More Related Content

PDF
CMSI計算科学技術特論B(15) インテル Xeon Phi コプロセッサー向け最適化、並列化概要 1 
PDF

PPTX

PDF

PPT
Android™組込み開発基礎コース BeagleBoard編 
PDF
RFC6243(With-defaults Capability for NETCONF)の勉強資料 
PDF
RFC6241(Network Configuration Protocol (NETCONF))の勉強資料 
PDF
What's hot

PDF

PPTX
あなたのAppleにもEFIモンスターはいませんか? by Pedro Vilaça - CODE BLUE 2015 
PDF
RFC5277(NETCONF Event Notifications)の勉強資料 
PDF
第15回「インテル® Xeon® プロセッサー E5 ファミリー 新登場!」(2012/03/22 on しすなま!) Iintel様資料 
PDF
第10回「高信頼性仮想化ソフトウェア「Avance™」」(2011/10/27 on しすなま!) ![[db tech showcase Tokyo 2016] A35: NVMe徹底検証 by 株式会社インサイトテクノロジー 平間 大輔](https://cdn.slidesharecdn.com/ss_thumbnails/duwstkmftmk1ljzvasyo-signature-894dfd7b74ecb9b4108868bb00c4d449f11835b4a29fd9720063bbf078c9ab25-poli-160721065555-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db tech showcase Tokyo 2016] A35: NVMe徹底検証 by 株式会社インサイトテクノロジー 平間 大輔 
PDF
PCCC21:日本オラクル株式会社 「Oracle Cloud Infrastructure for HPC&AI」 
PDF

PDF
Lpicl304Seminar Presentations on 20150118 
PDF
ネットワークスイッチ構築実践 2.STP・RSTP・PortSecurity・StormControl・SPAN・Stacking編 
PPTX
20160619_LPICl304 技術解説セミナー in AP浜松町 
PDF
SFC デザイン言語WS(電子工作)第6回「PCとの連携・音」 
PDF

PPTX
20151114 _html5無料セミナー(OSC2015徳島) 
PDF

PDF

PDF

PDF
Android組み込み開発テキスト pandaboard es編 
PDF
Ansible troubleshooting 101_202007 
PDF
Ansible automationplatform product updates 2021 Viewers also liked

PDF

PDF

PDF
LLDN / キミならどう書く Haskell 編 (自由演技) 
PDF

PDF

PDF
Intel TSX HLE を触ってみた x86opti 
PDF

PDF

KEY
Haskell Day2012 - 参照透過性とは何だったのか 
PDF

PDF

PDF
Xeon PhiとN体計算コーディング x86/x64最適化勉強会6(@k_nitadoriさんの代理アップ) 
PDF

PPTX
PFIセミナーH271022 ~コマンドを叩いて遊ぶ コンテナ仮想、その裏側~ 
PPT

PDF

PPT

PDF
Deep Learning in real world @Deep Learning Tokyo 
PDF
Boost.勉強会#19東京 Effective Modern C++とC++ Core Guidelines 
PDF
Similar to CMSI計算科学技術特論B(15) インテル Xeon Phi コプロセッサー向け最適化、並列化概要 2

PDF
Adaptive optimization of JIT compiler 
PDF

PDF
第11回ACRiウェビナー_インテル/竹村様ご講演資料 
PDF
PCCC22:インテル株式会社 テーマ1「インテル® Agilex™ FPGA デバイス 最新情報」 
PDF
ITPro Expo 2014: 仮想デスクトップ基盤を支える Cisco Unified Computing System 
PPTX
Dbts2012 unconference wttrw_yazekatsu_publish 
PDF

PPTX
20200709 fjt7tdmi-blog-appendix 
PDF
PCCC22:インテル株式会社 テーマ3「インテル® oneAPI ツールキット 最新情報のご紹介」 ![[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理 
PPTX
TechEd2008_T1-407_EffectiveHyper-V 
PDF

PDF
ITpro EXPO 2014: Cisco UCSによる最新VDIソリューションのご紹介 
PDF

PDF

PPTX
Windows Server 2012 で管理をもっと自動化する 
PDF
OpenJDK HotSpot C1Compiler Overview 
PDF
2012-04-25 ASPLOS2012出張報告(公開版) 
PDF
ITPro Expo 2014: IT インフラ 管理ソリューション ~ Cisco UCS Director と UCS Performance Man... 
PDF
CLRの基礎 - プログラミング .NET Framework 第3版 読書会 More from Computational Materials Science Initiative

