)




![before after
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
16834
5226
Aggregate functions / 128-bit state
using 128-bit integers for state (instead of NUMERIC)
duration[miliseconds]](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-23-320.jpg)




![0 1 2 3 4 5
0
20
40
60
80
100
120
140
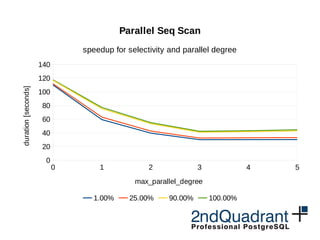
Parallel Seq Scan
speedup for selectivity and parallel degree (100M rows)
1.00% 25.00% 90.00% 100.00%
max_parallel_degree
duration[seconds]](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-30-320.jpg)
![TABLESAMPLE
SELECT * FROM t TABLESAMPLE sampling_method (args)
[REPEATABLE (seed)]
SELECT * FROM t TABLESAMPLE BERNOULLI (33.3);
SELECT * FROM t TABLESAMPLE SYSTEM (33.3);
-- tsm_system_rows
SELECT * FROM t TABLESAMPLE SYSTEM_ROWS (1000);
-- tsm_system_time
SELECT * FROM t TABLESAMPLE SYSTEM_TIME (1000);](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-31-320.jpg)
![0 10 20 30 40 50 60 70 80 90 100
0
5000
10000
15000
20000
25000
30000
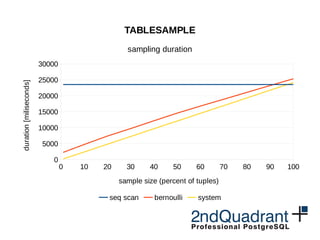
TABLESAMPLE
sampling duration
seq scan bernoulli system
sample size (percent of tuples)
duration[miliseconds]](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-32-320.jpg)


![BIGINT NUMERIC
0
2000
4000
6000
8000
10000
12000
14000
5438
12858
4056
8103
Aggregate functions
sharing aggregate state
before after
duration[miliseconds]](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-35-320.jpg)




![Additional 9.6+ changes
● Declarative partitioning
– easier maintenance (huge improvement)
– allows advanced planning (insight into partitioning rules)
● Sorting
– Reusing abbreviated keys during second pass of ordered [set]
aggregates
– SortSupport for text - strcoll() and strxfrm() caching
– Memory prefetching while sequentially fetching from SortTuple
array, tuplestore
– Using quicksort and a merge step to significantly improve on
tuplesort's single run "external sort"](https://image.slidesharecdn.com/performance-in-9-151027183613-lva1-app6892/85/Performance-improvements-in-PostgreSQL-9-5-and-beyond-40-320.jpg)






![Introduction to MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-191005204425-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PGDay.Seoul 2020] PostgreSQL 13 New Features](https://cdn.slidesharecdn.com/ss_thumbnails/2020pgdayseoulpostgresql13newfeatures-201116014501-thumbnail.jpg?width=640&height=640&fit=bounds)

![Introduction into MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-210717011329-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Pgday.Seoul 2019] Citus를 이용한 분산 데이터베이스](https://cdn.slidesharecdn.com/ss_thumbnails/citus20191207studypgday-191218045308-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)












