ASPLOS 2012概要(1)
The 17th International Conference on Architectural Support for
Programming Languages and Operating Systems
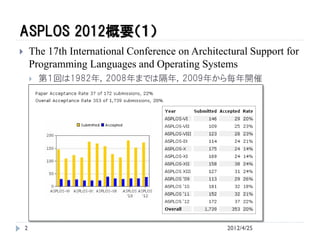
第1回は1982年,2008年までは隔年,2009年から毎年開催
2 2012/4/25
紹介論文
Data Center / Cloud Computing
(Best Paper) Clearing the Clouds: A Study of Emerging
Workloads on Modern Hardware
OS / Fault Tolerance
Understanding Modern Device Drivers
Cosmic Rays Don't Strike Twice: Understanding the Nature
of DRAM Errors and the Implications for System Design
Virtualization
ELI: Bare-metal Performance for I/O Virtualization
Architectural Support for Hypervisor-secure Virtualization
6 2012/4/25
7.
(Best Paper) Clearingthe Clouds:
A Study of Emerging Workloads on Modern Hardware.
背景: クラウド・データセンターでの電力効率問題
Compute density / power consumption の向上が必要
問題: scale-out 負荷ではプロセッサの電力効率が低い
Scale-up 負荷を想定した設計
アウトオブオーダ実行,深いキャッシュ階層
内容:scale-out 負荷でのアーキテクチャ的問題を分析
Scale-out 性能を測定する「CloudSuite」ベンチマークを導入
Data Serving, MapReduce, Media Streaming, SAT Solver, Web Frontend, Web
Search
従来の scale-up 負荷と比較
PARSEC, SPECint, SPECweb09, TPC-C, TPC-E, Web Backend
現状のプロセッサの問題点を4点指摘,今後もその傾向は継続
命令キャッシュのサイズ,命令・メモリ並列性,データワーキングセット,チップ内・
チップ間通信帯域
7 2012/4/25
Cosmic Rays Don'tStrike Twice: Understanding the
Nature of DRAM Errors and the Implications for System Design
背景: DRAMエラーはデータセンターでの主要な障害要因
Soft-error には ECC による SEC-DED が有効
α線や宇宙線などによる一時的エラー
Hard-error には page retirement が有効
Solaris は壊れたページを特定して使用不可にする
問題: soft-errorの頻度>hard-errorの頻度は本当か?
発生頻度は桁が違うと言われている
多くの研究はsoft-errorを対象としている
実際にそれを裏付ける大規模な field work は存在しない
内容: 実システムにおける大規模なDRAMエラーの分析
IBM Blue Gene/L, Blue Gene/P, SciNet のスパコン・クラスタ,
Googleデータセンタからランダムに選択した20,000台のマシン
総計300テラバイト・年のメモリを調査
11 2012/4/25
12.
Cosmic Rays Don'tStrike Twice: Understanding the
Nature of DRAM Errors and the Implications for System Design
方法: アプリケーションで繰り返しメモリアクセス
同一カ所の繰り返しエラーをhardと識別
同じ場所に2度cosmic rayが来る可能性は極めて低い
結果:
エラーが発生したメモリバンクの3分の1以上がhard errorの兆候
2週間以内に同じ物理アドレスでエラーが発生
あるシステムでは95%以上がhard error
領域によってエラー発生率に偏りがある(特定のrow/column)
OSが酷使する領域はエラーが起きやすい傾向にある
より複雑なエラーには前兆がある場合が多い
Multi-bit errorsやchipkillの前に特定箇所に繰り返しエラー発生
ECCによるSEC-DEDでは解決できないエラーも多発
20%~45%のreduandant bit-steering, 15%のchipkill
12 2012/4/25






































![[CB19] Semzhu-Project – 手で作る組込み向けハイパーバイザと攻撃検知手法の新しい世界 by 朱義文](https://cdn.slidesharecdn.com/ss_thumbnails/semzhu-projectcodeblue2019ja-191211063913-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する](https://cdn.slidesharecdn.com/ss_thumbnails/31ddbjingohta-150626022623-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)





