PDF

PDF
How to setup MateriApps LIVE! 
PDF
How to setup MateriApps LIVE! 
PDF

PDF

PDF
How to setup MateriApps LIVE! 
PDF
How to setup MateriApps LIVE! 
PDF

PDF

PDF
How to setup MateriApps LIVE! 
PDF
How to setup MateriApps LIVE! 
PDF

PDF
How to setup MateriApps LIVE! 
PDF

PDF

PDF
How to setup MateriApps LIVE! 
PDF

PDF
MateriApps: OpenMXを利用した第一原理計算の簡単な実習 
PDF
CMSI計算科学技術特論C (2015) ALPS と量子多体問題② 
PDF
CMSI計算科学技術特論C (2015) ALPS と量子多体問題① CMSI計算科学技術特論B(15) インテル Xeon Phi コプロセッサー向け最適化、並列化概要 2
- 1.
- 2.
- 3.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
インテル® ソフトウェア開発製品
3
Advanced Performance Distributed Performance
C++ および Fortran コンパイラー
インテル® MKL/インテル® IPP ライブラリー
と解析ツール
IA ベース・マルチコア・ノード上の
Windows* および Linux* 開発者向け
MPI クラスターツールと C++ および Fortran
コンパイラー、インテル® MKL/インテル® IPP
ライブラリーと解析ツール
IA ベースのクラスター上の Windows* および
Linux* 開発者向け
+
- 4.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
インテル® Paralel Studio XE 2013
インテル® Advisor XE
インテル® C++ コンパイラー
インテル® Fortran コンパイラー
インテル® MKL
インテル® IPP
インテル® TBB
インテル® Inspector XE
インテル® VTune ™ Amplifier XE
インテル® ソフトウェア開発製品
(インテル Xeon ® Phi™ コプロセッサー対応ツール)
4
詳細は各製品のリリースノートやドキュメント等をご参照ください
インテル® Cluster Studio XE 2013
インテル® Advisor XE
インテル® C++ コンパイラー
インテル® Fortran コンパイラー
インテル® MKL
インテル® IPP
インテル® TBB
インテル® Inspector XE
インテル® VTune ™ Amplifier XE
インテル® MPI ライブラリー
インテル® Trace Analyzer/Collector
- 5.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
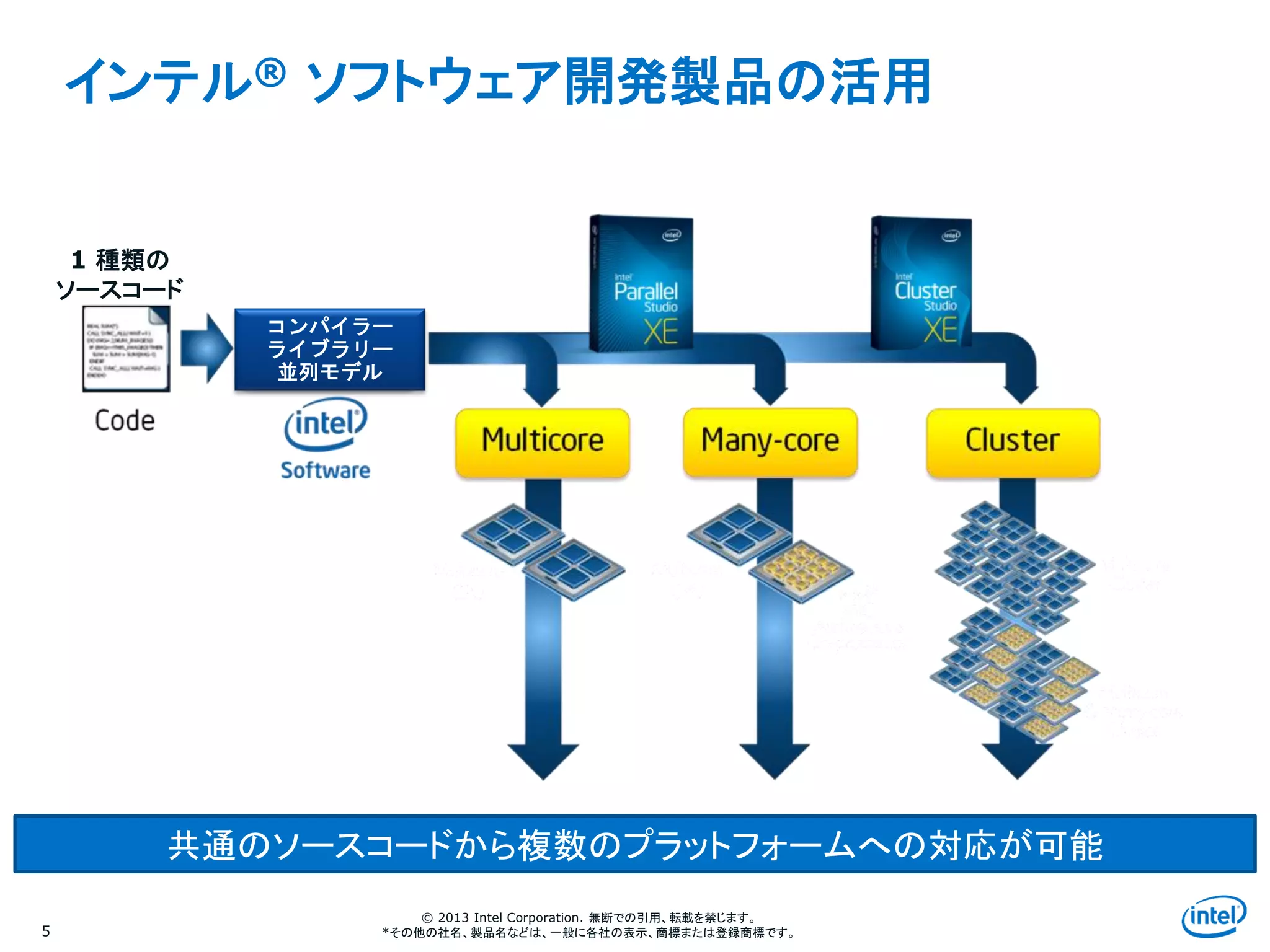
インテル® ソフトウェア開発製品の活用
5
For illustration only, potential future options subject to change without notice.
コンパイラー
ライブラリー
並列モデル
1 種類の
ソースコード
共通のソースコードから複数のプラットフォームへの対応が可能
- 6.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。6
インテル® Composer XE
ヘテロジニアス・コンパイルを提供するインテル® コンパイラー
インテル® MIC 対応数値演算ライブラリー(MKL)
インテル® MIC 対応インテル® デバッガー
並列化モデル言語拡張およびライブラリー
インテル® Composer XE でサポートする並列化モデル
IPP †
その他
CEAN OpenMP*
OpenCL*MKL
ライブラリー
Cilk
Cilk 配列表記
インテル® Cilk™ Plus
要素関数
SIMD
プラグマ
インテル® TBB
並列プログラミング・モデル
† ノート:インテル® IPP は現在インテル® Xeon PhiTM コプロセッサー非対応
- 7.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
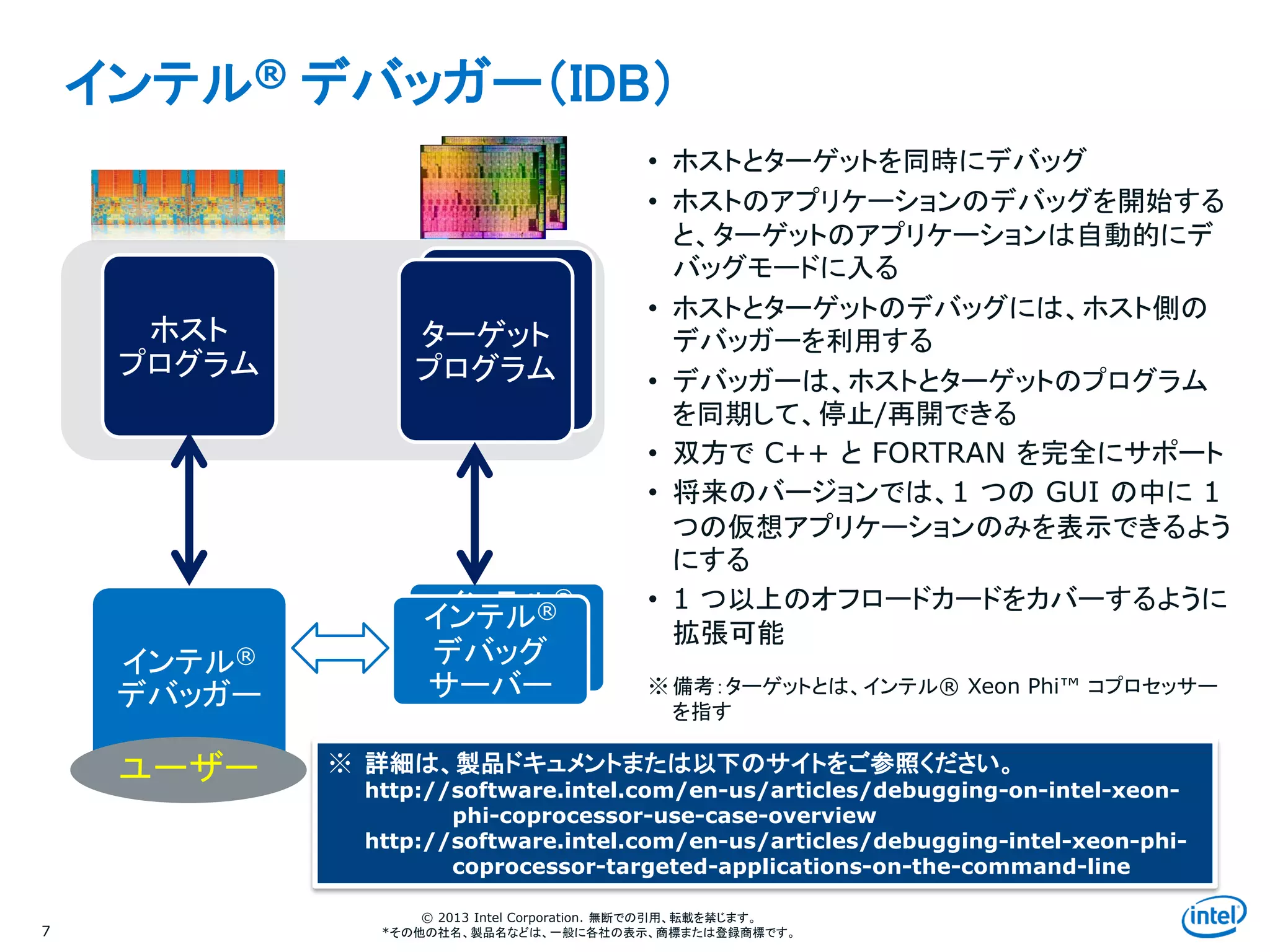
インテル® デバッガー(IDB)
7
インテル®
Debug
サーバー
Target
Program
• ホストとターゲットを同時にデバッグ
• ホストのアプリケーションのデバッグを開始する
と、ターゲットのアプリケーションは自動的にデ
バッグモードに入る
• ホストとターゲットのデバッグには、ホスト側の
デバッガーを利用する
• デバッガーは、ホストとターゲットのプログラム
を同期して、停止/再開できる
• 双方で C++ と FORTRAN を完全にサポート
• 将来のバージョンでは、1 つの GUI の中に 1
つの仮想アプリケーションのみを表示できるよう
にする
• 1 つ以上のオフロードカードをカバーするように
拡張可能
ホスト
プログラム
ターゲット
プログラム
インテル®
デバッガー
インテル®
デバッグ
サーバー
ユーザー
※ 備考:ターゲットとは、インテル® Xeon Phi™ コプロセッサー
を指す
※ 詳細は、製品ドキュメントまたは以下のサイトをご参照ください。
http://software.intel.com/en-us/articles/debugging-on-intel-xeon-
phi-coprocessor-use-case-overview
http://software.intel.com/en-us/articles/debugging-intel-xeon-phi-
