Download as PDF, PPTX














![20
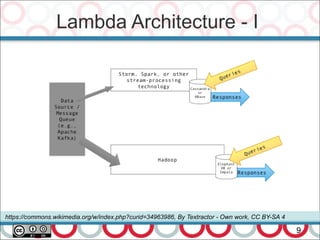
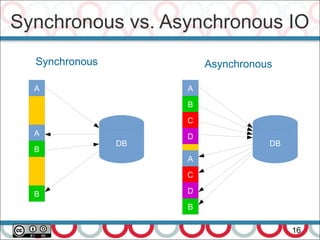
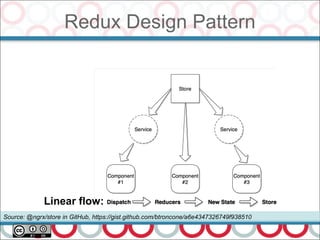
Performance is about 2 things (Martin Thompson –
http://www.infoq.com/articles/low-latency-vp ):
– Throughput – units per second, and
– Latency – response time
Real-time – time constraint from input to response
regardless of system load.
Hard real-time system if this constraint is not honored then
a total system failure can occur.
Soft real-time system – low latency response with little
deviation in response time
100 nano-seconds to 100 milli-seconds. [Peter Lawrey]
What's High Performance?](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-20-320.jpg)


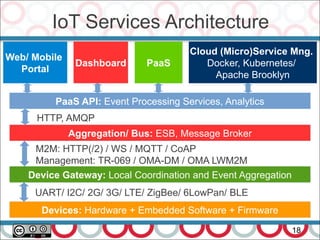
![23
Queues typically use either linked-lists or arrays for the
underlying storage of elements. Linked lists are not
„mechanically sympathetic” – there is no predictable
caching “stride” (should be less than 2048 bytes in each
direction).
Bounded queues often experience write contention on
head, tail, and size variables. Even if head and tail
separated using CAS, they usually are in the same cache-
line.
Queues produce much garbage.
Typical queues conflate a number of different concerns –
producer and consumer synchronization and data storage
Blocking Queues Disadvantages
[http://lmax-exchange.github.com/disruptor/files/Disruptor-1.0.pdf]](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-23-320.jpg)
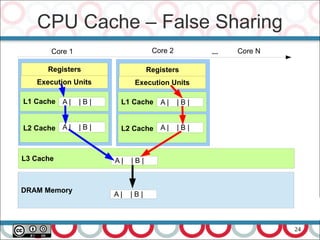

![Domain Driven Design
26
Main concepts:
Entities, value objects and modules
Aggregates and Aggregate Roots [Haywood]:
value < entity < aggregate < module < BC
Aggregate Roots are exposed as Open Host Services
Repositories, Factories and Services:
application services <-> domain services
Separating interface from implementation](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-26-320.jpg)
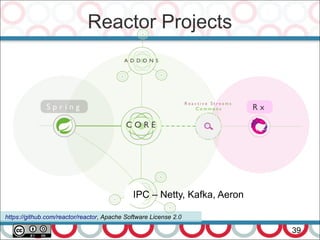
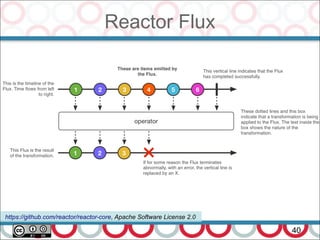
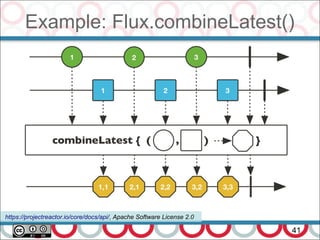
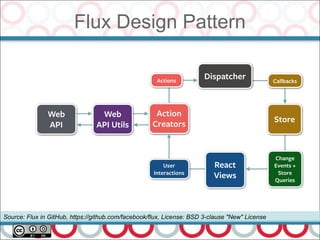
![Microservices and DDD
27
Actually DDD require additional efforts (as most other
divide and concur modeling approaches :)
Ubiquitous language and Bounded Contexts
DDD Application Layers:
Infrastructure, Domain, Application, Presentation
Hexagonal architecture :
OUTSIDE <-> transformer <->
( application <-> domain )
[A. Cockburn]](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-27-320.jpg)