coprocessor-targeted-applications-on-the-command-line
- 8.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
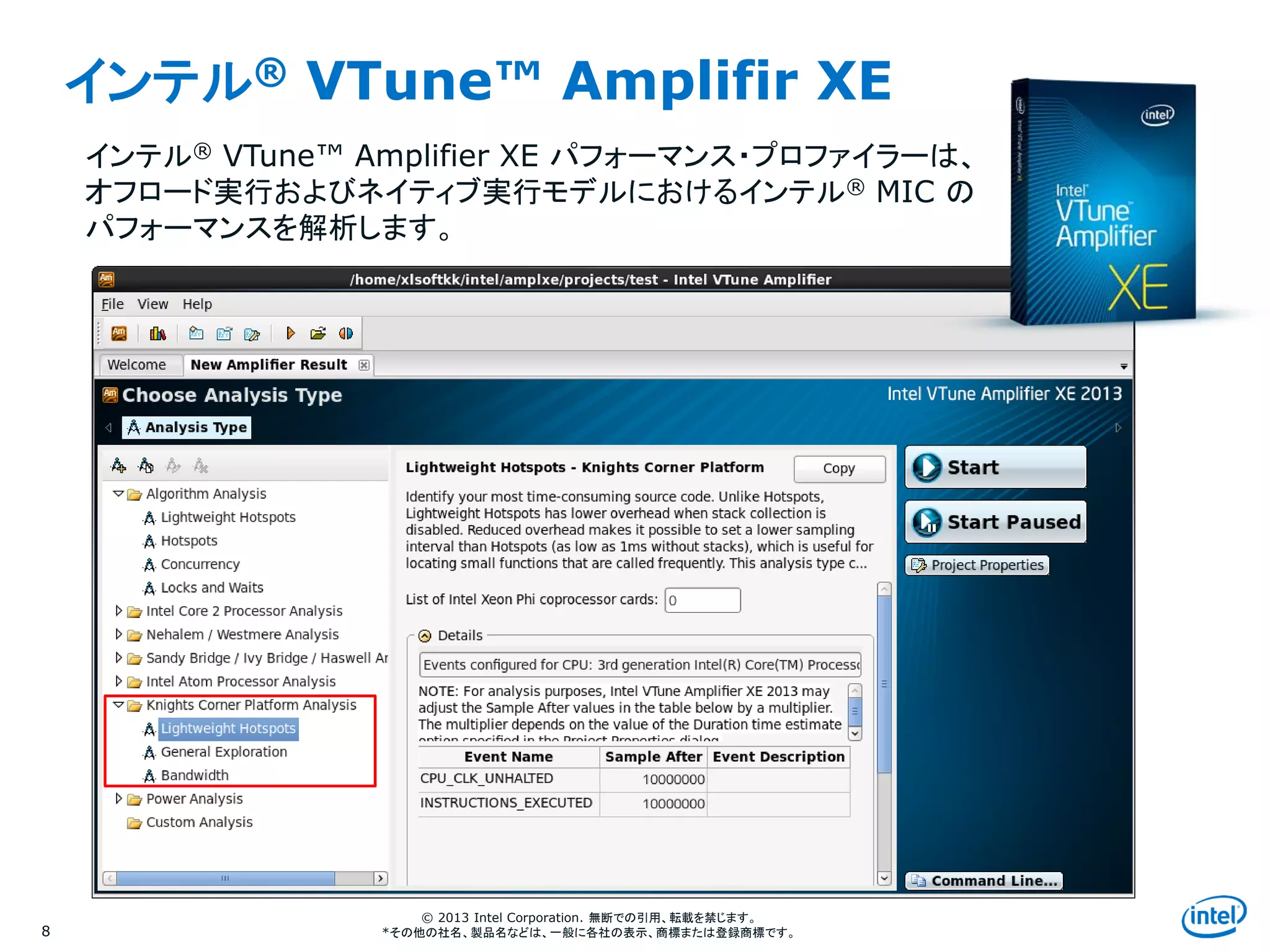
インテル® VTune™ Amplifir XE
8
インテル® VTune™ Amplifier XE パフォーマンス・プロファイラーは、
オフロード実行およびネイティブ実行モデルにおけるインテル® MIC の
パフォーマンスを解析します。
- 9.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
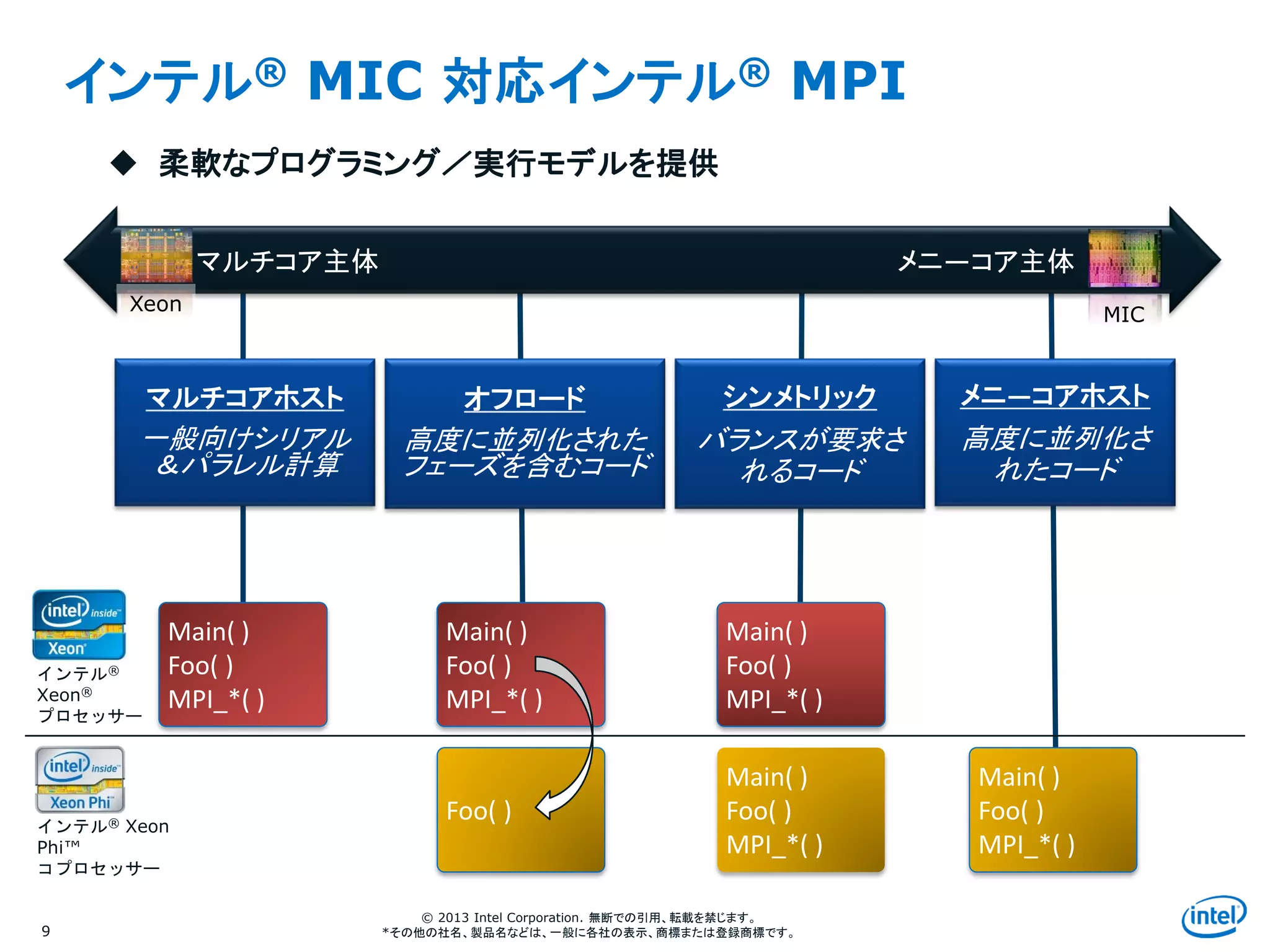
インテル® MIC 対応インテル® MPI
9
Foo( )
Main( )
Foo( )
MPI_*( )
Main( )
Foo( )
MPI_*( )
Main( )
Foo( )
MPI_*( )
Main( )
Foo( )
MPI_*( )
Main( )
Foo( )
MPI_*( )
マルチコア主体 メニ―コア主体
マルチコアホスト
一般向けシリアル
&パラレル計算
メニ―コアホスト
高度に並列化さ
れたコード
シンメトリック
バランスが要求さ
れるコード
Xeon
MIC
インテル® Xeon
Phi™
コプロセッサー
インテル®
Xeon®
プロセッサー
オフロード
高度に並列化された
フェーズを含むコード
柔軟なプログラミング/実行モデルを提供
- 10.
- 11.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
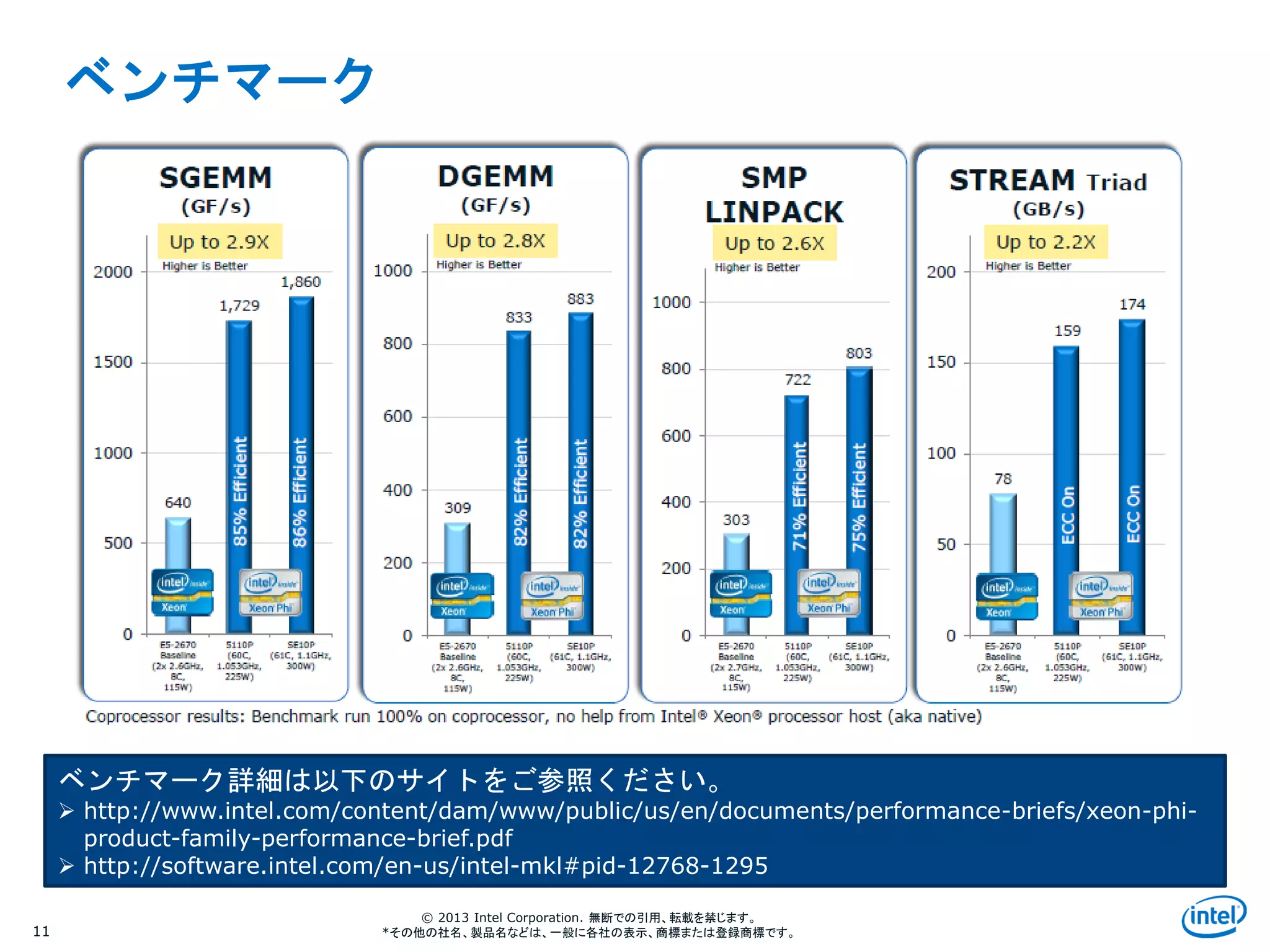
ベンチマーク
11
ベンチマーク詳細は以下のサイトをご参照ください。
http://www.intel.com/content/dam/www/public/us/en/documents/performance-briefs/xeon-phi-
product-family-performance-brief.pdf
http://software.intel.com/en-us/intel-mkl#pid-12768-1295
- 12.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
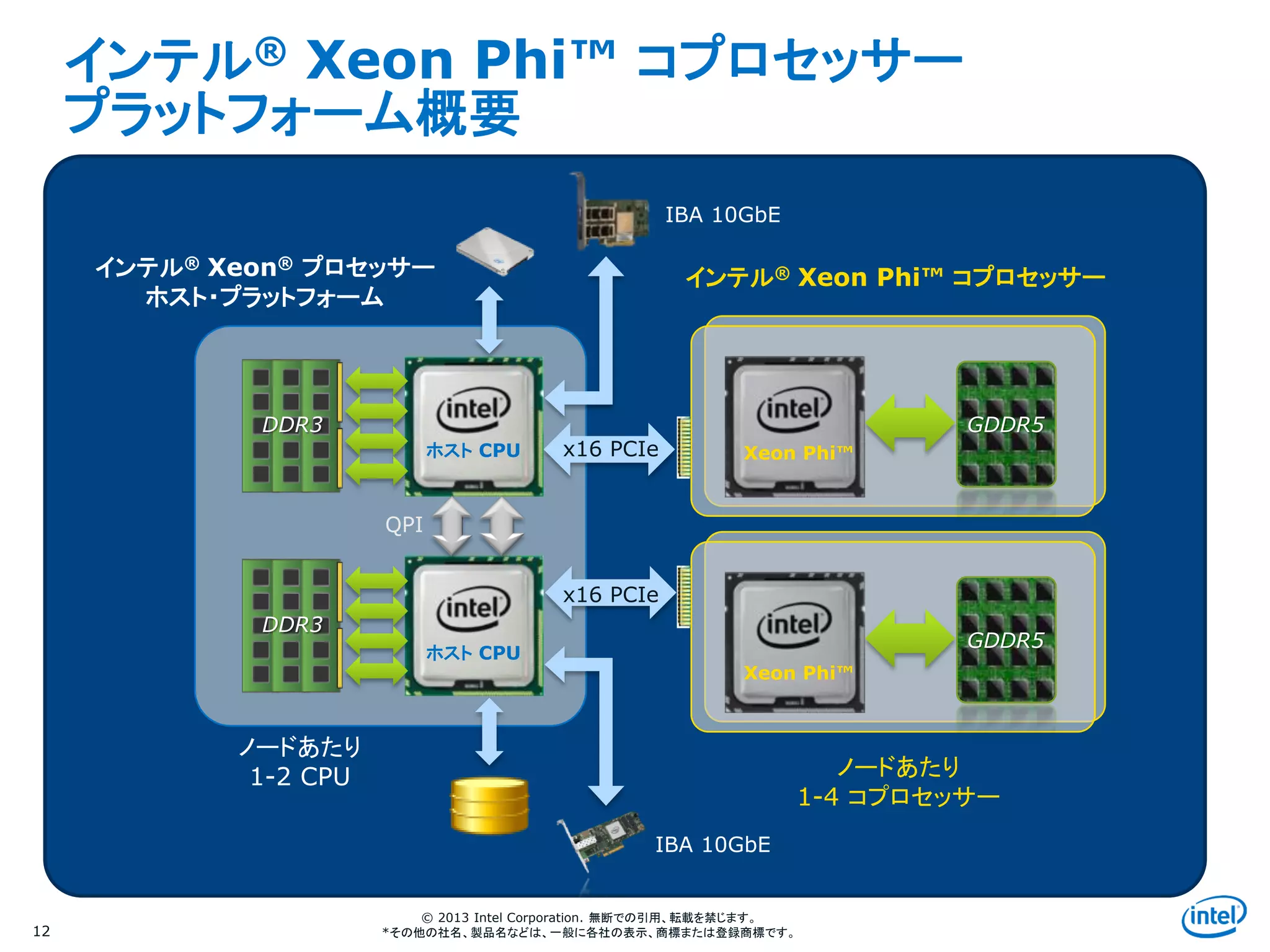
インテル® Xeon Phi™ コプロセッサー
プラットフォーム概要
12
ホスト CPU
インテル® Xeon® プロセッサー
ホスト・プラットフォーム
QPI
x16 PCIe Xeon Phi™
インテル® Xeon Phi™ コプロセッサー
GDDR5
IBA 10GbE
IBA 10GbE
ノードあたり
1-4 コプロセッサー
ノードあたり
1-2 CPU
DDR3
DDR3
GDDR5
x16 PCIe
ホスト CPU
Xeon Phi™
- 13.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。13
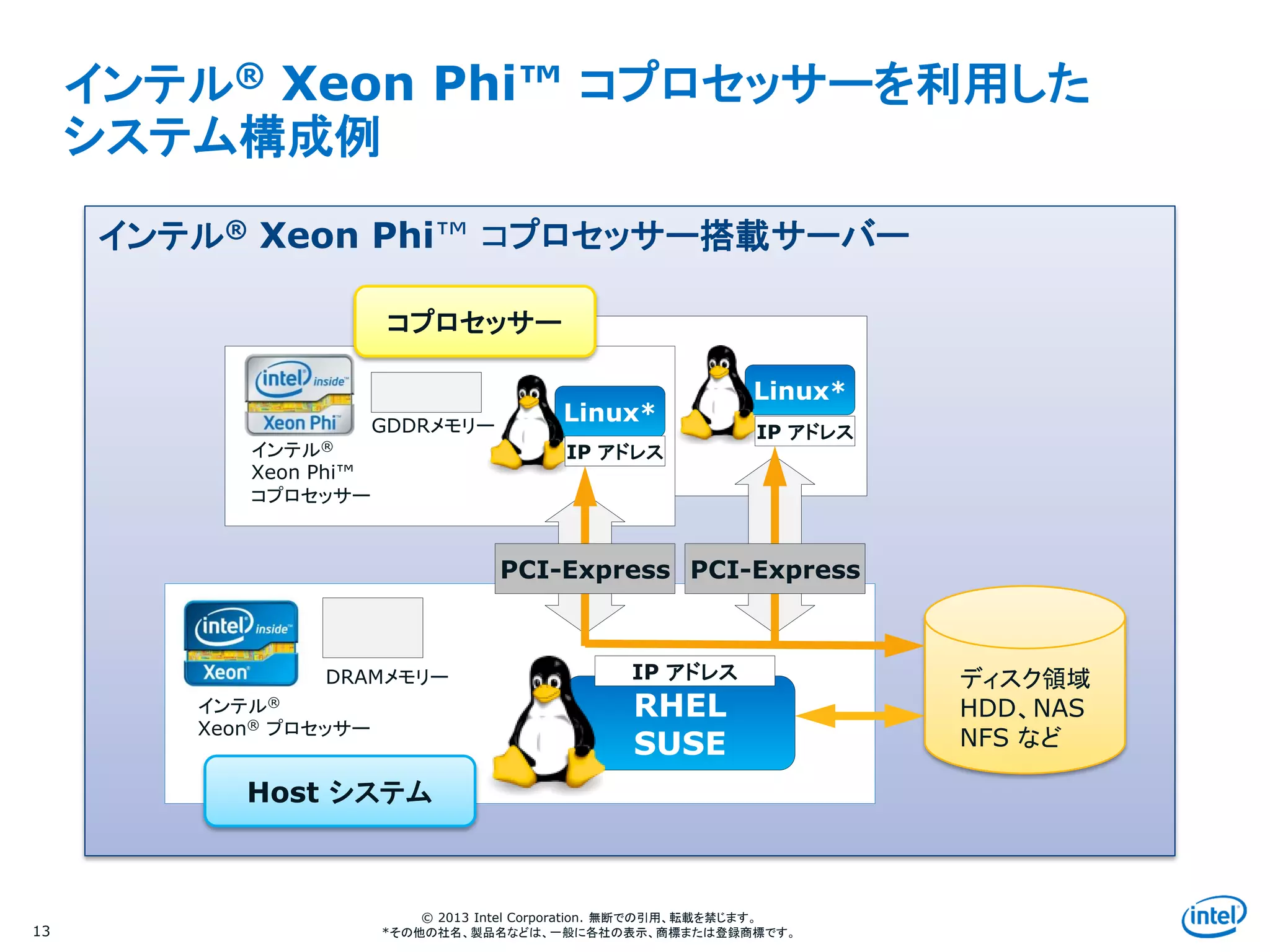
インテル® Xeon Phi™ コプロセッサーを利用した
システム構成例
インテル®
Xeon® プロセッサー
インテル®
Xeon Phi™
コプロセッサー
GDDRメモリー
DRAMメモリー
インテル® Xeon Phi™ コプロセッサー搭載サーバー
RHEL
SUSE
Linux*
Linux*
IP アドレス
IP アドレス
ディスク領域
HDD、NAS
NFS など
コプロセッサー
Host システム
PCI-Express PCI-Express
IP アドレス
- 14.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
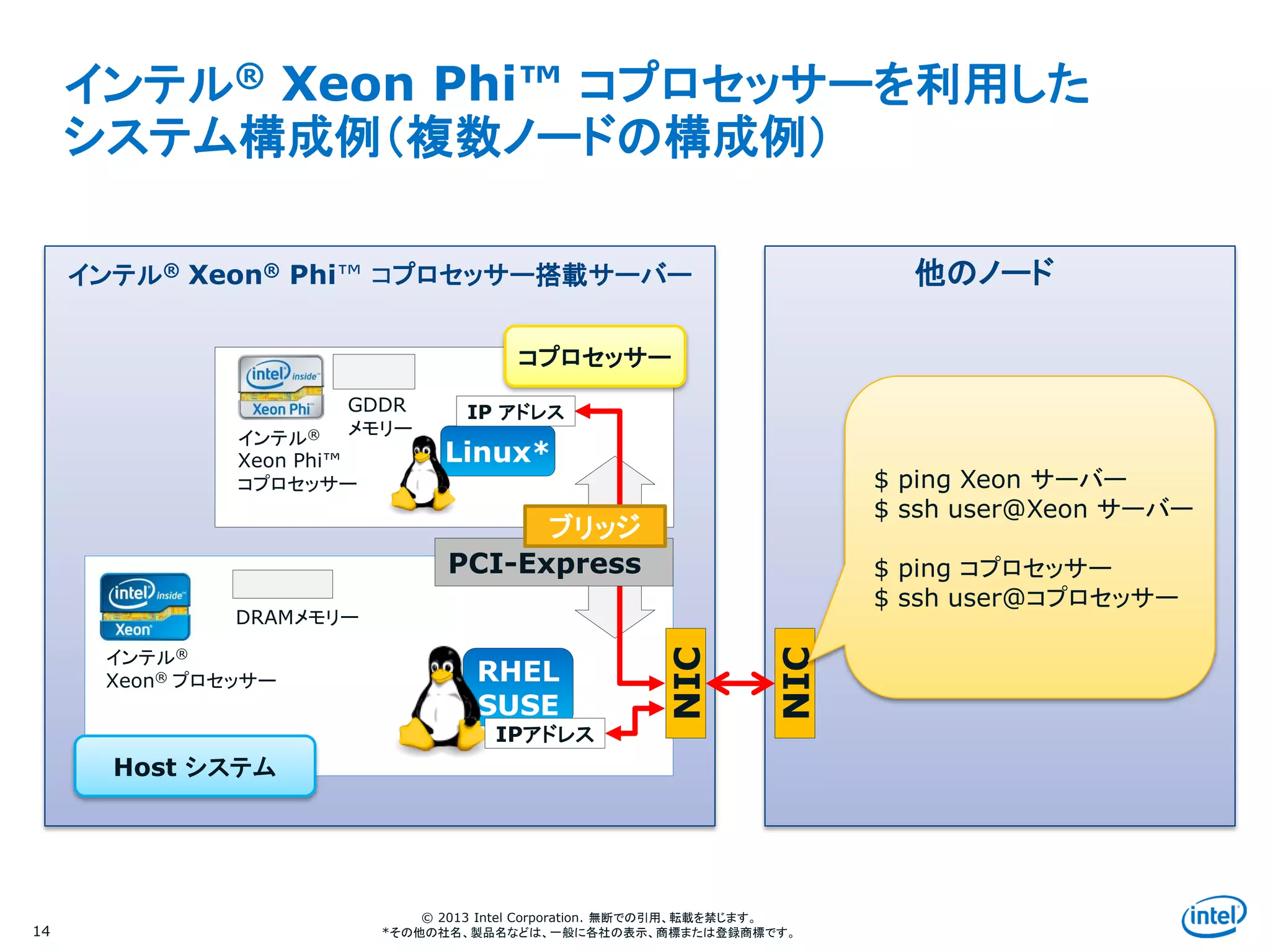
インテル® Xeon Phi™ コプロセッサーを利用した
システム構成例(複数ノードの構成例)
14
インテル®
Xeon® プロセッサー
インテル®
Xeon Phi™
コプロセッサー
GDDR
メモリー
DRAMメモリー
RHEL
SUSE
Linux*
IPアドレス
IP アドレス
NIC
NIC
他のノード
$ ping Xeon サーバー
$ ssh user@Xeon サーバー
$ ping コプロセッサー
$ ssh user@コプロセッサー
インテル® Xeon® Phi™ コプロセッサー搭載サーバー
コプロセッサー
Host システム
PCI-Express
ブリッジ
- 15.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
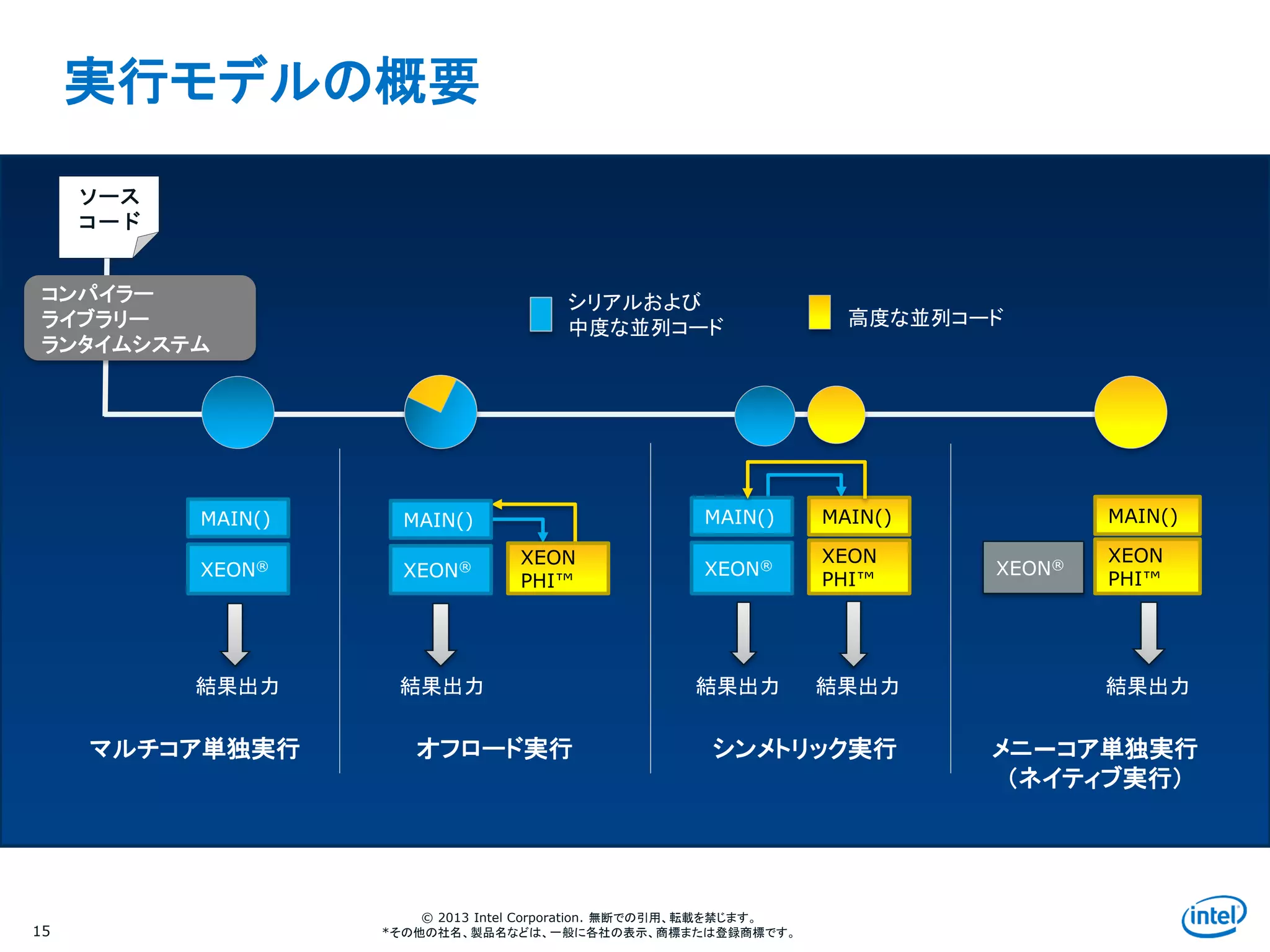
実行モデルの概要
15
MAIN()
XEON®
結果出力
MAIN()
XEON®
XEON
PHI™
MAIN()
XEON®
XEON
PHI™
MAIN()
XEON®
XEON
PHI™
MAIN()
コンパイラー
ライブラリー
ランタイムシステム
マルチコア単独実行
シリアルおよび
中度な並列コード 高度な並列コード
結果出力 結果出力 結果出力 結果出力
オフロード実行 シンメトリック実行 メニ―コア単独実行
(ネイティブ実行)
ソース
コード
- 16.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。16
ヘテロジニアス・プログラミングについて
~はじめに~
• CPU とコプロセッサーの命令セットは似ていますが同一ではありません。
• CPU とコプロセッサーはメインメモリーを共有しません。
「オフロード実行」と「ネイティブ実行」
オフロード実行:プログラムの特定の処理をインテル® Xeon Phi™
コプロセッサーにオフロードして実行するモデル
ネイティブ実行:インテル® Xeon Phi™ コプロセッサー上でのみ
プログラムを実行させるモデル
インテル® コンパイラーは、
CPU とコプロセッサー両方のバイナリーを生成することができます。
オフロード実行用プログラムを記述するための言語拡張が提供されます。
- 17.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
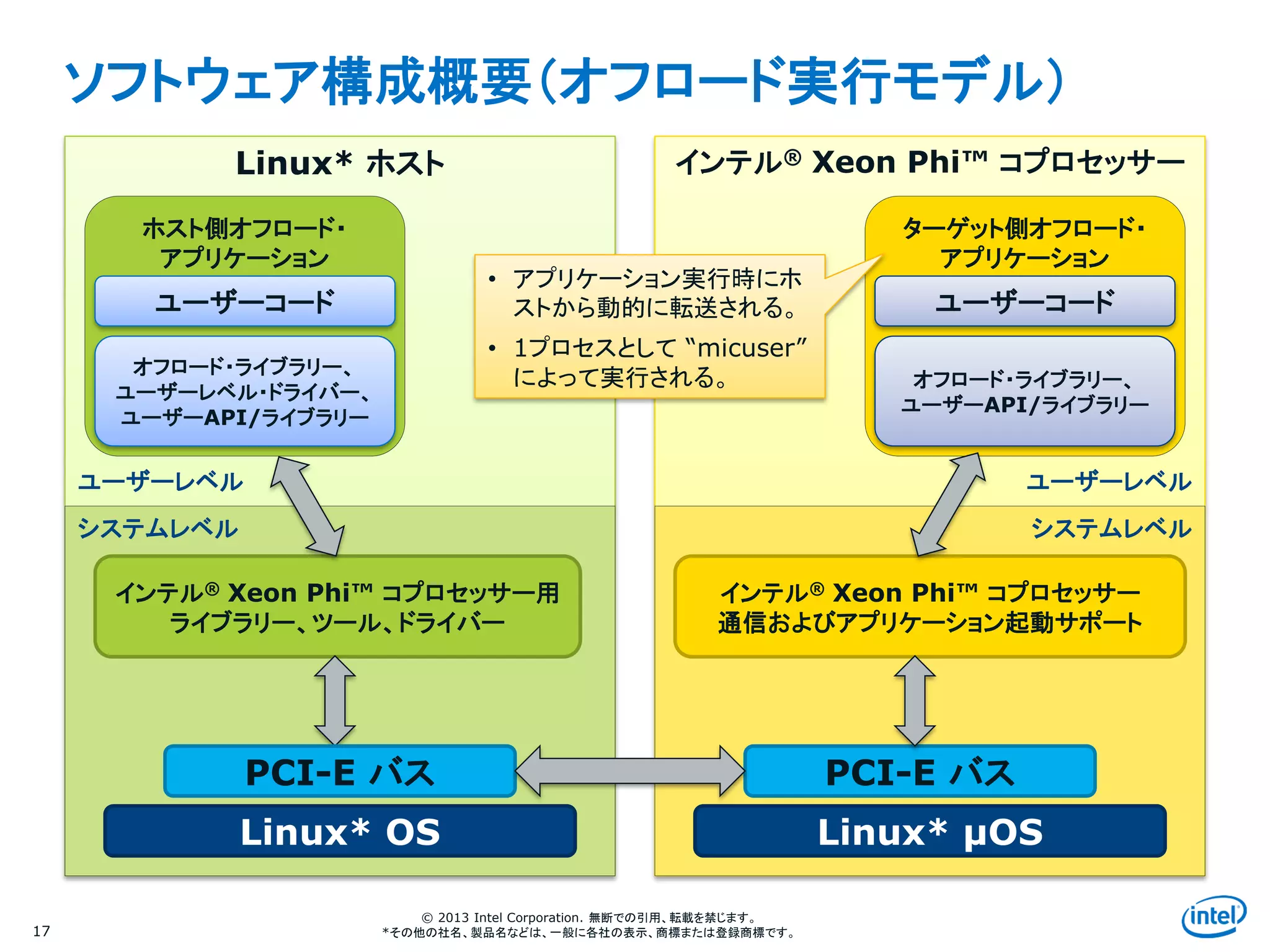
ソフトウェア構成概要(オフロード実行モデル)
17
Linux* ホスト インテル® Xeon Phi™ コプロセッサー
インテル® Xeon Phi™ コプロセッサー用
ライブラリー、ツール、ドライバー
システムレベル
ユーザーレベル
PCI-E バス
Linux* OS Linux* μOS
PCI-E バス
インテル® Xeon Phi™ コプロセッサー
通信およびアプリケーション起動サポート
システムレベル
ユーザーレベル
ホスト側オフロード・
アプリケーション
ユーザーコード
オフロード・ライブラリー、
ユーザーレベル・ドライバー、
ユーザーAPI/ライブラリー
ターゲット側オフロード・
アプリケーション
ユーザーコード
オフロード・ライブラリー、
ユーザーAPI/ライブラリー
• アプリケーション実行時にホ
ストから動的に転送される。
• 1プロセスとして “micuser”
によって実行される。
- 18.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
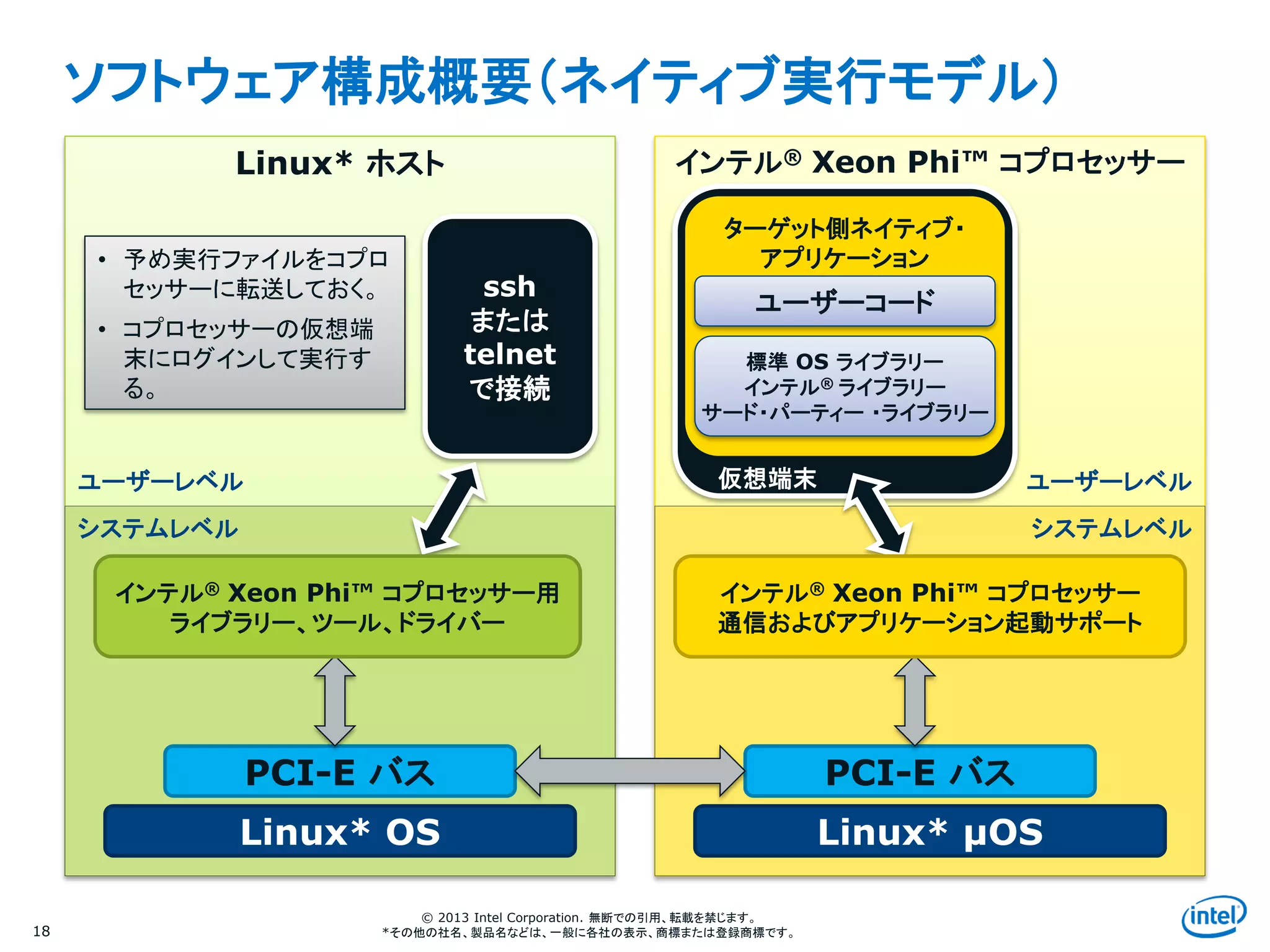
ソフトウェア構成概要(ネイティブ実行モデル)
18
Linux* ホスト インテル® Xeon Phi™ コプロセッサー
システムレベル
ユーザーレベル
PCI-E バス
Linux* OS Linux* μOS
PCI-E バス
システムレベル
ユーザーレベル
ssh
または
telnet
で接続
ターゲット側ネイティブ・
アプリケーション
ユーザーコード
標準 OS ライブラリー
インテル® ライブラリー
サード・パーティー ・ライブラリー
仮想端末
インテル® Xeon Phi™ コプロセッサー用
ライブラリー、ツール、ドライバー
インテル® Xeon Phi™ コプロセッサー
通信およびアプリケーション起動サポート
• 予め実行ファイルをコプロ
セッサーに転送しておく。
• コプロセッサーの仮想端
末にログインして実行す
る。
- 19.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
非共有型オフロードコードの例(PI の計算)
19
#include <stdio.h>
#include <stdlib.h>
#define INTERVALS 1000000000
int main(void)
{
int i;
double x, pi=0.0;
double Step = 1.0 / INTERVALS;
#pragma omp parallel for private(x) reduction(+:pi)
for (i=0; i<INTERVALS; ++i)
{
x = Step * ((double)i-0.5);
pi += 4.0 / (1.0 + x*x);
}
pi = Step * pi;
printf("Pi = %lf¥n", pi);
}
オフロード
セクション
オフロード宣言子の追加#pragma offload target(mic)
- 20.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
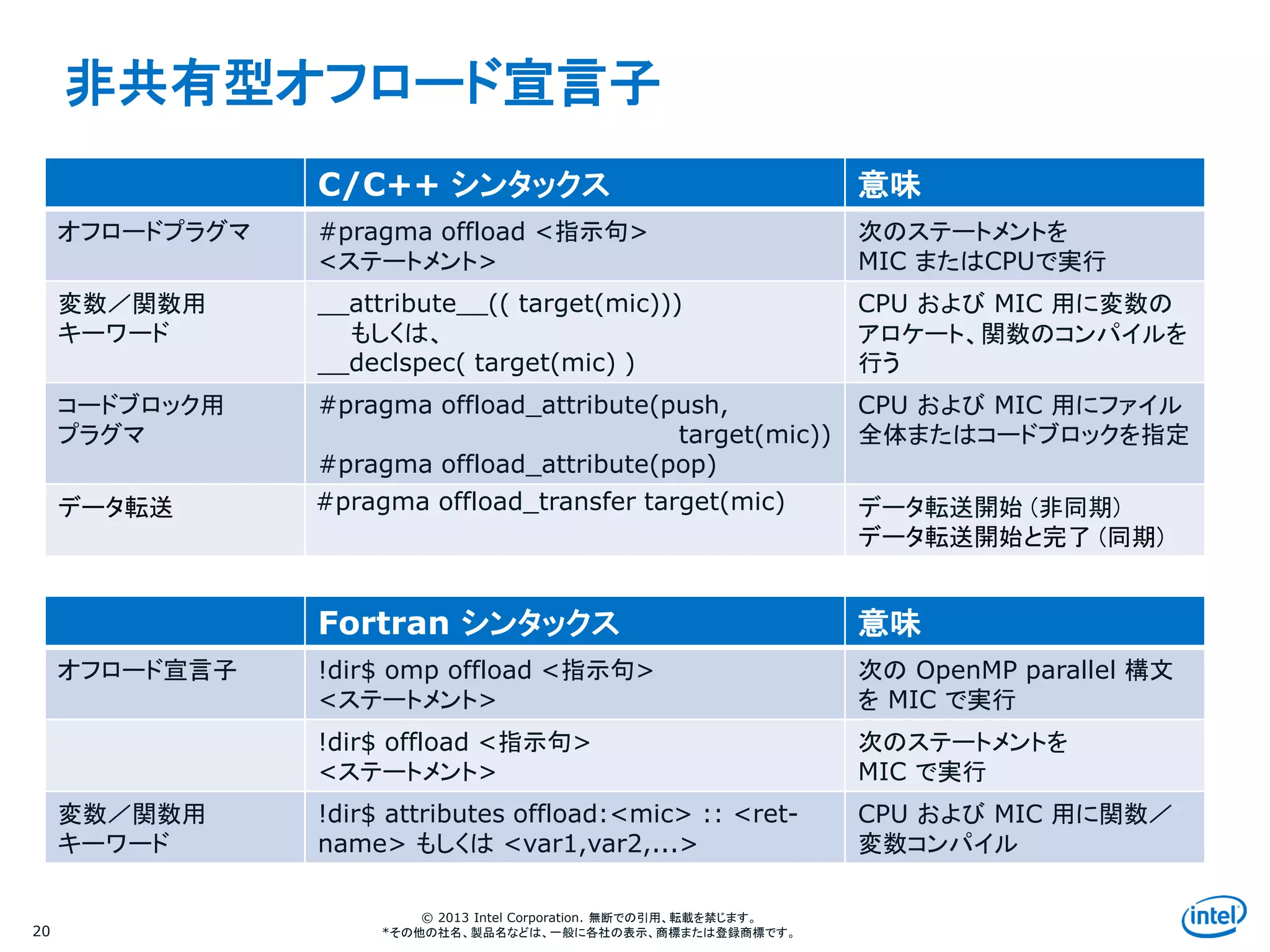
非共有型オフロード宣言子
20
C/C++ シンタックス 意味
オフロードプラグマ #pragma offload <指示句>
<ステートメント>
次のステートメントを
MIC またはCPUで実行
変数/関数用
キーワード
__attribute__(( target(mic)))
もしくは、
__declspec( target(mic) )
CPU および MIC 用に変数の
アロケート、関数のコンパイルを
行う
コードブロック用
プラグマ
#pragma offload_attribute(push,
target(mic))
#pragma offload_attribute(pop)
CPU および MIC 用にファイル
全体またはコードブロックを指定
データ転送 #pragma offload_transfer target(mic) データ転送開始 (非同期)
データ転送開始と完了 (同期)
Fortran シンタックス 意味
オフロード宣言子 !dir$ omp offload <指示句>
<ステートメント>
次の OpenMP parallel 構文
を MIC で実行
!dir$ offload <指示句>
<ステートメント>
次のステートメントを
MIC で実行
変数/関数用
キーワード
!dir$ attributes offload:<mic> :: <ret-
name> もしくは <var1,var2,...>
CPU および MIC 用に関数/
変数コンパイル
- 21.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
非共有型オフロード宣言子(続き)
21
節 シンタックス 意味
ターゲット指定 target(name[:#]) 実行する MIC カードの指定
条件付きオフロード if (condition) Boolean 表現
入力 in (var-list modifiersopt) ホストから MIC へコピー
出力 out (var-list modifiersopt) MIC からホストへコピー
入力および出力 inout (var-list modifiersopt) ホストから MIC へコピーしオフ
ロード後ホストへコピー
コピーしないデータ nocopy (var-list modifiersopt) データは MIC に存在
非同期オフロード signal(signal-slot) 非同期オフロードの開始