![Reactive Manifesto
31
[http://www.reactivemanifesto.org]](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-31-320.jpg)
![32
Message Driven – asynchronous message-passing allows
to establish a boundary between components that ensures
loose coupling, isolation, location transparency, and
provides the means to delegate errors as messages
[Reactive Manifesto].
The main idea is to separate concurrent producer and
consumer workers by using message queues.
Message queues can be unbounded or bounded (limited
max number of messages)
Unbounded message queues can present memory
allocation problem in case the producers outrun the
consumers for a long period → OutOfMemoryError
Scalable, Massively Concurrent](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-32-320.jpg)
![Reactive Programming
33
Microsoft®
opens source polyglot project ReactiveX
(Reactive Extensions) [http://reactivex.io]:
Rx = Observables + LINQ + Schedulers :)
Java: RxJava, JavaScript: RxJS, C#: Rx.NET, Scala: RxScala,
Clojure: RxClojure, C++: RxCpp, Ruby: Rx.rb, Python: RxPY,
Groovy: RxGroovy, JRuby: RxJRuby, Kotlin: RxKotlin ...
Reactive Streams Specification
[http://www.reactive-streams.org/] used by:
(Spring) Project Reactor [http://projectreactor.io/]
Actor Model – Akka (Java, Scala) [http://akka.io/]](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-33-320.jpg)
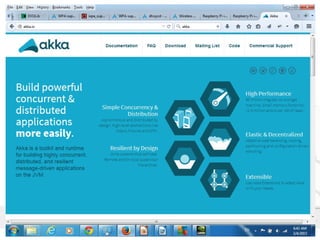


![FRP = Async Data Streams
37
FRP is asynchronous data-flow programming using the
building blocks of functional programming (e.g. map,
reduce, filter) and explicitly modeling time
Used for GUIs, robotics, and music. Example (RxJava):
Observable.from(
new String[]{"Reactive", "Extensions", "Java"})
.take(2).map(s -> s + " : on " + new Date())
.subscribe(s -> System.out.println(s));
Result:
Reactive : on Wed Jun 17 21:54:02 GMT+02:00 2015
Extensions : on Wed Jun 17 21:54:02 GMT+02:00 2015](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-37-320.jpg)

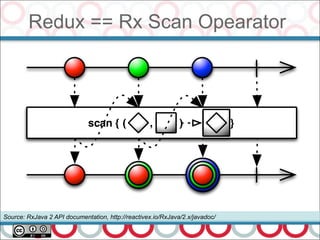




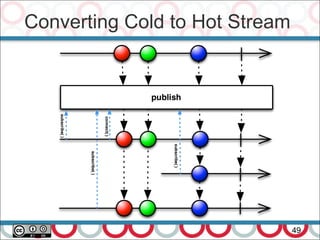



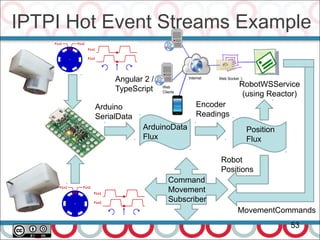




![CompletableFuture Example - II
58
ExecutorService executor = ForkJoinPool.commonPool();
//ExecutorService executor = Executors.newCachedThreadPool();
public void testlCompletableFutureSequence() {
List<CompletableFuture<String>> futuresList =
IntStream.range(0, 20).boxed()
.map(i -> longCompletableFutureTask(i, executor)
.exceptionally(t -> t.getMessage()))
.collect(Collectors.toList());
CompletableFuture<List<String>> results =
CompletableFuture.allOf(
futuresList.toArray(new CompletableFuture[0]))
.thenApply(v -> futuresList.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList())
);](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-58-320.jpg)



![New in Java 9: CompletableFuture
62
Executor defaultExecutor()
CompletableFuture<U> newIncompleteFuture()
CompletableFuture<T> copy()
CompletionStage<T> minimalCompletionStage()
CompletableFuture<T> completeAsync(
Supplier<? extends T> supplier[, Executor executor])
CompletableFuture<T> orTimeout(
long timeout, TimeUnit unit)
CompletableFuture<T> completeOnTimeout(
T value, long timeout, TimeUnit unit)](https://image.slidesharecdn.com/streamprocessingwithcompletablefutureandflow-170612131238/85/Stream-Processing-with-CompletableFuture-and-Flow-in-Java-9-62-320.jpg)






This document discusses asynchronous data stream processing in Java 9, focusing on CompletableFuture and reactive programming patterns. It covers various aspects of stream processing, including hot and cold event streams, along with examples and design patterns. The content emphasizes the use of reactive streams and the benefits of non-blocking, high-performance applications in modern programming architectures.



































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)