非同期オフロード wait(signal-slot) 非同期オフロードの完了待ち
修飾子 シンタックス 意味
ポインター長を指定 length (element-count-expr) 複数のポインター要素をコピー
メモリー割当て制御 alloc_if ( condition ) 条件が真ならメモリー割り当て
メモリー解放制御 free_if ( condition) 条件が真ならメモリー解放
- 22.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
非共有型オフロード修飾子の例
22
float reduction(float *data, int numberOf)
{
float ret = 0.f;
#pragma offload target(mic) in(data:length(numberOf))
{
#pragma omp parallel for reduction(+:ret)
for (int i=0; i < numberOf; ++i)
ret += data[i];
}
return ret;
}
$ source /opt/intel/bin/compilervars.sh intel64
$ icc sample_offload.c –O2 –openmp –o sample_offload
$ ./sample_offload
インテル® コンパイラーによるコンパイルと実行例:
← 環境設定
← コンパイル
← 実行
ノート: “length”修飾子に指定する値は要素
数でありバイト数ではない。
コンパイラーはデータタイプをすでに
知っている。
- 23.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
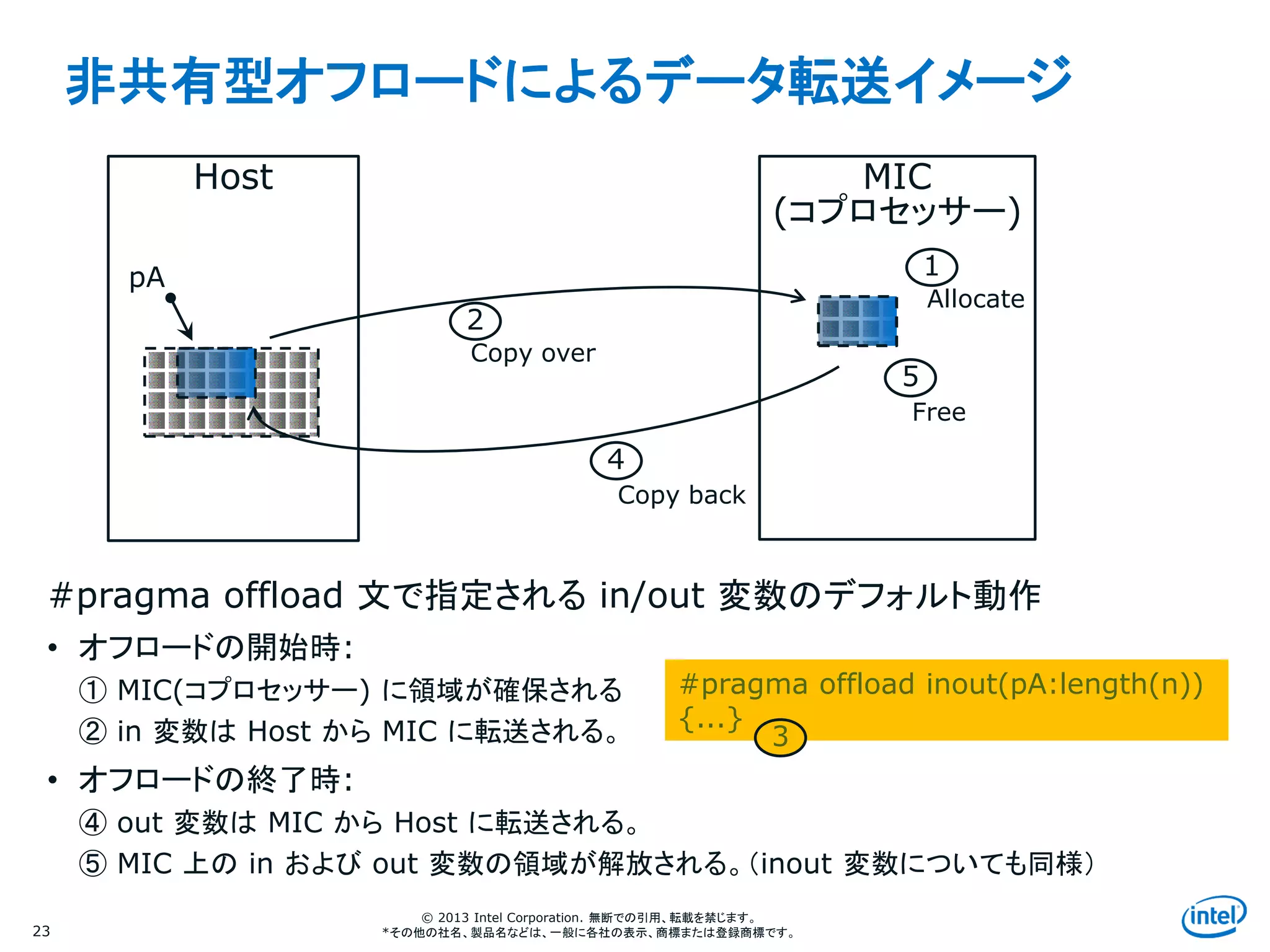
非共有型オフロードによるデータ転送イメージ
23
#pragma offload 文で指定される in/out 変数のデフォルト動作
• オフロードの開始時:
① MIC(コプロセッサー) に領域が確保される
② in 変数は Host から MIC に転送される。
• オフロードの終了時:
④ out 変数は MIC から Host に転送される。
⑤ MIC 上の in および out 変数の領域が解放される。(inout 変数についても同様)
Host MIC
(コプロセッサー)
#pragma offload inout(pA:length(n))
{...}
Allocate
1
Copy back
4
Copy over
2
Free
5
pA
3
- 24.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。24
ネイティブ実行モデルの概要
インテル® Xeon Phi™ コプロセッサー上で直接実行される
モデル
• ホスト上で、コンパイラー・オプション “-mmic” を指定してコンパイルす
る。(既存コードもそのまま再コンパイル)
• コンパイルした実行バイナリー、関連データファイル、必要ランタイム・ラ
イブラリーは scp や ftp でインテル® Xeon Phi™ コプロセッサーに事
前にコピーする必要がある。
• ベクトル化、インテル® MKL、OpenMP*、インテル® TBB、インテル®
Cilk™ Plus、インテル® MPI などが利用可能。
• プログラムは高度に並列化されていることが望まれる。コプロセッサー
上 でのシリアル実行はホスト CPU より遅くなる。
• アプリケーション実行の際、ホストとメモリー量が異なることを考慮する
必要がある。
- 25.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
ネイティブ実行モデルのコンパイル/実行例
25
# source /opt/intel/bin/compilervars.sh intel64
# icc -mmic -openmp pi.c -o pi.out.mic
# scp pi.out.mic root@mic0:
# scp /opt/intel/composerxe/lib/mic/libiomp5.so root@mic0:
# ssh root@mic0
# export LD_LIBRARY_PATH=./
# ./pi.out.mic
コンパイルと実行準備の例:
コプロセッサーへのログインとプログラムの実行例:
※青文字は、NFS (ネットワークファイルシステム) などでファイルを共有し
ていない場合に、実行する必要があるコマンドです。
- 26.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
ネイティブ実行モデルのコンパイル/実行例
( micnativeloadex ツールの利用)
26
$ source /opt/intel/bin/compilervars.sh intel64
$
$ icc -mmic -openmp omp_app.cpp
$
$ export SINK_LD_LIBRARY_PATH=/opt/intel/composerxe/lib/mic
$
$ /opt/intel/mic/bin/micnativeloadex a.out
ノート: SINK_LD_LIBRARY_PATH 環境変数に MIC 用のランタイム・ライブラリーの
ディレクトリーを設定することで、micnativeloadex が自動で必要な依存ライブラ
リーをコプロセッサーにコピーする。
また “micnativeloadex a.out -l” で依存ライブラリーをチェック可能。
“micnativeloadex”ツールでネイティブ実行作業を簡略化できる。
- 27.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。27
float *restrict A, *B, *C;
for(i=0;i<n;i++){
C[i] = A[i] + B[i];
}
1
addss %xmm1, %xmm2
B0
A0+
- 28.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。28
float *restrict A, *B, *C;
for(i=0;i<n;i++){
C[i] = A[i] + B[i];
}
SIMD
(Single Instruction Multiple Data)
1
B3 B2 B1 B0
A3 A2 A1 A0+
•[SSE] float 4
addps %xmm1, %xmm2
•[AVX] float 8
vaddps %ymm1, %ymm2, %ymm3
•[MIC] float 16
vaddps %zmm1, %zmm2, %zmm3
( )
- 29.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。29
スカラー演算とSIMD演算の比較
for (i=0; i<40000; i++)
c[i] = a[i] + b[i];
.B1.2::
movss xmm0, A[rcx+r9*4]
addss xmm0, B[rdx+r9*4]
movss C[r8+r9*4], xmm0
inc r9
cmp r9, 40000
jl .B1.2
スカラー演算
コード例
addss : Scalar Single-FP Add
single precision FP data
scalar execution mode
.B1.2::
vmovups ymm0, A[rcx+r9*4]
vaddps ymm1,ymm0,B[rdx+r9*4]
vmovups C[r8+r9*4], ymm1
add r9, 8
cmp r9, 40000
jb .B1.2
SIMD 演算
コード例(AVX)
vaddps : Packed Single-FP Add
single precision FP data
packed execution mode
8要素ずつ
5,000回の処理
1要素ずつ
40,000回の処理
ループを展開(アンロール)し、パックドSIMD命令を活用して
コードの処理効率を高める最適化技術をベクトル化と呼んでいる
- 30.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。30
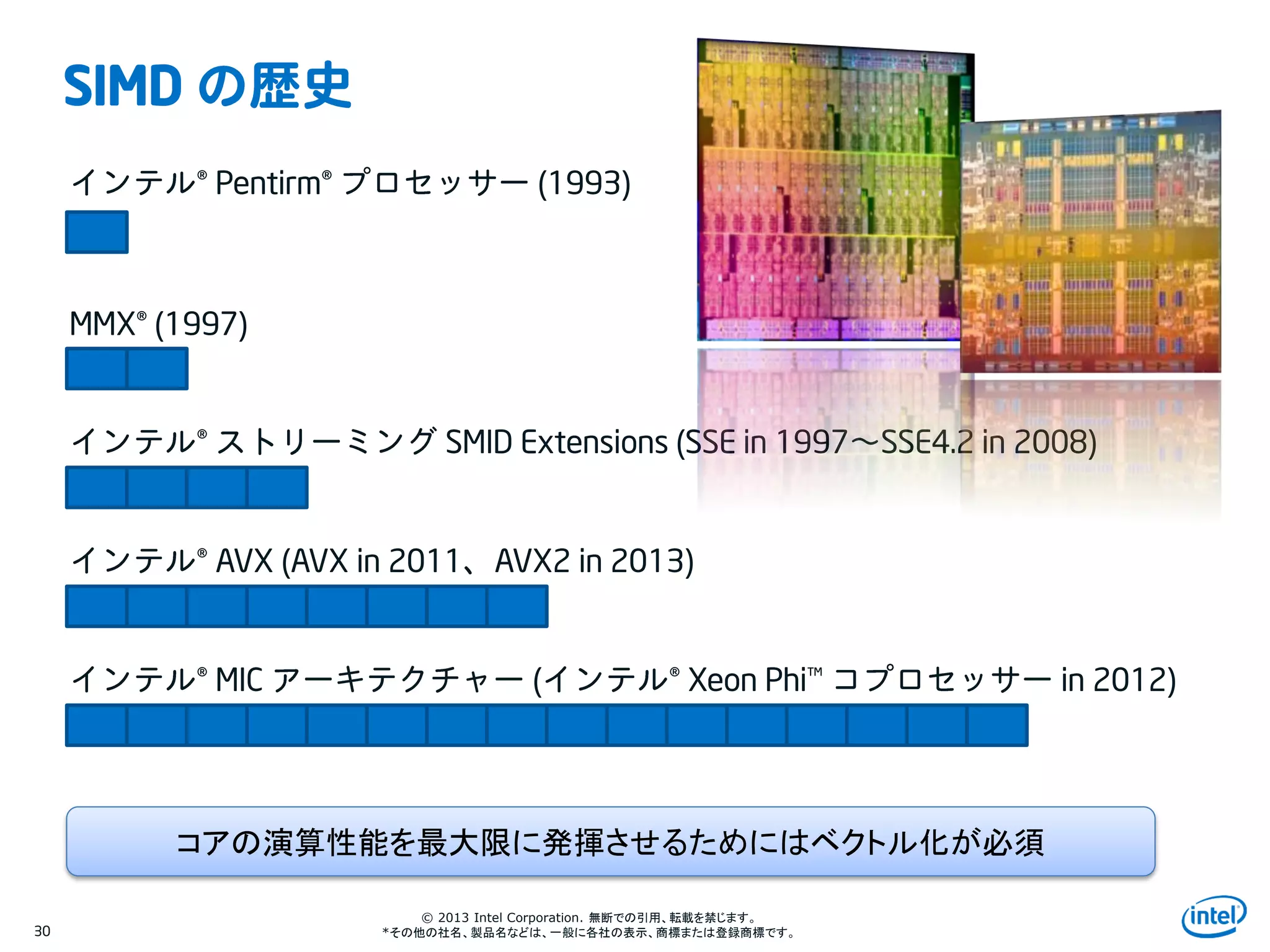
SIMD
® Pentirm® (1993)
® SMID Extensions (SSE in 1997 SSE4.2 in 2008)
MMX® (1997)
® AVX (AVX in 2011 AVX2 in 2013)
® MIC ( ® Xeon Phi™ in 2012)
コアの演算性能を最大限に発揮させるためにはベクトル化が必須
- 31.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。31
-mmic
(-mmic )
® Xeon® E5-2600 +
® Xeon Phi™
$ icc hoge.c -O3 -xAVX
® Xeon Phi™
$ icc hoge.c -O3 -mmic
- 32.
Intel Information Technology
©2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。32
最適化に関する注意事項
インテル® コンパイラーは、互換マイクロプロセッサー向けには、インテル製マイクロプロセッサー向けと同等レベルの最適化が行われない可
能性があります。これには、インテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2)、インテル® ストリーミング SIMD 拡張命令 3
(インテル® SSE3)、ストリーミング SIMD 拡張命令 3 補足命令 (SSSE3) 命令セットに関連する最適化およびその他の最適化が含まれま
す。インテルでは、インテル製ではないマイクロプロセッサーに対して、最適化の提供、機能、効果を保証していません。本製品のマイクロプロ
セッサー固有の最適化は、インテル製マイクロプロセッサーでの使用を目的としています。インテル® マイクロアーキテクチャーに非固有の特
定の最適化は、インテル製マイクロプロセッサー向けに予約されています。この注意事項の適用対象である特定の命令セットの詳細は、該当
する製品のユーザー・リファレンス・ガイドを参照してください。
改訂 #20110804
本資料の情報は、現状のまま提供され、本資料は、明示されているか否かにかかわらず、また禁反言によるとよらずにかか
わらず、いかなる知的財産権のライセンスを許諾するものではありません。製品に付属の売買契約書『Intel‘s Terms and
Conditions of Sale』に規定されている場合を除き、インテルはいかなる責任を負うものではなく、またインテル製品の販売
や使用に関する明示または黙示の保証(特定目的への適合性、商品適確性、あらゆる特許権、著作権、その他知的財産権
の非侵害性への保証を含む)に関してもいかなる責任も負いません。
性能に関するテストや評価は、特定のコンピューター・システム、コンポーネント、またはそれらを組み合わせて行ったもので
あり、このテストによるインテル製品の性能の概算の値を表しているものです。システム・ハードウェアの設計、ソフトウェア、
構成などの違いにより、実際の性能は掲載された性能テストや評価とは異なる場合があります。システムやコンポーネントの
購入を検討される場合は、ほかの情報も参考にして、パフォーマンスを総合的に評価することをお勧めします。インテル製品
の性能評価についてさらに詳しい情報をお知りになりたい場合は、http://www.intel.com/performance/ (英語) を参
照してください。
© 2013 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴ、Intel Xeon Phi、Xeon、
Xeon Inside、Cilk、VTune は、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
商標および最適化に関する注意事項について








![Intel Information Technology
© 2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
非共有型オフロード宣言子(続き)
21
節 シンタックス 意味
ターゲット指定 target(name[:#]) 実行する MIC カードの指定
条件付きオフロード if (condition) Boolean 表現
入力 in (var-list modifiersopt) ホストから MIC へコピー
出力 out (var-list modifiersopt) MIC からホストへコピー
入力および出力 inout (var-list modifiersopt) ホストから MIC へコピーしオフ
ロード後ホストへコピー
コピーしないデータ nocopy (var-list modifiersopt) データは MIC に存在
非同期オフロード signal(signal-slot) 非同期オフロードの開始
非同期オフロード wait(signal-slot) 非同期オフロードの完了待ち
修飾子 シンタックス 意味
ポインター長を指定 length (element-count-expr) 複数のポインター要素をコピー
メモリー割当て制御 alloc_if ( condition ) 条件が真ならメモリー割り当て
メモリー解放制御 free_if ( condition) 条件が真ならメモリー解放](https://image.slidesharecdn.com/15th-0724kurosawa-140723231021-phpapp01/75/CMSI-B-15-Xeon-Phi-2-21-2048.jpg)
![Intel Information Technology
© 2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
非共有型オフロード修飾子の例
22
float reduction(float *data, int numberOf)
{
float ret = 0.f;
#pragma offload target(mic) in(data:length(numberOf))
{
#pragma omp parallel for reduction(+:ret)
for (int i=0; i < numberOf; ++i)
ret += data[i];
}
return ret;
}
$ source /opt/intel/bin/compilervars.sh intel64
$ icc sample_offload.c –O2 –openmp –o sample_offload
$ ./sample_offload
インテル® コンパイラーによるコンパイルと実行例:
← 環境設定
← コンパイル
← 実行
ノート: “length”修飾子に指定する値は要素
数でありバイト数ではない。
コンパイラーはデータタイプをすでに
知っている。](https://image.slidesharecdn.com/15th-0724kurosawa-140723231021-phpapp01/75/CMSI-B-15-Xeon-Phi-2-22-2048.jpg)



![Intel Information Technology
© 2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。27
float *restrict A, *B, *C;
for(i=0;i<n;i++){
C[i] = A[i] + B[i];
}
1
addss %xmm1, %xmm2
B0
A0+](https://image.slidesharecdn.com/15th-0724kurosawa-140723231021-phpapp01/75/CMSI-B-15-Xeon-Phi-2-27-2048.jpg)
![Intel Information Technology
© 2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。28
float *restrict A, *B, *C;
for(i=0;i<n;i++){
C[i] = A[i] + B[i];
}
SIMD
(Single Instruction Multiple Data)
1
B3 B2 B1 B0
A3 A2 A1 A0+
•[SSE] float 4
addps %xmm1, %xmm2
•[AVX] float 8
vaddps %ymm1, %ymm2, %ymm3
•[MIC] float 16
vaddps %zmm1, %zmm2, %zmm3
( )](https://image.slidesharecdn.com/15th-0724kurosawa-140723231021-phpapp01/75/CMSI-B-15-Xeon-Phi-2-28-2048.jpg)
![Intel Information Technology
© 2013 Intel Corporation. 無断での引用、転載を禁じます。
*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。29
スカラー演算とSIMD演算の比較
for (i=0; i<40000; i++)
c[i] = a[i] + b[i];
.B1.2::
movss xmm0, A[rcx+r9*4]
addss xmm0, B[rdx+r9*4]
movss C[r8+r9*4], xmm0
inc r9
cmp r9, 40000
jl .B1.2
スカラー演算
コード例
addss : Scalar Single-FP Add
single precision FP data
scalar execution mode
.B1.2::
vmovups ymm0, A[rcx+r9*4]
vaddps ymm1,ymm0,B[rdx+r9*4]
vmovups C[r8+r9*4], ymm1
add r9, 8
cmp r9, 40000
jb .B1.2
SIMD 演算
コード例(AVX)
vaddps : Packed Single-FP Add
single precision FP data
packed execution mode
8要素ずつ
5,000回の処理
1要素ずつ
40,000回の処理
ループを展開(アンロール)し、パックドSIMD命令を活用して
コードの処理効率を高める最適化技術をベクトル化と呼んでいる](https://image.slidesharecdn.com/15th-0724kurosawa-140723231021-phpapp01/75/CMSI-B-15-Xeon-Phi-2-29-2048.jpg)